
Heim >Backend-Entwicklung >Python-Tutorial >So verwenden Sie Tensorflow zum Aufbau eines langen Kurzzeitgedächtnisses LSTM in Python
So verwenden Sie Tensorflow zum Aufbau eines langen Kurzzeitgedächtnisses LSTM in Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-22 12:32:141445Durchsuche
Einführung in LSTM
1. Das Problem des verschwindenden Gradienten von RNN
In der Vergangenheit haben wir etwas über das wiederkehrende neuronale Netzwerk von RNN gelernt:
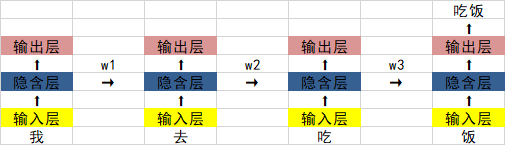
Das größte Problem besteht darin, dass w1 , w2 Wenn die Werte von w3 und w3 kleiner als 0 sind und ein Satz lang genug ist, besteht das Problem des Verschwindens des Gradienten, wenn das neuronale Netzwerk eine Rückwärtsausbreitung und eine Vorwärtsausbreitung durchführt.
0,925 = 0,07. Wenn ein Satz 20 bis 30 Wörter enthält, ist die Ausgabe der verborgenen Ebene beim Weitergeben an das Ende 0,07-mal so groß wie die des letzten Wortes. .
Die spezifische Situation ist wie folgt:
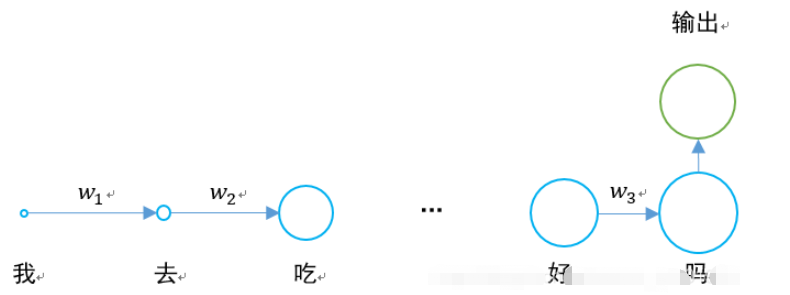
Das Netzwerk des Langzeit-Kurzzeitgedächtnisses entstand, um das Problem des Verschwindens des Gradienten zu lösen.
2. Struktur von LSTM
Die verborgene Schicht des ursprünglichen RNN hat nur einen Zustand h, der von Anfang bis Ende übergeben wird. Er reagiert sehr empfindlich auf kurzfristige Eingaben.
Wenn wir einen weiteren Zustand c hinzufügen und ihn den Langzeitzustand speichern lassen, kann das Problem gelöst werden.
Für RNN und LSTM ist der Vergleich der beiden Schritteinheiten wie folgt.

Wir erweitern die Struktur von LSTM entsprechend der Zeitdimension:
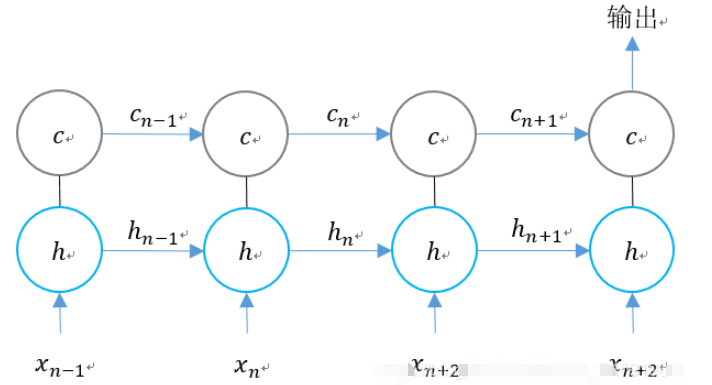
Wir können sehen, dass es zu n-Zeiten drei Eingaben für LSTM gibt:
1. Der Eingabewert des Netzwerks bei der aktuelle Moment;
LSTM hat zwei Ausgänge:
1. LSTM-Ausgabewert zum aktuellen Zeitpunkt;
2.
3. Die einzigartige Gate-Struktur von LSTMLSTM verwendet zwei Gates, um den Inhalt des Unit-State-CN zu steuern:
1, das den Unit-State-CN-1 im vorherigen Moment bestimmt viel bleibt im aktuellen Moment erhalten;
2. Eingangsgatter (Eingangsgatter), das bestimmt, wie viel von der Eingangsspannung des Netzwerks im aktuellen Moment im Gerätezustand gespeichert wird.
LSTM verwendet ein Gatter, um den Inhalt des aktuellen Ausgabewerts hn zu steuern:
Verwandte Funktionen von LSTM im Tensorflow
tf.contrib.rnn.BasicLSTMCelltf.contrib.rnn.BasicLSTMCell(
num_units,
forget_bias=1.0,
state_is_tuple=True,
activation=None,
reuse=None,
name=None,
dtype=None
)num_units: Die Anzahl der Neuronen in der RNN-Einheit, also die Anzahl der Ausgabeneuronen.
forget_bias: Bias hinzugefügtes Vergiss-Gate. Setzen Sie den wiederhergestellten CudnnLSTM-Trainingskontrollpunkt manuell auf 0,0. 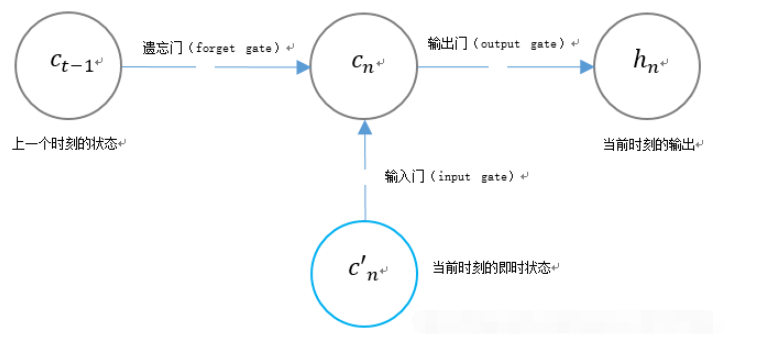
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)Nach Abschluss der Definition kann der Status initialisiert werden:
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)tf.nn.dynamic_rnn
tf.nn.dynamic_rnn(
cell,
inputs,
sequence_length=None,
initial_state=None,
dtype=None,
parallel_iterations=None,
swap_memory=False,
time_major=False,
scope=None
)
cell: lstm_cell oben definiert.
Eingaben: RNN-Eingabe. Wenn time_major==false (Standard), muss es ein Tensor der Form [batch_size, max_time, …] oder ein verschachteltes Tupel solcher Elemente sein. Wenn time_major==true, muss es ein Tensor der Form [max_time, batch_size, …] oder ein verschachteltes Tupel solcher Elemente sein.
- Die Größe des Vektors wird durch den Parameter sequence_length bestimmt und sein Typ ist Int32/Int64. Wird zum Durchkopieren des Status und der Nullausgabe verwendet, wenn die Sequenzlänge von Batch-Elementen überschritten wird. Es geht also mehr um Leistung als um Korrektheit.
- initial_state: _init_state oben definiert.
- dtype: Datentyp.
- parallel_iterations: Anzahl der Iterationen, die parallel ausgeführt werden sollen. Dabei handelt es sich um Vorgänge, die keine Zeitabhängigkeit aufweisen und parallel ausgeführt werden können. Dieser Parameter tauscht Zeit gegen Raum. Größere Werte verbrauchen mehr Speicher, arbeiten aber schneller, während kleinere Werte weniger Speicher verbrauchen, aber eine längere Rechenzeit erfordern.
time_major:输入和输出tensor的形状格式。这些张量的形状必须为[max_time, batch_size, depth],若表述正确,则它为真。这些张量的形状必须是[batch_size,max_time,depth],如果为假。time_major=true可以提高效率,因为它避免了在RNN计算的开头和结尾进行转置操作。默认情况下,此函数为False,因为大多数的 TensorFlow 数据以批处理主数据的形式存在。
scope:创建的子图的可变作用域;默认为“RNN”。
在LSTM的最后,需要用该函数得出结果。
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn( lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
返回的是一个元组 (outputs, state):
outputs:LSTM的最后一层的输出,是一个tensor。如果为time_major== False,则它的shape为[batch_size,max_time,cell.output_size]。如果为time_major== True,则它的shape为[max_time,batch_size,cell.output_size]。
states:states是一个tensor。state是最终的状态,也就是序列中最后一个cell输出的状态。一般情况下states的形状为 [batch_size, cell.output_size],但当输入的cell为BasicLSTMCell时,states的形状为[2,batch_size, cell.output_size ],其中2也对应着LSTM中的cell state和hidden state。
整个LSTM的定义过程为:
def add_input_layer(self,):
#X最开始的形状为(256 batch,28 steps,28 inputs)
#转化为(256 batch*28 steps,128 hidden)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='to_2D')
#获取Ws和Bs
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size])
#转化为(256 batch*28 steps,256 hidden)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# (batch * n_steps, cell_size) ==> (batch, n_steps, cell_size)
# (256*28,256)->(256,28,256)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='to_3D')
def add_cell(self):
#神经元个数
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
#每一次传入的batch的大小
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
#不是主列
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
#设置Ws,Bs
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size])
# shape = (batch,output_size)
# (256,10)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(self.cell_final_state[-1], Ws_out) + bs_out全部代码
该例子为手写体识别例子,将手写体的28行分别作为每一个step的输入,输入维度均为28列。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
mnist = input_data.read_data_sets("MNIST_data",one_hot = "true")
BATCH_SIZE = 256 # 每一个batch的数据数量
TIME_STEPS = 28 # 图像共28行,分为28个step进行传输
INPUT_SIZE = 28 # 图像共28列
OUTPUT_SIZE = 10 # 共10个输出
CELL_SIZE = 256 # RNN 的 hidden unit size,隐含层神经元的个数
LR = 1e-3 # learning rate,学习率
def get_batch(): #获取训练的batch
batch_xs,batch_ys = mnist.train.next_batch(BATCH_SIZE)
batch_xs = batch_xs.reshape([BATCH_SIZE,TIME_STEPS,INPUT_SIZE])
return [batch_xs,batch_ys]
class LSTMRNN(object): #构建LSTM的类
def __init__(self, n_steps, input_size, output_size, cell_size, batch_size):
self.n_steps = n_steps
self.input_size = input_size
self.output_size = output_size
self.cell_size = cell_size
self.batch_size = batch_size
#输入输出
with tf.name_scope('inputs'):
self.xs = tf.placeholder(tf.float32, [None, n_steps, input_size], name='xs')
self.ys = tf.placeholder(tf.float32, [None, output_size], name='ys')
#直接加层
with tf.variable_scope('in_hidden'):
self.add_input_layer()
#增加LSTM的cell
with tf.variable_scope('LSTM_cell'):
self.add_cell()
#直接加层
with tf.variable_scope('out_hidden'):
self.add_output_layer()
#计算损失值
with tf.name_scope('cost'):
self.compute_cost()
#训练
with tf.name_scope('train'):
self.train_op = tf.train.AdamOptimizer(LR).minimize(self.cost)
#正确率计算
self.correct_pre = tf.equal(tf.argmax(self.ys,1),tf.argmax(self.pred,1))
self.accuracy = tf.reduce_mean(tf.cast(self.correct_pre,tf.float32))
def add_input_layer(self,):
#X最开始的形状为(256 batch,28 steps,28 inputs)
#转化为(256 batch*28 steps,128 hidden)
l_in_x = tf.reshape(self.xs, [-1, self.input_size], name='to_2D')
#获取Ws和Bs
Ws_in = self._weight_variable([self.input_size, self.cell_size])
bs_in = self._bias_variable([self.cell_size])
#转化为(256 batch*28 steps,256 hidden)
with tf.name_scope('Wx_plus_b'):
l_in_y = tf.matmul(l_in_x, Ws_in) + bs_in
# (batch * n_steps, cell_size) ==> (batch, n_steps, cell_size)
# (256*28,256)->(256,28,256)
self.l_in_y = tf.reshape(l_in_y, [-1, self.n_steps, self.cell_size], name='to_3D')
def add_cell(self):
#神经元个数
lstm_cell = tf.contrib.rnn.BasicLSTMCell(self.cell_size, forget_bias=1.0, state_is_tuple=True)
#每一次传入的batch的大小
with tf.name_scope('initial_state'):
self.cell_init_state = lstm_cell.zero_state(self.batch_size, dtype=tf.float32)
#不是主列
self.cell_outputs, self.cell_final_state = tf.nn.dynamic_rnn(
lstm_cell, self.l_in_y, initial_state=self.cell_init_state, time_major=False)
def add_output_layer(self):
#设置Ws,Bs
Ws_out = self._weight_variable([self.cell_size, self.output_size])
bs_out = self._bias_variable([self.output_size])
# shape = (batch,output_size)
# (256,10)
with tf.name_scope('Wx_plus_b'):
self.pred = tf.matmul(self.cell_final_state[-1], Ws_out) + bs_out
def compute_cost(self):
self.cost = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits = self.pred,labels = self.ys)
)
def _weight_variable(self, shape, name='weights'):
initializer = np.random.normal(0.0,1.0 ,size=shape)
return tf.Variable(initializer, name=name,dtype = tf.float32)
def _bias_variable(self, shape, name='biases'):
initializer = np.ones(shape=shape)*0.1
return tf.Variable(initializer, name=name,dtype = tf.float32)
if __name__ == '__main__':
#搭建 LSTMRNN 模型
model = LSTMRNN(TIME_STEPS, INPUT_SIZE, OUTPUT_SIZE, CELL_SIZE, BATCH_SIZE)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
#训练10000次
for i in range(10000):
xs, ys = get_batch() #提取 batch data
if i == 0:
#初始化data
feed_dict = {
model.xs: xs,
model.ys: ys,
}
else:
feed_dict = {
model.xs: xs,
model.ys: ys,
model.cell_init_state: state #保持 state 的连续性
}
#训练
_, cost, state, pred = sess.run(
[model.train_op, model.cost, model.cell_final_state, model.pred],
feed_dict=feed_dict)
#打印精确度结果
if i % 20 == 0:
print(sess.run(model.accuracy,feed_dict = {
model.xs: xs,
model.ys: ys,
model.cell_init_state: state #保持 state 的连续性
}))Das obige ist der detaillierte Inhalt vonSo verwenden Sie Tensorflow zum Aufbau eines langen Kurzzeitgedächtnisses LSTM in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!