
Heim >Backend-Entwicklung >Python-Tutorial >So verwenden Sie ClickHouse in Python
So verwenden Sie ClickHouse in Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-17 08:19:283343Durchsuche
ClickHouse ist eine Open-Source-Kolumnendatenbank (DBMS), die in den letzten Jahren viel Aufmerksamkeit erregt hat. Sie wird hauptsächlich im Bereich der Daten-Online-Analyse (OLAP) eingesetzt und wurde 2016 als Open-Source-Datenbank bereitgestellt. Derzeit boomt die heimische Gemeinschaft, und große Hersteller haben es in großem Umfang genutzt.
Toutiao verwendet ClickHouse intern zur Analyse des Benutzerverhaltens. Es gibt intern insgesamt Tausende von ClickHouse-Knoten, mit einem Maximum von 1.200 Knoten in einem einzelnen Cluster. Das Gesamtdatenvolumen beträgt Dutzende von PB und der tägliche Anstieg an Rohdaten Die Datenmenge beträgt ca. 300 TB.
Tencent nutzt ClickHouse intern zur Spieldatenanalyse und hat dafür ein vollständiges Überwachungs- und Betriebssystem etabliert.
Mit Beginn der Testversion im Juli 2018 hat Ctrip 80 % seines internen Geschäfts auf die ClickHouse-Datenbank migriert. Die Datenmengen nehmen täglich um mehr als eine Milliarde zu und es werden fast eine Million Abfrageanfragen gestellt.
Kuaishou nutzt ClickHouse auch intern. Die Gesamtspeicherkapazität beträgt etwa 10 PB, wobei jeden Tag 200 TB hinzugefügt werden und 90 % der Abfragen weniger als 3 Sekunden dauern.
Im Ausland verfügt Yandex über Hunderte von Knoten, mit denen das Klickverhalten der Benutzer analysiert wird, und auch führende Unternehmen wie CloudFlare und Spotify nutzen es.
ClickHouse wurde ursprünglich für die Entwicklung von YandexMetrica, der zweitgrößten Webanalyseplattform der Welt, entwickelt. Es wird seit vielen Jahren kontinuierlich als Kernkomponente des Systems eingesetzt.
1. Über die Nutzungspraxis von ClickHouse
Lassen Sie uns zunächst einige grundlegende Konzepte überprüfen:
OLTP: Es handelt sich um eine traditionelle relationale Datenbank, die hauptsächlich Ergänzungen, Löschungen, Änderungen und Abfragen durchführt und betont die Transaktionskonsistenz, z. B. Bankensystem, E-Commerce-System.OLTP:是传统的关系型数据库,主要操作增删改查,强调事务一致性,比如银行系统、电商系统。OLAP
OLAP: Es handelt sich um eine Warehouse-Datenbank, die hauptsächlich Daten liest, komplexe Datenanalysen durchführt, sich auf technische Entscheidungsunterstützung konzentriert und intuitive und einfache Ergebnisse liefert.
1.1. ClickHouse wird auf Data-Warehouse-Szenarien angewendet- ClickHouse ist eine spaltenorientierte Datenbank, die besser für OLAP-Szenarien geeignet ist:
- Die meisten davon sind Leseanfragen
- Datenaktualisierung in relativ großen Stapeln (>1000 Zeilen) statt einer einzelnen Zeile oder gar keiner Aktualisierung;
- Zur Datenbank hinzugefügte Daten können nicht geändert werden.
- Bei Lesevorgängen werden einige Zeilen aus der Datenbank abgerufen, aber nur ein kleiner Teil der Spalten.
- Breite Tabellen, d. h. jede Tabelle enthält eine große Anzahl von Spalten
- Relativ wenige Abfragen (normalerweise Hunderte oder weniger pro Sekunde und Server)
- Bei einfachen Abfragen ist eine Verzögerung von etwa 50 Millisekunden einzukalkulieren
- Daten in Spalten sind relativ klein: Zahlen und kurze Zeichenfolgen (z. B. 60 Bytes pro URL)
- Bei der Verarbeitung einer einzelnen Abfrage ist ein hoher Durchsatz erforderlich (bis zu 1 Sekunde pro Server, Milliarden Zeilen)
- Transaktionen sind nicht erforderlich
- Geringe Anforderungen an die Datenkonsistenz
- Eine große Tabelle pro Abfrage. Außer ihm sind alle anderen klein.
- Clickhouse Das Client-Tool ist dbeaver und die offizielle Website ist https://dbeaver .io/.
- dbeaver ist ein kostenloses und universelles Open-Source-Datenbanktool (GPL) für Entwickler und Datenbankadministratoren. [Baidu-Enzyklopädie]
- Das Hauptziel dieses Projekts besteht darin, die Benutzerfreundlichkeit zu verbessern. Deshalb haben wir speziell ein Datenbankverwaltungstool entworfen und entwickelt. Kostenlos, plattformübergreifend, basiert auf einem Open-Source-Framework und ermöglicht das Schreiben verschiedener Erweiterungen (Plug-Ins).
- Es unterstützt jede Datenbank mit einem JDBC-Treiber.
 Erstellen und konfigurieren Sie eine neue Verbindung über „Datenbank“ im Menü der Bedienoberfläche, wie in der Abbildung unten gezeigt, wählen Sie den ClickHouse-Treiber aus und laden Sie ihn herunter (standardmäßig ist kein Treiber vorhanden).
Erstellen und konfigurieren Sie eine neue Verbindung über „Datenbank“ im Menü der Bedienoberfläche, wie in der Abbildung unten gezeigt, wählen Sie den ClickHouse-Treiber aus und laden Sie ihn herunter (standardmäßig ist kein Treiber vorhanden).
jdbc:clickhouse://192.168.17.61:8123Wie in der Abbildung unten gezeigt.
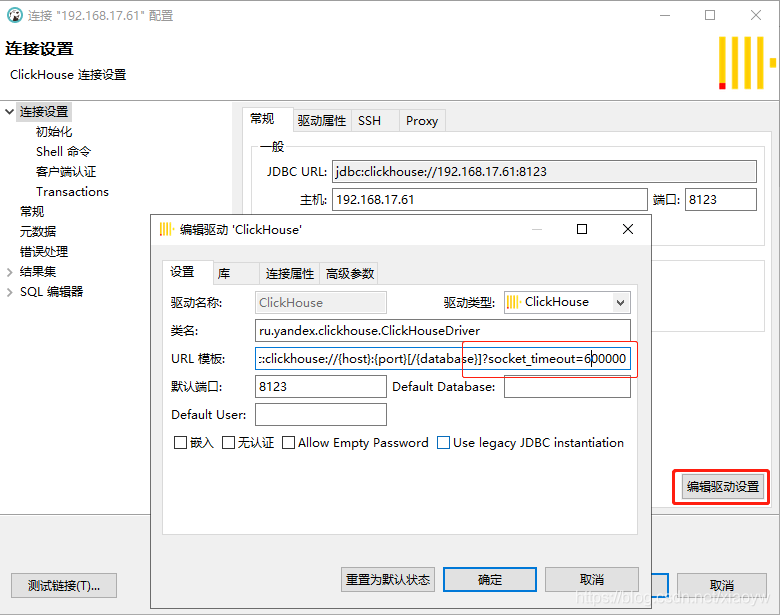 Bei der Verwendung von DBeaver zum Herstellen einer Verbindung zu Clickhouse zur Abfrage kommt es manchmal zu einer Zeitüberschreitung der Verbindung oder Abfrage. Zu diesem Zeitpunkt können Sie den Parameter socket_timeout in den Verbindungsparametern hinzufügen und festlegen, um das Problem zu lösen.
Bei der Verwendung von DBeaver zum Herstellen einer Verbindung zu Clickhouse zur Abfrage kommt es manchmal zu einer Zeitüberschreitung der Verbindung oder Abfrage. Zu diesem Zeitpunkt können Sie den Parameter socket_timeout in den Verbindungsparametern hinzufügen und festlegen, um das Problem zu lösen.
jdbc:clickhouse://{host}:{port}[/{database}]?socket_timeout=600000
- 1.3. Big-Data-Anwendungspraxis
- Kurze Beschreibung der Umgebung:
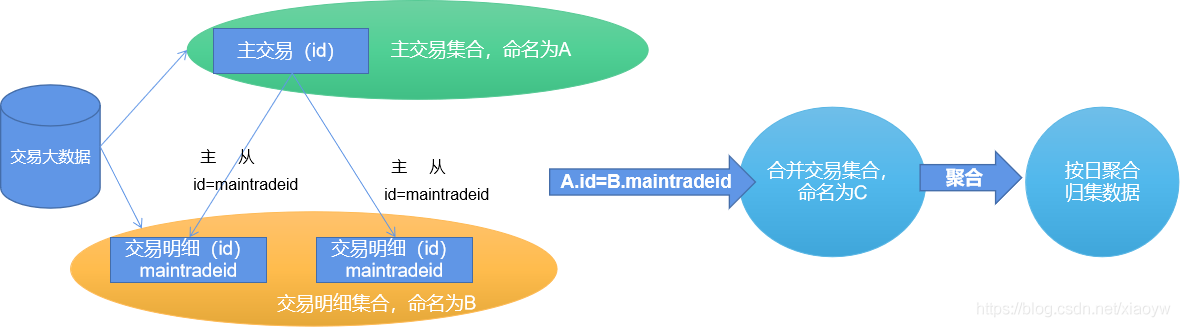 Um das Handelsverhalten der Kunden zu analysieren, werden unter den Bedingungen begrenzter Ressourcen Transaktionsdetails extrahiert und nach Tag und Handelspunkt in Transaktionsdatensätzen zusammengestellt, wie in der Abbildung unten dargestellt.
Um das Handelsverhalten der Kunden zu analysieren, werden unter den Bedingungen begrenzter Ressourcen Transaktionsdetails extrahiert und nach Tag und Handelspunkt in Transaktionsdatensätzen zusammengestellt, wie in der Abbildung unten dargestellt.
其中,在ClickHouse上,交易数据结构由60个列(字段)组成,截取部分如下所示:
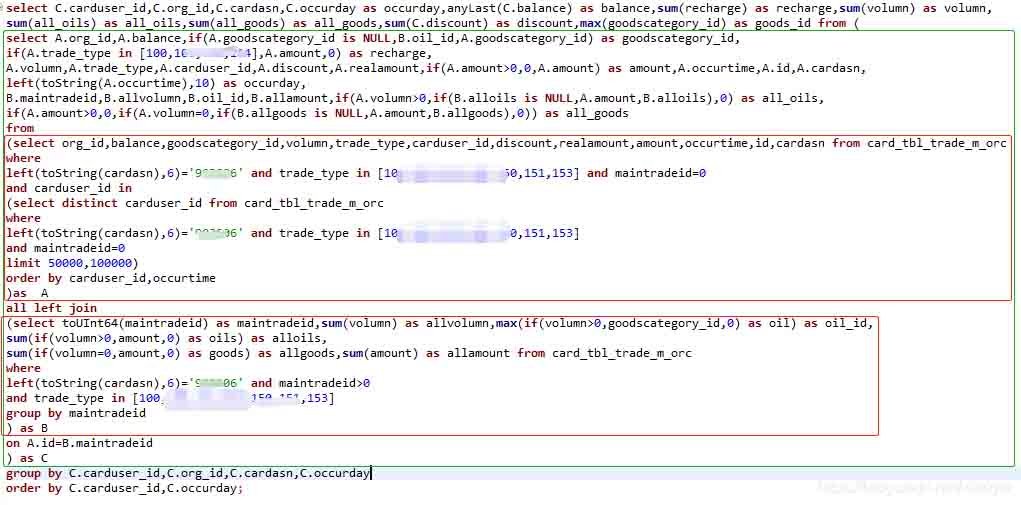
针对频繁出现“would use 10.20 GiB , maximum: 9.31 GiB”等内存不足的情况,基于ClickHouse的SQL,编写了提取聚合数据集SQL语句,如下所示。
大约60s返回结果,如下所示:

2. Python使用ClickHouse实践
2.1. ClickHouse第三方Python驱动clickhouse_driver
ClickHouse没有提供官方Python接口驱动,常用第三方驱动接口为clickhouse_driver,可以使用pip方式安装,如下所示:
pip install clickhouse_driver
Collecting clickhouse_driver
Downloading https://files.pythonhosted.org/packages/88/59/c570218bfca84bd0ece896c0f9ac0bf1e11543f3c01d8409f5e4f801f992/clickhouse_driver-0.2.1-cp36-cp36m-win_amd64.whl (173kB)
100% |████████████████████████████████| 174kB 27kB/s
Collecting tzlocal<3.0 (from clickhouse_driver)
Downloading https://files.pythonhosted.org/packages/5d/94/d47b0fd5988e6b7059de05720a646a2930920fff247a826f61674d436ba4/tzlocal-2.1-py2.py3-none-any.whl
Requirement already satisfied: pytz in d:\python\python36\lib\site-packages (from clickhouse_driver) (2020.4)
Installing collected packages: tzlocal, clickhouse-driver
Successfully installed clickhouse-driver-0.2.1 tzlocal-2.1使用的client api不能用了,报错如下:
File "clickhouse_driver\varint.pyx", line 62, in clickhouse_driver.varint.read_varint
File "clickhouse_driver\bufferedreader.pyx", line 55, in clickhouse_driver.bufferedreader.BufferedReader.read_one
File "clickhouse_driver\bufferedreader.pyx", line 240, in clickhouse_driver.bufferedreader.BufferedSocketReader.read_into_buffer
EOFError: Unexpected EOF while reading bytes
Python驱动使用ClickHouse端口9000。
ClickHouse服务器和客户端之间的通信有两种协议:http(端口8123)和本机(端口9000)。DBeaver驱动配置使用jdbc驱动方式,端口为8123。
ClickHouse接口返回数据类型为元组,也可以返回Pandas的DataFrame,本文代码使用的为返回DataFrame。
collection = self.client.query_dataframe(self.query_sql)
2.2. 实践程序代码
由于我本机最初资源为8G内存(现扩到16G),以及实际可操作性,分批次取数据保存到多个文件中,每个文件大约为1G。
# -*- coding: utf-8 -*-
'''
Created on 2021年3月1日
@author: xiaoyw
'''
import pandas as pd
import json
import numpy as np
import datetime
from clickhouse_driver import Client
#from clickhouse_driver import connect
# 基于Clickhouse数据库基础数据对象类
class DB_Obj(object):
'''
192.168.17.61:9000
ebd_all_b04.card_tbl_trade_m_orc
'''
def __init__(self, db_name):
self.db_name = db_name
host='192.168.17.61' #服务器地址
port ='9000' #'8123' #端口
user='***' #用户名
password='***' #密码
database=db_name #数据库
send_receive_timeout = 25 #超时时间
self.client = Client(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
#self.conn = connect(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
def setPriceTable(self,df):
self.pricetable = df
def get_trade(self,df_trade,filename):
print('Trade join price!')
df_trade = pd.merge(left=df_trade,right=self.pricetable[['occurday','DIM_DATE','END_DATE','V_0','V_92','V_95','ZDE_0','ZDE_92',
'ZDE_95']],how="left",on=['occurday'])
df_trade.to_csv(filename,mode='a',encoding='utf-8',index=False)
def get_datas(self,query_sql):
n = 0 # 累计处理卡客户数据
k = 0 # 取每次DataFrame数据量
batch = 100000 #100000 # 分批次处理
i = 0 # 文件标题顺序累加
flag=True # 数据处理解释标志
filename = 'card_trade_all_{}.csv'
while flag:
self.query_sql = query_sql.format(n, n+batch)
print('query started')
collection = self.client.query_dataframe(self.query_sql)
print('return query result')
df_trade = collection #pd.DataFrame(collection)
i=i+1
k = len(df_trade)
if k > 0:
self.get_trade(df_trade, filename.format(i))
n = n + batch
if k == 0:
flag=False
print('Completed ' + str(k) + 'trade details!')
print('Usercard count ' + str(n) )
return n
# 价格变动数据集
class Price_Table(object):
def __init__(self, cityname, startdate):
self.cityname = cityname
self.startdate = startdate
self.filename = 'price20210531.csv'
def get_price(self):
df_price = pd.read_csv(self.filename)
......
self.price_table=self.price_table.append(data_dict, ignore_index=True)
print('generate price table!')
class CardTradeDB(object):
def __init__(self,db_obj):
self.db_obj = db_obj
def insertDatasByCSV(self,filename):
# 存在数据混合类型
df = pd.read_csv(filename,low_memory=False)
# 获取交易记录
def getTradeDatasByID(self,ID_list=None):
# 字符串过长,需要使用'''
query_sql = '''select C.carduser_id,C.org_id,C.cardasn,C.occurday as
......
limit {},{})
group by C.carduser_id,C.org_id,C.cardasn,C.occurday
order by C.carduser_id,C.occurday'''
n = self.db_obj.get_datas(query_sql)
return n
if __name__ == '__main__':
PTable = Price_Table('湖北','2015-12-01')
PTable.get_price()
db_obj = DB_Obj('ebd_all_b04')
db_obj.setPriceTable(PTable.price_table)
CTD = CardTradeDB(db_obj)
df = CTD.getTradeDatasByID()返回本地文件为:
3. 小结一下
ClickHouse运用于OLAP场景时,拥有出色的查询速度,但需要具备大内存支持。Python第三方clickhouse-driver 驱动基本满足数据处理需求,如果能返回Pandas DataFrame最好。
ClickHouse和Pandas聚合都是非常快的,ClickHouse聚合函数也较为丰富(例如文中anyLast(x)返回最后遇到的值),如果能通过SQL聚合的,还是在ClickHouse中完成比较理想,把更小的结果集反馈给Python进行机器学习。
操作ClickHouse删除指定数据
def info_del2(i):
client = click_client(host='地址', port=端口, user='用户名', password='密码',
database='数据库')
sql_detail='alter table SS_GOODS_ORDER_ALL delete where order_id='+str(i)+';'
try:
client.execute(sql_detail)
except Exception as e:
print(e,'删除商品数据失败')在进行数据删除的时候,python操作clickhou和mysql的方式不太一样,这里不能使用以往常用的%s然后添加数据的方式,必须完整的编辑一条语句,如同上面方法所写的一样,传进去的参数统一使用str类型
Das obige ist der detaillierte Inhalt vonSo verwenden Sie ClickHouse in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!