
Heim >Backend-Entwicklung >Python-Tutorial >Welche drei Möglichkeiten gibt es, Python-Bilder zu speichern und darauf zuzugreifen?
Welche drei Möglichkeiten gibt es, Python-Bilder zu speichern und darauf zuzugreifen?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-16 21:08:301790Durchsuche
Vorwort
ImageNet ist eine bekannte öffentliche Bilddatenbank, die zum Trainieren von Modellen für Aufgaben wie Objektklassifizierung, -erkennung und -segmentierung verwendet wird. Sie enthält mehr als 14 Millionen Bilder.
Bei der Verarbeitung von Bilddaten in Python kann beispielsweise die Anwendung von Algorithmen wie dem Convolutional Neural Network (auch CNN genannt) eine große Anzahl von Bilddatensätzen verarbeiten. Hier müssen Sie lernen, wie Sie Daten auf einfachste Weise speichern und lesen.
Es sollte eine quantitative Möglichkeit geben, die Bilddatenverarbeitung zu vergleichen, wie lange das Lesen und Schreiben von Dateien dauert und wie viel Festplattenspeicher verwendet wird.
Verwenden Sie verschiedene Methoden, um die Probleme der Bildspeicherung und Leistungsoptimierung zu verarbeiten und zu lösen.
Datenvorbereitung
Ein Datensatz zum Spielen
Der uns bekannte Bilddatensatz CIFAR-10 besteht aus 60.000 32x32 Pixel großen Farbbildern, die zu verschiedenen Objektkategorien wie Hunden, Katzen und Flugzeugen gehören. CIFAR ist relativ gesehen kein sehr großer Datensatz, aber die Verwendung des vollständigen TinyImages-Datensatzes würde etwa 400 GB freien Speicherplatz erfordern.
Die vom Code im Artikel verwendete Datensatz-Download-Adresse ist der CIFAR-10-Datensatz.
Diese Daten werden mit cPickle serialisiert und stapelweise gespeichert. Das Pickle-Modul kann jedes Objekt in Python serialisieren, ohne dass zusätzlicher Code oder eine Konvertierung erforderlich ist. Allerdings können bei der Verarbeitung großer Datenmengen nicht abschätzbare Sicherheitsrisiken bestehen.
Bilder werden in NumPy-Arrays geladen
import numpy as np
import pickle
from pathlib import Path
# 文件路径
data_dir = Path("data/cifar-10-batches-py/")
# 解码功能
def unpickle(file):
with open(file, "rb") as fo:
dict = pickle.load(fo, encoding="bytes")
return dict
images, labels = [], []
for batch in data_dir.glob("data_batch_*"):
batch_data = unpickle(batch)
for i, flat_im in enumerate(batch_data[b"data"]):
im_channels = []
# 每个图像都是扁平化的,通道按 R, G, B 的顺序排列
for j in range(3):
im_channels.append(
flat_im[j * 1024 : (j + 1) * 1024].reshape((32, 32))
)
# 重建原始图像
images.append(np.dstack((im_channels)))
# 保存标签
labels.append(batch_data[b"labels"][i])
print("加载 CIFAR-10 训练集:")
print(f" - np.shape(images) {np.shape(images)}")
print(f" - np.shape(labels) {np.shape(labels)}")Einstellungen für die Bildspeicherung
Installieren Sie die Drittanbieter-Bibliothek Pillow für die Bildverarbeitung.
pip install Pillow
LMDB
„Lightning Memory Mapped Database“ (LMDB) ist aufgrund seiner Geschwindigkeit und der Verwendung von Memory Mapped-Dateien auch als „Lightning Database“ bekannt. Es handelt sich um einen Schlüsselwertspeicher, nicht um eine relationale Datenbank.
Installieren Sie die Drittanbieter-Bibliothek lmdb für die Bildverarbeitung.
pip install lmdb
HDF5
HDF5 steht für Hierarchical Data Format, ein Dateiformat namens HDF4 oder HDF5. Dieses tragbare, kompakte wissenschaftliche Datenformat stammt vom National Center for Supercomputing Applications.
Installieren Sie die Drittanbieter-Bibliothek h6py für die Bildverarbeitung.
pip install h6py
Einzelbildspeicherung
3 verschiedene Möglichkeiten, Datenlesevorgänge durchzuführen
from pathlib import Path
disk_dir = Path("data/disk/")
lmdb_dir = Path("data/lmdb/")
hdf5_dir = Path("data/hdf5/")Gleichzeitig geladene Daten können separat in Ordnern erstellt und gespeichert werden
disk_dir.mkdir(parents=True, exist_ok=True) lmdb_dir.mkdir(parents=True, exist_ok=True) hdf5_dir.mkdir(parents=True, exist_ok=True)
Auf der Festplatte gespeichert
Verwenden Sie Pillow, um die Eingabe einzeln abzuschließen image image , im Speicher als NumPy-Array und mit der eindeutigen Bild-ID image_id benannt.
Einzelnes Bild auf der Festplatte gespeichert
from PIL import Image
import csv
def store_single_disk(image, image_id, label):
""" 将单个图像作为 .png 文件存储在磁盘上。
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
Image.fromarray(image).save(disk_dir / f"{image_id}.png")
with open(disk_dir / f"{image_id}.csv", "wt") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
writer.writerow([label])In LMDB speichern
LMDB ist ein Schlüssel-Wert-Paar-Speichersystem, bei dem jeder Eintrag als Byte-Array gespeichert wird, der Schlüssel die eindeutige Kennung jedes Bildes und der Wert das Bild ist selbst.
Sowohl Schlüssel als auch Werte sollten Zeichenfolgen sein. Eine häufige Verwendung besteht darin, den Wert in eine Zeichenfolge zu serialisieren und ihn dann beim Zurücklesen zu deserialisieren.
Die für die Rekonstruktion verwendete Bildgröße. Einige Datensätze können Bilder unterschiedlicher Größe enthalten und diese Methode wird verwendet.
class CIFAR_Image:
def __init__(self, image, label):
self.channels = image.shape[2]
self.size = image.shape[:2]
self.image = image.tobytes()
self.label = label
def get_image(self):
""" 将图像作为 numpy 数组返回 """
image = np.frombuffer(self.image, dtype=np.uint8)
return image.reshape(*self.size, self.channels)Einzelnes Bild in LMDB gespeichert
import lmdb
import pickle
def store_single_lmdb(image, image_id, label):
""" 将单个图像存储到 LMDB
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
map_size = image.nbytes * 10
# Create a new LMDB environment
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), map_size=map_size)
# Start a new write transaction
with env.begin(write=True) as txn:
# All key-value pairs need to be strings
value = CIFAR_Image(image, label)
key = f"{image_id:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close()HDF5 speichern
Eine HDF5-Datei kann mehrere Datensätze enthalten. Es können zwei Datensätze erstellt werden, einer für Bilder und einer für Metadaten.
import h6py
def store_single_hdf5(image, image_id, label):
""" 将单个图像存储到 HDF5 文件
参数:
---------------
image 图像数组, (32, 32, 3) 格式
image_id 图像的整数唯一 ID
label 图像标签
"""
# 创建一个新的 HDF5 文件
file = h6py.File(hdf5_dir / f"{image_id}.h6", "w")
# 在文件中创建数据集
dataset = file.create_dataset(
"image", np.shape(image), h6py.h6t.STD_U8BE, data=image
)
meta_set = file.create_dataset(
"meta", np.shape(label), h6py.h6t.STD_U8BE, data=label
)
file.close()Speichervergleich
Fügen Sie alle drei Funktionen, die ein einzelnes Bild speichern, in ein Wörterbuch ein.
_store_single_funcs = dict(
disk=store_single_disk,
lmdb=store_single_lmdb,
hdf5=store_single_hdf5
)Speichern Sie das erste Bild in CIFAR und die entsprechenden Tags auf drei verschiedene Arten.
from timeit import timeit
store_single_timings = dict()
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_single_funcs[method](image, 0, label)",
setup="image=images[0]; label=labels[0]",
number=1,
globals=globals(),
)
store_single_timings[method] = t
print(f"存储方法: {method}, 使用耗时: {t}")Schauen wir uns den Vergleich an.
| Speichermethode | Speicherzeit | Speichernutzung |
|---|---|---|
| Festplatte | 2,1 ms | 8 K |
| LMDB | 1,7. ms | 32K |
| HDF5 | 8,1 ms | 8 K |
Speicherung mehrerer Bilder
Ähnlich wie bei der Einzelbildspeichermethode ändern Sie den Code, um mehrere Bilddaten zu speichern.
Mehrfachbild-Anpassungscode
Das Speichern mehrerer Bilder als PNG-Dateien kann als mehrmaliger Aufruf der Methode „store_single_method()“ angesehen werden. Dieser Ansatz ist mit LMDB oder HDF5 nicht möglich, da jedes Bild in einer anderen Datenbankdatei vorhanden ist.
Speichern Sie eine Reihe von Bildern auf der Festplatte.
store_many_disk(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
# 一张一张保存所有图片
for i, image in enumerate(images):
Image.fromarray(image).save(disk_dir / f"{i}.png")
# 将所有标签保存到 csv 文件
with open(disk_dir / f"{num_images}.csv", "w") as csvfile:
writer = csv.writer(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
for label in labels:
writer.writerow([label]).Speichern Sie eine Reihe von Bildern in LMDB.
def store_many_lmdb(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
map_size = num_images * images[0].nbytes * 10
# 为所有图像创建一个新的 LMDB 数据库
env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), map_size=map_size)
# 在一个事务中写入所有图像
with env.begin(write=True) as txn:
for i in range(num_images):
# 所有键值对都必须是字符串
value = CIFAR_Image(images[i], labels[i])
key = f"{i:08}"
txn.put(key.encode("ascii"), pickle.dumps(value))
env.close().Speichern Sie eine Reihe von Bildern in HDF5
def store_many_hdf5(images, labels):
""" 参数:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
num_images = len(images)
# 创建一个新的 HDF5 文件
file = h6py.File(hdf5_dir / f"{num_images}_many.h6", "w")
# 在文件中创建数据集
dataset = file.create_dataset(
"images", np.shape(images), h6py.h6t.STD_U8BE, data=images
)
meta_set = file.create_dataset(
"meta", np.shape(labels), h6py.h6t.STD_U8BE, data=labels
)
file.close()PLOT Zeigt ein einzelnes Diagramm mit mehreren Datensätzen und passenden Legenden an
cutoffs = [10, 100, 1000, 10000, 100000] images = np.concatenate((images, images), axis=0) labels = np.concatenate((labels, labels), axis=0) # 确保有 100,000 个图像和标签 print(np.shape(images)) print(np.shape(labels))
Lesen eines einzelnen Bildes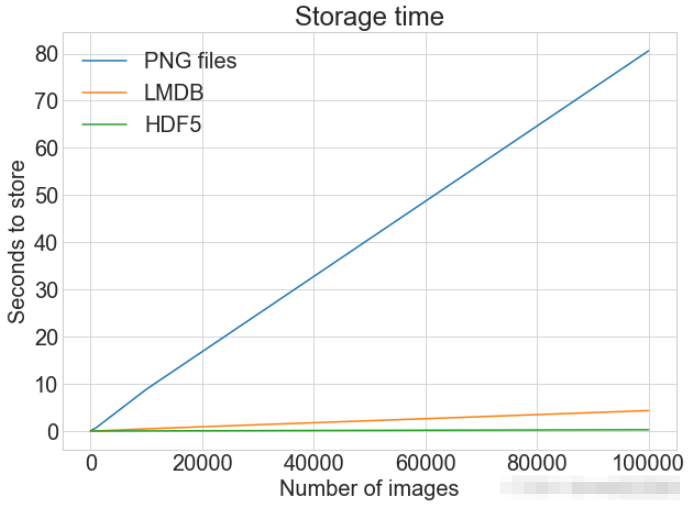
_store_many_funcs = dict(
disk=store_many_disk, lmdb=store_many_lmdb, hdf5=store_many_hdf5
)
from timeit import timeit
store_many_timings = {"disk": [], "lmdb": [], "hdf5": []}
for cutoff in cutoffs:
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_store_many_funcs[method](images_, labels_)",
setup="images_=images[:cutoff]; labels_=labels[:cutoff]",
number=1,
globals=globals(),
)
store_many_timings[method].append(t)
# 打印出方法、截止时间和使用时间
print(f"Method: {method}, Time usage: {t}")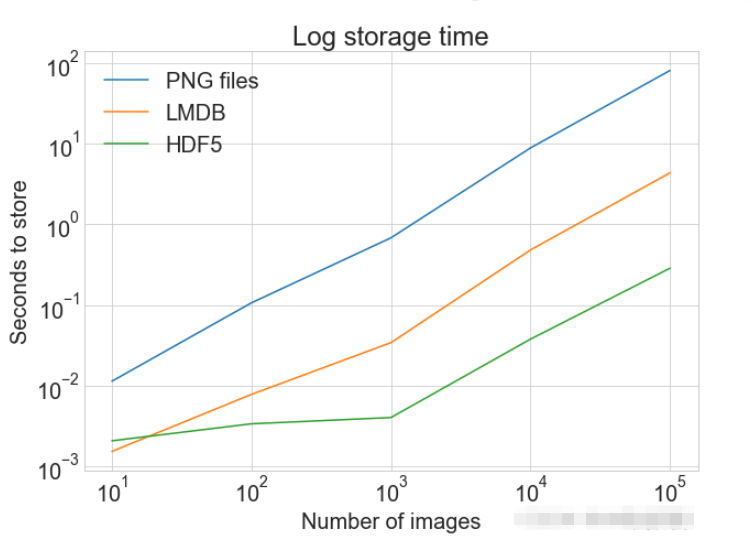 Lesen von LMDB
Lesen von LMDB import matplotlib.pyplot as plt
def plot_with_legend(
x_range, y_data, legend_labels, x_label, y_label, title, log=False
):
""" 参数:
--------------
x_range 包含 x 数据的列表
y_data 包含 y 值的列表
legend_labels 字符串图例标签列表
x_label x 轴标签
y_label y 轴标签
"""
plt.style.use("seaborn-whitegrid")
plt.figure(figsize=(10, 7))
if len(y_data) != len(legend_labels):
raise TypeError(
"数据集的数量与标签的数量不匹配"
)
all_plots = []
for data, label in zip(y_data, legend_labels):
if log:
temp, = plt.loglog(x_range, data, label=label)
else:
temp, = plt.plot(x_range, data, label=label)
all_plots.append(temp)
plt.title(title)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.legend(handles=all_plots)
plt.show()
# Getting the store timings data to display
disk_x = store_many_timings["disk"]
lmdb_x = store_many_timings["lmdb"]
hdf5_x = store_many_timings["hdf5"]
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Storage time",
log=False,
)
plot_with_legend(
cutoffs,
[disk_x, lmdb_x, hdf5_x],
["PNG files", "LMDB", "HDF5"],
"Number of images",
"Seconds to store",
"Log storage time",
log=True,
)Lesen von HDF5
def read_single_disk(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
image = np.array(Image.open(disk_dir / f"{image_id}.png"))
with open(disk_dir / f"{image_id}.csv", "r") as csvfile:
reader = csv.reader(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
label = int(next(reader)[0])
return image, labelLesemethode Vergleich
def read_single_lmdb(image_id):
""" 参数:
---------------
image_id 图像的整数唯一 ID
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
# 打开 LMDB 环境
env = lmdb.open(str(lmdb_dir / f"single_lmdb"), readonly=True)
# 开始一个新的事务
with env.begin() as txn:
# 进行编码
data = txn.get(f"{image_id:08}".encode("ascii"))
# 加载的 CIFAR_Image 对象
cifar_image = pickle.loads(data)
# 检索相关位
image = cifar_image.get_image()
label = cifar_image.label
env.close()
return image, label
SpeichermethodeSpeicherzeit | Disk | 1,7 ms |
|---|---|
| LMDB | 4.4. ms |
| HD F5 | 2,3 ms |
多个图像的读取可以将多个图像保存为.png文件,这等价于多次调用 read_single_method()。这并不适用于 LMDB 或 HDF5,因为每个图像都储存在不同的数据库文件中。 多图像调整代码从磁盘中读取多个都图像 def read_many_disk(num_images):
""" 参数:
---------------
num_images 要读取的图像数量
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
images, labels = [], []
# 循环遍历所有ID,一张一张地读取每张图片
for image_id in range(num_images):
images.append(np.array(Image.open(disk_dir / f"{image_id}.png")))
with open(disk_dir / f"{num_images}.csv", "r") as csvfile:
reader = csv.reader(
csvfile, delimiter=" ", quotechar="|", quoting=csv.QUOTE_MINIMAL
)
for row in reader:
labels.append(int(row[0]))
return images, labels从LMDB中读取多个都图像 def read_many_lmdb(num_images):
""" 参数:
---------------
num_images 要读取的图像数量
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
images, labels = [], []
env = lmdb.open(str(lmdb_dir / f"{num_images}_lmdb"), readonly=True)
# 开始一个新的事务
with env.begin() as txn:
# 在一个事务中读取,也可以拆分成多个事务分别读取
for image_id in range(num_images):
data = txn.get(f"{image_id:08}".encode("ascii"))
# CIFAR_Image 对象,作为值存储
cifar_image = pickle.loads(data)
# 检索相关位
images.append(cifar_image.get_image())
labels.append(cifar_image.label)
env.close()
return images, labels从HDF5中读取多个都图像 def read_many_hdf5(num_images):
""" 参数:
---------------
num_images 要读取的图像数量
返回结果:
---------------
images 图像数组 (N, 32, 32, 3) 格式
labels 标签数组 (N,1) 格式
"""
images, labels = [], []
# 打开 HDF5 文件
file = h6py.File(hdf5_dir / f"{num_images}_many.h6", "r+")
images = np.array(file["/images"]).astype("uint8")
labels = np.array(file["/meta"]).astype("uint8")
return images, labels
_read_many_funcs = dict(
disk=read_many_disk, lmdb=read_many_lmdb, hdf5=read_many_hdf5
)准备数据集对比创建一个计算方式进行对比 from timeit import timeit
read_many_timings = {"disk": [], "lmdb": [], "hdf5": []}
for cutoff in cutoffs:
for method in ("disk", "lmdb", "hdf5"):
t = timeit(
"_read_many_funcs[method](num_images)",
setup="num_images=cutoff",
number=1,
globals=globals(),
)
read_many_timings[method].append(t)
# Print out the method, cutoff, and elapsed time
print(f"读取方法: {method}, No. images: {cutoff}, 耗时: {t}")
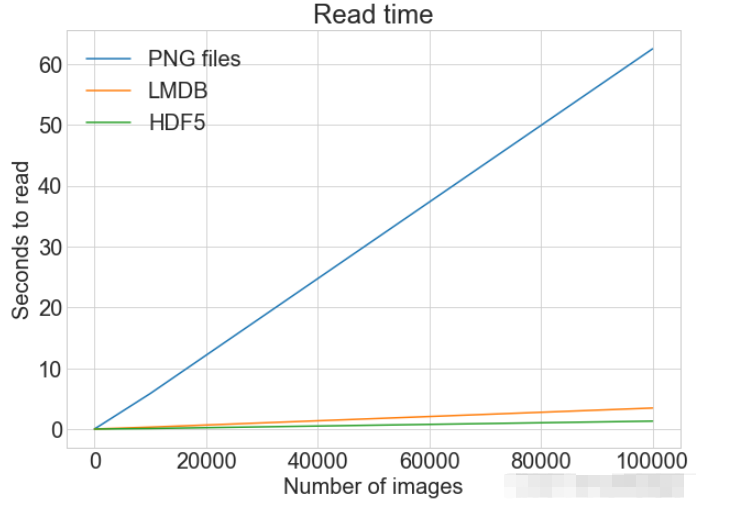
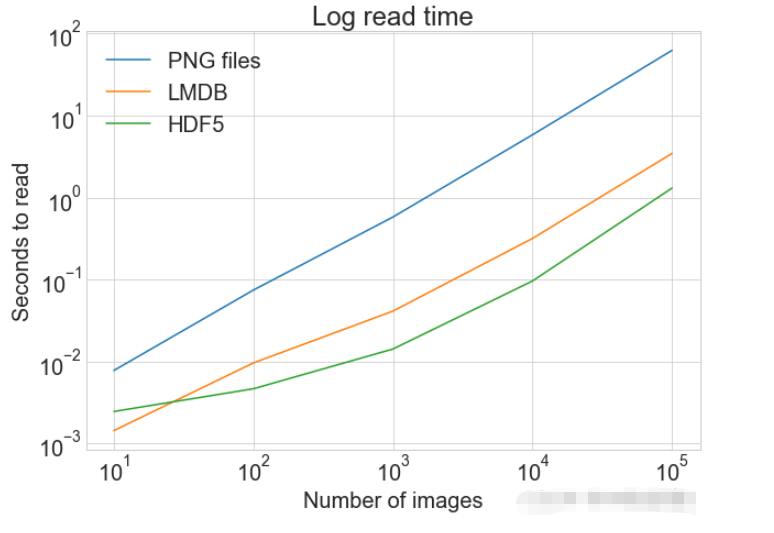
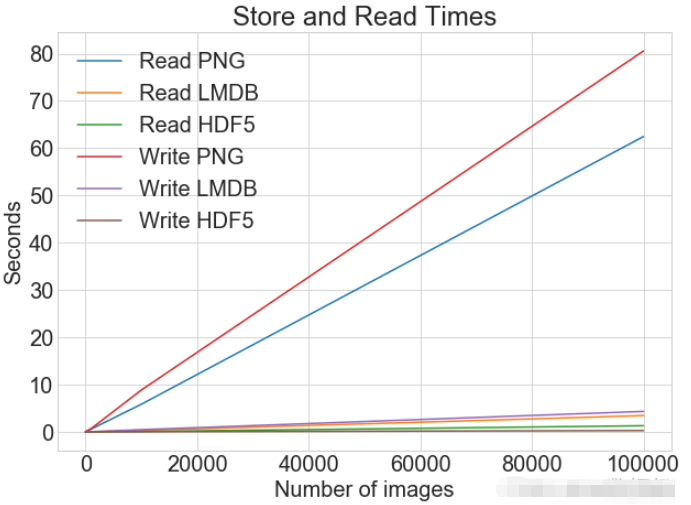
读写操作综合比较数据对比同一张图表上查看读取和写入时间 plot_with_legend(
cutoffs,
[disk_x_r, lmdb_x_r, hdf5_x_r, disk_x, lmdb_x, hdf5_x],
[
"Read PNG",
"Read LMDB",
"Read HDF5",
"Write PNG",
"Write LMDB",
"Write HDF5",
],
"Number of images",
"Seconds",
"Log Store and Read Times",
log=False,
)
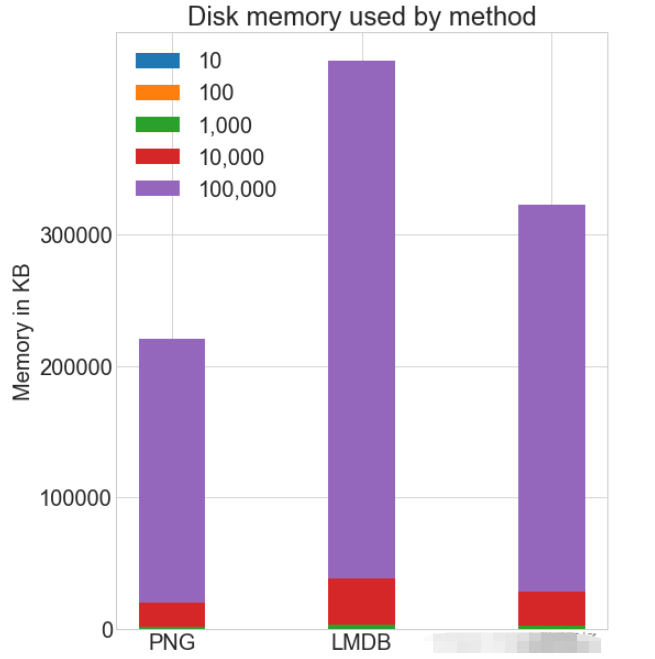
各种存储方式使用磁盘空间
虽然 HDF5 和 LMDB 都占用更多的磁盘空间。需要注意的是 LMDB 和 HDF5 磁盘的使用和性能在很大程度上取决于各种因素,包括操作系统,更重要的是存储的数据大小。 并行操作通常对于大的数据集,可以通过并行化来加速操作。 也就是我们经常说的并发处理。 作为.png 文件存储到磁盘实际上允许完全并发。可通过使用不同的图像名称,实现从多个线程读取多个图像,或一次性写入多个文件。 如果将所有 CIFAR 分成十组,那么可以为一组中的每个读取设置十个进程,并且相应的处理时间可以减少到原来的10%左右。 |
Das obige ist der detaillierte Inhalt vonWelche drei Möglichkeiten gibt es, Python-Bilder zu speichern und darauf zuzugreifen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!