
Heim >Datenbank >MySQL-Tutorial >So lösen Sie das Problem des durch MySQL verursachten Verbindungsfehlers mithilfe von ReplicationConnection
So lösen Sie das Problem des durch MySQL verursachten Verbindungsfehlers mithilfe von ReplicationConnection

- PHPznach vorne
- 2023-05-26 13:10:321607Durchsuche
Einführung
Die Lese- und Schreibtrennung in MySQL-Datenbanken ist eines der gängigen Mittel zur Verbesserung der Servicequalität. Für technische Lösungen gibt es viele ausgereifte Open-Source-Frameworks oder -Lösungen, wie zum Beispiel: Sharding. jdbc, spring AbstractRoutingDatasource, MySQL-Router usw. und ReplicationConnection in mysql-jdbc können ebenfalls unterstützt werden.
In diesem Artikel wird die technische Auswahl der Lese-/Schreibtrennung nicht allzu sehr analysiert. Er untersucht nur die Gründe für Verbindungsfehler, wenn Druid als Datenquelle verwendet und mit ReplicationConnection für Lese-/Schreibzugriff kombiniert wird Trennung und findet eine einfache effektive Lösung.
Problemhintergrund
Aus historischen Gründen gibt es für bestimmte Dienste Ausnahmen für Verbindungsfehler:
 # 🎜🎜 #
# 🎜🎜 #
JDBC-Konfiguration
jdbc:mysql:replication:// master_host :port,slave_host:port/database_name
Druid-Konfiguration
testWhileIdle=true (also offen Überprüfung der Leerlaufverbindung); , es wird verworfen und wiedererlangt). Anhang: Die Verarbeitungslogik inin DruidDataSource.getConnectionDirect lautet wie folgt:
if (testWhileIdle) { final DruidConnectionHolder holder = poolableConnection.holder; long currentTimeMillis = System.currentTimeMillis(); long lastActiveTimeMillis = holder.lastActiveTimeMillis; long lastExecTimeMillis = holder.lastExecTimeMillis; long lastKeepTimeMillis = holder.lastKeepTimeMillis; if (checkExecuteTime && lastExecTimeMillis != lastActiveTimeMillis) { lastActiveTimeMillis = lastExecTimeMillis; } if (lastKeepTimeMillis > lastActiveTimeMillis) { lastActiveTimeMillis = lastKeepTimeMillis; } long idleMillis = currentTimeMillis - lastActiveTimeMillis; long timeBetweenEvictionRunsMillis = this.timeBetweenEvictionRunsMillis; if (timeBetweenEvictionRunsMillis <= 0) { timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS; } if (idleMillis >= timeBetweenEvictionRunsMillis || idleMillis < 0 // unexcepted branch ) { boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn); if (!validate) { if (LOG.isDebugEnabled()) { LOG.debug("skip not validate connection."); } discardConnection(poolableConnection.holder); continue; } } }
MySQL-Timeout-Parameter Configuration#🎜🎜 #wait_timeout=3600 (3600 Sekunden, d. h. wenn eine Verbindung länger als eine Stunde nicht mit dem Server interagiert, wird die Verbindung vom Server unterbrochen). Offensichtlich sollte auf der Grundlage der obigen Konfiguration nach herkömmlichem Verständnis das Problem „Das letzte erfolgreich vom Server empfangene Paket war vor xxx,xxx,xxx Millisekunden“ nicht auftreten. (Natürlich war damals auch die Möglichkeit eines manuellen Eingriffs zum Abbruch der Datenbankverbindung ausgeschlossen).
Wenn die „selbstverständliche“ Erfahrung das Problem nicht erklären kann, ist es oft notwendig, aus den Fesseln der oberflächlichen Erfahrung zu springen und der Sache auf den Grund zu gehen. Was ist also die wahre Ursache dieses Problems?Wesentlicher Grund
Wenn Druid zum Verwalten von Datenquellen verwendet und mit der nativen ReplicationConnection in MySQL-JDBC zur Lese- und Schreibtrennung kombiniert wird, gibt es tatsächlich zwei Sätze von Master und Slaves im ReplicationConnection-Proxy-Objekt. Wenn Druid eine Verbindungserkennung durchführt, kann es nur die Master-Verbindung erkennen. Wenn eine Slave-Verbindung längere Zeit nicht verwendet wird, führt dies zu einem Verbindungsfehler.
Ursachenanalyse
mysql-jdbc, der Verbindungsverarbeitungsprozess des Datenbanktreibers
In Kombination mit dem Quellcode com.mysql.jdbc.Driver ist es nicht hässlich Der Hauptprozess zum Herstellen einer Verbindung aus MySQL-JDBC ist wie folgt:
Für JDBC-URLs, die mit „jdbc:mysql“ beginnen: replication://“ ist die über mysql-jdbc erhaltene Verbindung tatsächlich ein Proxy-Objekt von ReplicationConnection. Standardmäßig entsprechen der erste Host und der erste Port nach „jdbc:mysql:replication://“ der Master-Verbindung und dem nachfolgenden Host und Port Entspricht Slave-Verbindungen. In Szenarien mit mehreren Slave-Konfigurationen wird standardmäßig eine Zufallsstrategie für den Lastausgleich verwendet. Das ReplicationConnection-Proxy-Objekt wird mithilfe des dynamischen JDK-Proxys generiert. Die spezifische Implementierung von InvocationHandler lautet ReplicationConnectionProxy. Der Schlüsselcode lautet wie folgt:
Das ReplicationConnection-Proxy-Objekt wird mithilfe des dynamischen JDK-Proxys generiert. Die spezifische Implementierung von InvocationHandler lautet ReplicationConnectionProxy. Der Schlüsselcode lautet wie folgt:
public static ReplicationConnection createProxyInstance(List<String> masterHostList, Properties masterProperties, List<String> slaveHostList,
Properties slaveProperties) throws SQLException {
ReplicationConnectionProxy connProxy = new ReplicationConnectionProxy(masterHostList, masterProperties, slaveHostList, slaveProperties);
return (ReplicationConnection) java.lang.reflect.Proxy.newProxyInstance(ReplicationConnection.class.getClassLoader(), INTERFACES_TO_PROXY, connProxy);
}Wichtige Komponenten von ReplicationConnectionProxy
# 🎜🎜# In Bezug auf den Datenbankverbindungs-Proxy lauten die Hauptkomponenten in ReplicationConnectionProxy wie folgt:ReplicationConnectionProxy verfügt über zwei tatsächliche Verbindungsobjekte, MasterConnection und SlavesConnection. currentConnection (aktuelle Verbindung) kann auf MasteretConnection oder SlavesConnection umgeschaltet werden, und die Umschaltmethode kann durch Festlegen von readOnly erreicht werden.
In der Geschäftslogik liegt auch hier der Kern der Realisierung der Lese-Schreib-Trennung. Vereinfacht ausgedrückt: Wenn Sie ReplicationConnection für die Lese-Schreib-Trennung verwenden, müssen Sie nur einen AOP ausführen, der „readOnly“ festlegt Attribut der Verbindung". 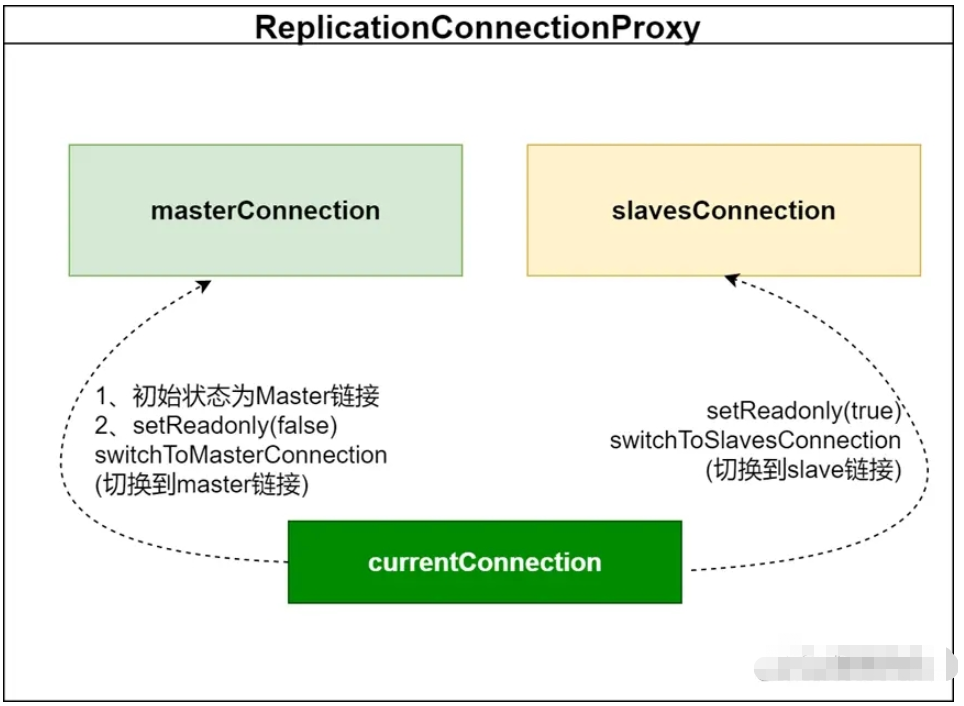
对于prepareStatement等常规逻辑,ConnectionMySQConnection获取到当前连接进行处理(普通的读写分离的处理的重点正是在此);此时,重点提及pingInternal方法,其处理方式也是获取当前连接,然后执行pingInternal逻辑。
对于ping()这个特殊逻辑,图中描述相对简单,但主体含义不变,即:对master连接和sleves连接都要进行ping()的处理。
图中,pingInternal流程和druid的MySQ连接检查有关,而ping的特殊处理,也正是解决问题的关键。
druid数据源对MySQ连接的检查
druid中对MySQL连接检查的默认实现类是MySqlValidConnectionChecker,其中核心逻辑如下:
public boolean isValidConnection(Connection conn, String validateQuery, int validationQueryTimeout) throws Exception {
if (conn.isClosed()) {
return false;
}
if (usePingMethod) {
if (conn instanceof DruidPooledConnection) {
conn = ((DruidPooledConnection) conn).getConnection();
}
if (conn instanceof ConnectionProxy) {
conn = ((ConnectionProxy) conn).getRawObject();
}
if (clazz.isAssignableFrom(conn.getClass())) {
if (validationQueryTimeout <= 0) {
validationQueryTimeout = DEFAULT_VALIDATION_QUERY_TIMEOUT;
}
try {
ping.invoke(conn, true, validationQueryTimeout * 1000);
} catch (InvocationTargetException e) {
Throwable cause = e.getCause();
if (cause instanceof SQLException) {
throw (SQLException) cause;
}
throw e;
}
return true;
}
}
String query = validateQuery;
if (validateQuery == null || validateQuery.isEmpty()) {
query = DEFAULT_VALIDATION_QUERY;
}
Statement stmt = null;
ResultSet rs = null;
try {
stmt = conn.createStatement();
if (validationQueryTimeout > 0) {
stmt.setQueryTimeout(validationQueryTimeout);
}
rs = stmt.executeQuery(query);
return true;
} finally {
JdbcUtils.close(rs);
JdbcUtils.close(stmt);
}
}对应服务中使用的mysql-jdbc(5.1.45版),在未设置“druid.mysql.usePingMethod”系统属性的情况下,默认usePingMethod为true,如下:
public MySqlValidConnectionChecker(){
try {
clazz = Utils.loadClass("com.mysql.jdbc.MySQLConnection");
if (clazz == null) {
clazz = Utils.loadClass("com.mysql.cj.jdbc.ConnectionImpl");
}
if (clazz != null) {
ping = clazz.getMethod("pingInternal", boolean.class, int.class);
}
if (ping != null) {
usePingMethod = true;
}
} catch (Exception e) {
LOG.warn("Cannot resolve com.mysql.jdbc.Connection.ping method. Will use 'SELECT 1' instead.", e);
}
configFromProperties(System.getProperties());
}
@Override
public void configFromProperties(Properties properties) {
String property = properties.getProperty("druid.mysql.usePingMethod");
if ("true".equals(property)) {
setUsePingMethod(true);
} else if ("false".equals(property)) {
setUsePingMethod(false);
}
}同时,可以看出MySqlValidConnectionChecker中的ping方法使用的是MySQLConnection中的pingInternal方法,而该方法,结合上面对ReplicationConnection的分析,当调用pingInternal时,只是对当前连接进行检验。执行检验连接的时机是通过DrduiDatasource获取连接时,此时未设置readOnly属性,检查的连接,其实只是ReplicationConnectionProxy中的master连接。
此外,如果通过“druid.mysql.usePingMethod”属性设置usePingMeghod为false,其实也会导致连接失效的问题,因为:当通过valideQuery(例如“select 1”)进行连接校验时,会走到ReplicationConnection中的普通查询逻辑,此时对应的连接依然是master连接。
题外一问:ping方法为什么使用“pingInternal”,而不是常规的ping?
原因:pingInternal预留了超时时间等控制参数。
解决方式
调整依赖版本
在服务中,使用的MySQL JDBC版本是5.1.45,并且使用的Druid版本是1.1.20。经过对其他高版本依赖的了解,依然存在该问题。
修改读写分离实现
修改的工作量主要在于数据源配置和aop调整,但需要一定的整体回归验证成本,鉴于涉及该问题的服务重要性一般,暂不做大调整。
拓展mysql-jdbc驱动
基于原有ReplicationConnection的功能,拓展pingInternal调整为普通的ping,集成原有Driver拓展新的Driver。方案可行,但修改成本不算小。
基于druid,拓展MySQL连接检查
为简单高效解决问题,选择拓展MySqlValidConnectionChecker,并在druid数据源中加上对应配置即可。拓展如下:
public class MySqlReplicationCompatibleValidConnectionChecker extends MySqlValidConnectionChecker {
private static final Log LOG = LogFactory.getLog(MySqlValidConnectionChecker.class);
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public boolean isValidConnection(Connection conn, String validateQuery, int validationQueryTimeout) throws Exception {
if (conn.isClosed()) {
return false;
}
if (conn instanceof DruidPooledConnection) {
conn = ((DruidPooledConnection) conn).getConnection();
}
if (conn instanceof ConnectionProxy) {
conn = ((ConnectionProxy) conn).getRawObject();
}
if (conn instanceof ReplicationConnection) {
try {
((ReplicationConnection) conn).ping();
LOG.info("validate connection success: connection=" + conn.toString());
return true;
} catch (SQLException e) {
LOG.error("validate connection error: connection=" + conn.toString(), e);
throw e;
}
}
return super.isValidConnection(conn, validateQuery, validationQueryTimeout);
}
}ReplicatoinConnection.ping()的实现逻辑中,会对所有master和slaves连接进行ping操作,最终每个ping操作都会调用到LoadBalancedConnectionProxy.doPing进行处理,而此处,可在数据库配置url中设置loadBalancePingTimeout属性设置超时时间。
Das obige ist der detaillierte Inhalt vonSo lösen Sie das Problem des durch MySQL verursachten Verbindungsfehlers mithilfe von ReplicationConnection. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!