
Heim >Datenbank >MySQL-Tutorial >Was ist der Unterschied zwischen count(*), count(1) und count(col) in MySQL?
Was ist der Unterschied zwischen count(*), count(1) und count(col) in MySQL?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-26 13:37:081879Durchsuche
count Funktion
COUNT(expression): Gibt die Gesamtzahl der abgefragten Datensätze zurück * Zeichen.
Test
MySQL-Version: 5.7.29
Erstellen Sie eine Benutzertabelle und fügen Sie eine Million Daten ein, wobei das Geschlechtsfeld fünf enthält Einhunderttausend Zeilen sind Nullwerte
CREATE TABLE `users` ( `Id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'id', `name` varchar(32) DEFAULT NULL COMMENT '名称', `gender` varchar(20) DEFAULT NULL COMMENT '性别', `create_date` datetime DEFAULT NULL COMMENT '创建时间', PRIMARY KEY (`Id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='用户表';
count(*)
Vor MySQL 5.7.18 verarbeitete InnoDB Anweisungen durch Scannen des Clustered-Index. SELECT COUNT( *) Ab MySQL 5.7.18 verarbeitet InnoDB SELECT COUNT( *)-Anweisungen durch Durchlaufen des kleinsten verfügbaren Sekundärindex, es sei denn, der Index- oder Optimiererhinweis weist den Optimierer an, einen anderen Index zu verwenden. Wenn der Sekundärindex nicht vorhanden ist, wird der Clustered-Index gescannt.
Die allgemeine Bedeutung lautet: Wenn ein Sekundärindex vorhanden ist, verwenden Sie den Sekundärindex. Wenn mehrere Sekundärindizes vorhanden sind, wird der kleinste Sekundärindex bevorzugt, um die Kosten zu senken. Wenn kein Sekundärindex vorhanden ist, verwenden Sie den Clustered-Index .
Die folgenden Tests werden verwendet, um diese Ansichten zu überprüfen.
Fragen Sie zunächst den Ausführungsplan ab, wenn nur der Primärschlüsselindex der ID vorhanden ist Der Typ Index bedeutet, dass ein Index verwendet wird. Schlüssel ist PRIMARY, was bedeutet, dass der Primärschlüsselindex verwendet wird, key_len = 8.
Zweitens fügen Sie einen Index zum Namensfeld hinzu und verwenden Sie den Ausführungsplan erneut, um 
 Fügen Sie dann einen Index zum Feld „create_date“ hinzu, behalten Sie dabei den Index des Namensfelds bei und überprüfen Sie den Ausführungsplan erneut Achten Sie darauf, dass dieses Mal der Index des Feldes „create_date“ verwendet wird, key_len=6.
Fügen Sie dann einen Index zum Feld „create_date“ hinzu, behalten Sie dabei den Index des Namensfelds bei und überprüfen Sie den Ausführungsplan erneut Achten Sie darauf, dass dieses Mal der Index des Feldes „create_date“ verwendet wird, key_len=6.
Unabhängig davon, welcher Index oben verwendet wird, beträgt die Gesamtzahl der letztendlich abgefragten Zeilen eine Million, unabhängig davon, ob sie NULL-Werte enthalten.
count(1)
count(1) hat die gleichen Abfrageergebnisse wie count(*) und gibt letztendlich eine Million Daten zurück, unabhängig davon, ob sie NULL enthalten Werte. 
Abfrage mit count(name), der Ausführungsplan ist wie folgt:
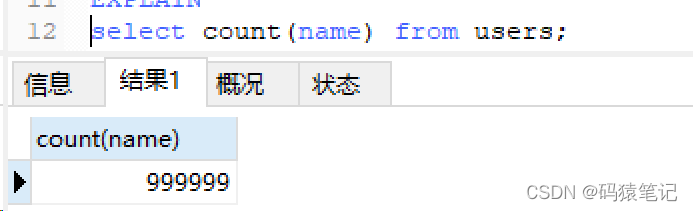
Sie können sehen, dass die Das Indexfeld wird für Statistiken verwendet. Der Index dient auch als Treffer.Setzen Sie das Namensfeld in einer Spalte auf NULL und führen Sie dann eine Zählabfrage durch. Das Ergebnis gibt 999999 zurück.
Setzen Sie dann den NULL-Wert Diese Spalte ist eine leere Zeichenfolge. Führen Sie dann eine Zählabfrage durch. Das Ergebnis gibt 1000000 zurück. Das Ergebnis gibt 1000000 zurück. Das Ergebnis gibt 1000000 zurück Zählen Sie die Anzahl der Zeilen, die den Index erreichen können, und zählen Sie nur die Anzahl der Zeilen, die keine NULL-Werte sind. count(normal col): Felder ohne Indizes zählen
count(normal col): Felder ohne Indizes zählen
Wenn Sie Felder ohne Indizes zählen, wird der Index nicht verwendet und es werden nur Nicht-NULL-Werte verwendet gezählt. Anzahl der Zeilen.
Übersetzung bedeutet, dass InnoDB die Vorgänge SELECT COUNT(*) und SELECT COUNT(1) auf die gleiche Weise behandelt, es gibt keinen Leistungsunterschied. 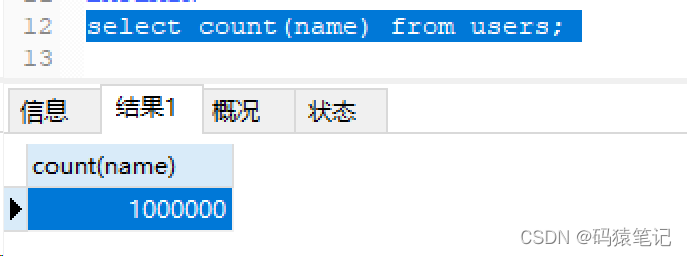
Diese Optimierungen basieren auf der Prämisse, dass es kein „Wo“ und „Gruppieren nach“ gibt.
Es wird auch in den Ali-Entwicklungsspezifikationen erwähnt
 Wenn Sie also count(*) in der Entwicklung verwenden können, dann einfach Verwenden Sie count( * ).
Wenn Sie also count(*) in der Entwicklung verwenden können, dann einfach Verwenden Sie count( * ).
Das obige ist der detaillierte Inhalt vonWas ist der Unterschied zwischen count(*), count(1) und count(col) in MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!