
Heim >Datenbank >MySQL-Tutorial >So optimieren Sie SQL-Anweisungen in MySQL
So optimieren Sie SQL-Anweisungen in MySQL

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-26 14:07:432053Durchsuche
1. Übersicht
Aufgrund der geringen Menge an Ausgangsdaten achten Entwickler beim offiziellen Start des Anwendungssystems mehr auf die funktionale Implementierung Aufgrund der Menge an Produktionsdaten zeigen sich nach und nach Leistungsprobleme bei vielen SQL-Anweisungen, und auch ihre Auswirkungen auf die Produktionsumgebung nehmen zu. Zu diesem Zeitpunkt werden diese problematischen SQL-Anweisungen zum Engpass für die gesamte Systemleistung, sodass wir sie optimieren müssen.
2. Verwenden Sie den Befehl „show status“, um die Ausführungshäufigkeit verschiedener SQLs zu verstehen.
Nachdem der MySQL-Client erfolgreich verbunden wurde, können Sie Serverstatusinformationen über den Befehl „show [session|global]status“ bereitstellen oder mysqladmin erweitert verwenden -status im Betriebssystembefehl, um diese Meldungen abzurufen. show [session|global] status kann nach Bedarf den Parameter „session“ oder „global“ hinzufügen, um die statistischen Ergebnisse auf Sitzungsebene (aktuelle Verbindung) und die statistischen Ergebnisse auf globaler Ebene (seit dem letzten Start der Datenbank) anzuzeigen ). Wenn nicht geschrieben, wird als Standardparameter „session“ verwendet.
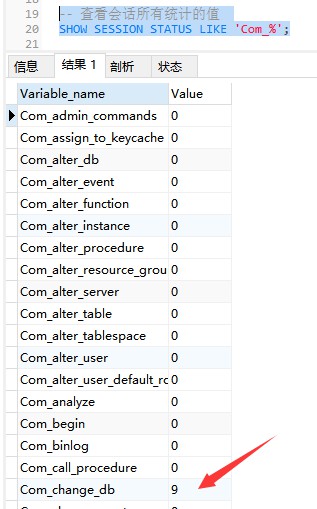
Der folgende Befehl zeigt die Werte aller statistischen Parameter in der aktuellen Sitzung an:
-- 查看会话所有统计的值 SHOW STATUS LIKE 'Com_%'; Or SHOW SESSION STATUS LIKE 'Com_%';
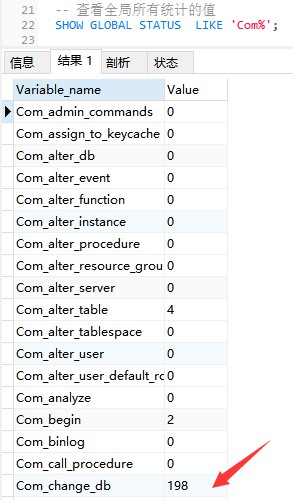
Der folgende Befehl zeigt die Werte aller statistischen Parameter in der aktuellen globalen Sitzung an:
-- Werte anzeigen aller globalen Statistiken
SHOW GLOBAL STATUS LIKE 'Com_%';
Com_xxx stellt die Häufigkeit dar, mit der jede xxx-Anweisung ausgeführt wird. Normalerweise sind uns die folgenden statistischen Parameter wichtig:
Com_select: Die Häufigkeit, mit der SELECT-Operationen ausgeführt werden, nur 1 für eine Abfrage gesammelt.
Com_insert: Die Anzahl der auszuführenden INSERT-Operationen. Bei Batch-INSERT-Operationen wird sie nur einmal akkumuliert.
Com_update: Die Häufigkeit, mit der UPDATE-Vorgänge ausgeführt werden.
Com_delete: Anzahl der DELETE-Vorgänge.
Die oben genannten Parameter werden für alle Tabellenoperationen der Speicher-Engine akkumuliert. Diese Parameter gelten nur für die InnoDB-Speicher-Engine und ihr Akkumulationsalgorithmus unterscheidet sich geringfügig.
Innodb_rows_read: Die Anzahl der von der SELECT-Abfrage zurückgegebenen Zeilen.
Innodb_rows_inserted: Die Anzahl der Zeilen, die durch Ausführen der INSERT-Operation eingefügt wurden.
Innodb_rows_updated: Die Anzahl der Zeilen, die durch den UPDATE-Vorgang aktualisiert wurden.
Innodb_rows_deleted: Die Anzahl der Zeilen, die durch den DELETE-Vorgang gelöscht wurden.
Anhand der oben genannten Parameter können Sie leicht erkennen, ob das aktuelle Datenbankanwendungssystem hauptsächlich auf Einfügungs- und Aktualisierungs- oder Abfragevorgängen basiert und wie hoch das ungefähre Ausführungsverhältnis verschiedener SQL-Typen ist. Unabhängig von Commit oder Rollback wird die Anzahl der Aktualisierungsvorgänge akkumuliert und das Zählobjekt ist die Anzahl der Ausführungen.
Bei Transaktionsanwendungen können Com_commit und Com_rollback verwendet werden, um die Übermittlung und das Rollback von Transaktionen zu verstehen. Bei Datenbanken mit sehr häufigen Rollback-Vorgängen kann es zu Problemen beim Schreiben der Anwendung kommen. Darüber hinaus helfen die folgenden Parameter Benutzern, die Grundsituation der Datenbank zu verstehen.
Verbindungen: Die Anzahl der Versuche, eine Verbindung zum MySQL-Server herzustellen.
Betriebszeit: Serverbetriebszeit.
Slow_queries: Die Anzahl der langsamen Abfragen.
3. Suchen Sie SQL-Anweisungen mit geringer Ausführungseffizienz
Sie können SQL-Anweisungen mit geringer Ausführungseffizienz auf die folgenden zwei Arten finden.
Suchen Sie SQL-Anweisungen mit geringer Ausführungseffizienz durch langsame Abfrageprotokolle. Beim Starten mit der Option --log-slow-queries[=file_name] schreibt mysqld eine Protokolldatei, die alle SQL-Anweisungen enthält, deren Ausführungszeit long_query_time Sekunden überschreitet.
Das langsame Abfrageprotokoll wird nach Abschluss der Abfrage aufgezeichnet. Wenn das Anwendungssystem Probleme mit der Ausführungseffizienz anzeigt, kann das Problem daher durch Abfragen des langsamen Abfrageprotokolls nicht gefunden werden. Sie können die aktuellen MySQL-Threads anzeigen , einschließlich Thread-Status, ob die Tabelle gesperrt werden soll usw., können Sie den Ausführungsstatus von SQL in Echtzeit überprüfen und gleichzeitig einige Tabellensperrvorgänge optimieren.
4. Analysieren Sie den Ausführungsplan von ineffizientem SQL mit EXPLAIN
Nachdem Sie die SQL-Anweisung mit geringer Ausführungseffizienz gefunden haben, können Sie den Befehl EXPLAIN oder DESC verwenden, um Informationen darüber zu erhalten, wie MySQL die SELECT-Anweisung ausführt, auch während der Ausführung der SELECT-Anweisung. So verbinden Sie die Tabellen und die Reihenfolge der Verbindungen. Wenn Sie beispielsweise die Anzahl aller Lagerbestände zählen möchten, müssen Sie die Tabelle „goods_stock“ und die Tabelle „goods_stock_price“ verknüpfen und eine Summenoperation ausführen Das Feld „goods_stock_price.Qty“ lautet wie folgt:
EXPLAIN SELECT SUM(sp.Qty) FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp ON s.ID=sp.GoodsStockID;

Wie in der Abbildung oben gezeigt, lautet die einfache Erklärung jeder Spalte wie folgt:
select_type: Gibt den Typ von SELECT an. Gängige Werte sind:
SIMPLE (einfache Tabelle, d. h. es wird keine Tabellenverbindung oder Unterabfrage verwendet).
PRIMARY (die Hauptabfrage, also die äußere Abfrage), UNION (die zweite oder nachfolgende Abfrageanweisung in UNION), ◎SUBQUERY (die erste SELECT in der Unterabfrage) usw.
Tabelle: Die Tabelle, die die Ergebnismenge ausgibt.
type:表示表的连接类型,性能由好到差的连接类型为:
system(表中仅有一行,即常量表)。
const(单表中最多有一个匹配行,例如primary key或者unique index)。
eq_ref(对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用primary key或者unique index)。
ref(与eq_ref类似,区别在于不是使用primary key或者unique index,而是使用普通的索引)。
ref_or_null(与ref类似,区别在于条件中包含对NULL的查询)。
index_merge(索引合并优化)。
unique_subquery(in的后面是一个查询主键字段的子查询)。
index_subquery(与unique_subquery类似,区别在于in的后面是查询非唯一索引字段的子查询)。
range(单表中的范围查询)。
index(对于前面的每一行,都通过查询索引来得到数据)。
all(对于前面的每一行,都通过全表扫描来得到数据)。
possible_keys:表示查询时,可能使用的索引。
key:表示实际使用的索引。
key_len:索引字段的长度。
rows:扫描行的数量。
filtered:返回结果的行占需要读到的行(rows列的值)的百分比。
Extra:执行情况的说明和描述。
Using index(此值表示mysql将使用覆盖索引,以避免访问表)。
Using where(mysql 将在存储引擎检索行后再进行过滤,许多where条件里涉及索引中的列,当(并且如果)它读取索引时,就能被存储引擎检验,因此不是所有带where子句的查询都会显示“Using where”。“Using where”有时提示了一种可能性:查询可以从不同的索引中受益。
Using temporary(mysql 对查询结果排序时会使用临时表)。
MySQL will apply an external index sorting on the results instead of reading rows from the table in index order.。mysql有两种文件排序算法,这两种排序方式都可以在内存或者磁盘上完成,explain不会告诉你mysql将使用哪一种文件排序,也不会告诉你排序会在内存里还是磁盘上完成)。
Range checked for each record(index map: N) (没有好用的索引,新的索引将在联接的每一行上重新估算,N是显示在possible_keys列中索引的位图,并且是冗余的)。
5.确定问题并采取相应的优化措施
经过以上定位步骤,我们基本就可以分析到问题出现的原因。此时我们可以根据情况采取相应的改进措施,进行优化提高语句执行效率。
在上面的例子中,已经可以确认是goods_stock是走主键索引的,但是对goods_stock_price子表的进行了全表扫描导致效率的不理想,那么应该对goods_stock_price表的GoodsStockID字段创建索引,具体命令如下:
-- 创建索引 CREATE INDEX idx_stock_price_1 ON goods_stock_price (GoodsStockID); -- 附加删除跟查询索引语句 ALTER TABLE goods_stock_price DROP INDEX idx_stock_price_1; SHOW INDEX FROM goods_stock_price;
创建索引后,我们再看一下这条语句的执行计划,具体如下:
EXPLAIN SELECT SUM(sp.Qty) FROM goods_stock AS s LEFT JOIN goods_stock_price AS sp ON s.ID=sp.GoodsStockID;

可以发现建立索引后对goods_stock_price子表需要扫描的行数明显减少(从 3 行减少到1行),可见索引的使用可以大大提高数据库的访问速度,尤其在表很庞大的时候这种优势更为明显。
Das obige ist der detaillierte Inhalt vonSo optimieren Sie SQL-Anweisungen in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!