
Heim >Datenbank >MySQL-Tutorial >Was sind Clustered-Indizes, Nicht-Clustered-Indizes, Joint-Indizes und Unique-Indizes in MySQL?
Was sind Clustered-Indizes, Nicht-Clustered-Indizes, Joint-Indizes und Unique-Indizes in MySQL?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-26 16:37:472606Durchsuche
1. Indextyp
Der Index kann entsprechend der zugrunde liegenden Implementierung in B-Tree-Index und Hash-Index unterteilt werden. Meistens verwenden wir den B-Tree-Index, da seine gute Leistung und Eigenschaften besser für Build geeignet sind Systeme mit hoher Parallelität.
Unterteilt nach der Speichermethode des Index kann der Index in Clustered-Index und Nicht-Clustered-Index unterteilt werden. Die Blattknoten eines nicht gruppierten Index enthalten nur alle Felder und Primärschlüssel-IDs, während die Blattknoten eines gruppierten Index vollständige Datensatzzeilen enthalten.
Je nach Clustered-Index und Non-Clustered-Index kann er weiter in gewöhnliche Indizes, abdeckende Indizes, eindeutige Indizes und gemeinsame Indizes unterteilt werden.
2. Clustered-Index und Nicht-Cluster-Index: Clustered-Index ist eigentlich kein separater Indextyp, sondern eine Datenspeichermethode. Die Blattknoten des Clustered-Index werden in einem gespeichert Reihe. Mit anderen Worten: Der Blattknoten des Clustered-Index enthält eine vollständige Datensatzzeile.
Der nicht gruppierte Index wird auch als Hilfsindex und gewöhnlicher Index bezeichnet. Seine Blattknoten enthalten nur einen Primärschlüsselwert. Um Datensätze über den nicht gruppierten Index zu finden, müssen Sie zuerst den Primärschlüssel finden Der entsprechende Datensatz im Clustered-Index wird als Tabellenrückgabe bezeichnet.
Zum Beispiel eine Datentabelle mit Benutzernamen und Alter, vorausgesetzt, der Primärschlüssel ist die Benutzer-ID, die Struktur des Clustered-Index ist (orange stellt die ID dar, grün ist der Zeiger auf den untergeordneten Knoten):
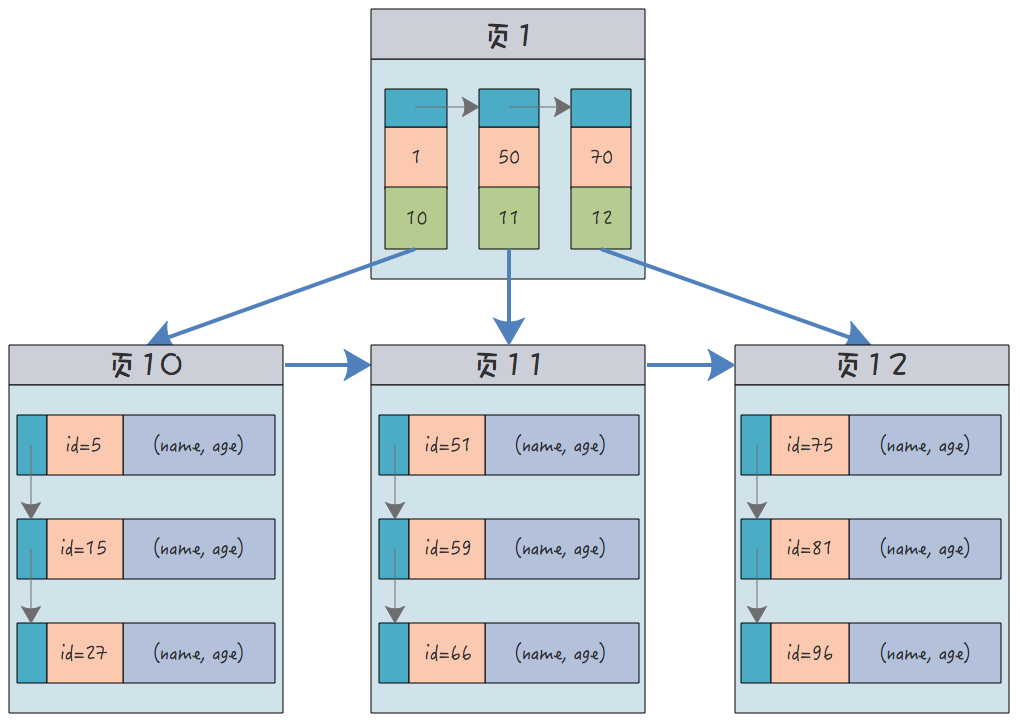 Im Blattknoten wird
Im Blattknoten wird
(id, name, age)Die Struktur eines nicht gruppierten Index (indiziert nach Alter) ist:
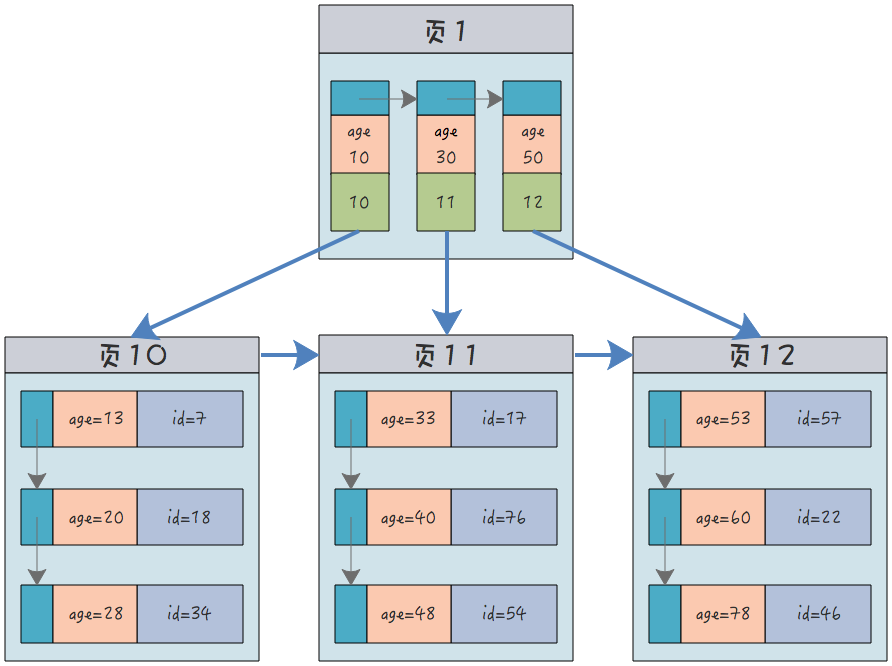 Zusätzlich zum Altersfeld selbst ist in den Blattknoten dieses Knotens nur die Primärschlüssel-ID des aktuellen Datensatzes enthalten. nicht die vollständig aufgezeichneten Informationen. Sie müssen den Clustered-Index anhand der ID-Nummer abfragen, um die gesamte Datensatzdatenzeile zu erhalten.
Zusätzlich zum Altersfeld selbst ist in den Blattknoten dieses Knotens nur die Primärschlüssel-ID des aktuellen Datensatzes enthalten. nicht die vollständig aufgezeichneten Informationen. Sie müssen den Clustered-Index anhand der ID-Nummer abfragen, um die gesamte Datensatzdatenzeile zu erhalten.
In InnoDB muss jede Tabelle über einen Clustered-Index verfügen, der standardmäßig basierend auf dem Primärschlüssel erstellt wird. Wenn in der Tabelle kein Primärschlüssel vorhanden ist, wählt InnoDB eine geeignete Spalte als Clustered-Index aus. Wenn keine geeignete Spalte gefunden wird, wird eine versteckte Spalte DB_ROW_ID als Clustered-Index verwendet.
3. Abdeckungsindex
Da der nicht gruppierte Index keine vollständigen Dateninformationen enthält, erfordert die Suche nach vollständigen Datensätzen eine Tabellenrückgabe, sodass für einen Abfragevorgang tatsächlich zwei Indexabfragen erforderlich sind. Wenn jede Indexabfrage zweimal ausgeführt werden muss, um das Ergebnis zu erhalten, führt dies unweigerlich zu einem Effizienzverlust, denn wenn Sie die Abfrage um eins reduzieren können, sollten Sie sie auch um eins reduzieren.
Nehmen Sie den Altersindex oben als Beispiel. Es handelt sich um einen nicht gruppierten Index. Wenn ich die ID des Benutzers nach Alter abfragen möchte, führe ich die folgende Anweisung aus:
| select id from Benutzerinfo, wobei Alter = 10; |
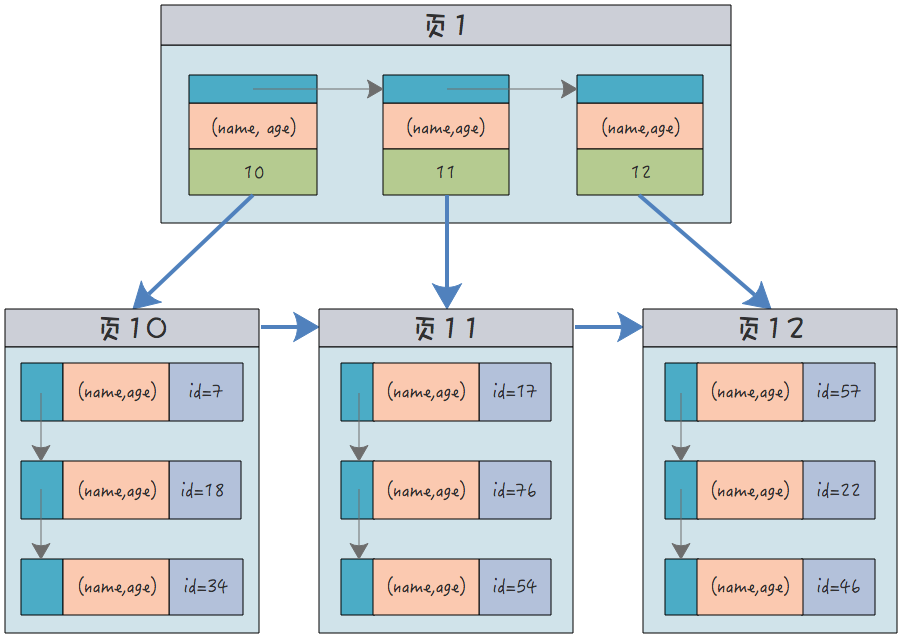
Das obige ist der detaillierte Inhalt vonWas sind Clustered-Indizes, Nicht-Clustered-Indizes, Joint-Indizes und Unique-Indizes in MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!