
Heim >Java >javaLernprogramm >So realisieren Sie die MySQL-Lese- und Schreibtrennung im SpringBoot-Projekt
So realisieren Sie die MySQL-Lese- und Schreibtrennung im SpringBoot-Projekt

- PHPznach vorne
- 2023-05-16 13:31:061747Durchsuche
1. MySQL-Master-Slave-Replikation
Aber wenn wir genau hinsehen, werden wir feststellen, dass es folgende Probleme geben kann, wenn unsere Projekte alle eine einzige Datenbank verwenden:
-
Alles lesen und schreiben Der gesamte Druck wird von einer einzigen Datenbank getragen Oben können wir zwei (mehr) vorbereiten: Einen MySQL-, einen Master-Server (Master) und einen Slave-Server (
Slave ). Die - Datenänderungen
(Schreiben, Aktualisieren, Löschen dieser Vorgänge) der Master-Datenbank sind erforderlich synchronisiert werden mit der Slave-Datenbank (Master kopiert von). Wenn der Benutzer auf unser Projekt zugreift und es sich um einen „Schreibvorgang“ (Einfügen, Aktualisieren, Löschen) handelt, wird die „Hauptbibliothek“ direkt bedient. Wenn es sich um einen „Lesevorgang“ (Auswählen) handelt, wird die Slave-Bibliothek direkt bedient Diese Struktur ist Trennung von Lesen und Schreiben
.
In dieser Lese-/Schreib-Trennstruktur kann es mehrere Slave-Bibliotheken geben MySQL-Master-Slave-Replikation ist ein asynchroner-Replikationsprozess Binärprotokoll-Funktion. Das bedeutet, dass eine oder mehrere MySQL-Datenbanken (Slave, also Slave-Datenbank) das Protokoll von einer anderen MySQL-Datenbank (Master, also Hauptdatenbank) kopieren und dann das Protokoll analysieren und auf sich selbst anwenden Endlich erreicht von Die Daten der Bibliothek stimmen mit den Daten der Hauptbibliothek überein. Die MySQL-Master-Slave-Replikation ist eine integrierte Funktion der MySQL-Datenbank und erfordert keine Verwendung von Tools von Drittanbietern.
Binärprotokoll: 
MySQL-Master schreibt Datenänderungen in das Binärprotokoll (Binärprotokoll)Slave kopiert das Binärprotokoll des Masters in sein Relay-Protokoll (Relaisprotokoll). )
Slave-Redo-Ereignisse im Relay-Protokoll und spiegeln die Datenänderungen an den eigenen Daten wider- 1.2 Master-Slave-Bibliotheksaufbau
Bevor wir die Umgebung einrichten, müssen wir zwei Server vorbereiten. Wenn Ihr Leben umfangreich ist und Sie zwei Cloud-Server verwenden, denken Sie daran, die Sicherheitsgruppe, d Bluescreen (fragen Sie nicht, woher Sie das wissen)Ich werde Ihnen hier nicht die Installation der Datenbank und den Betrieb der Firewall zeigen. Ich habe das Gefühl, dass es im Internet viele Ressourcen gibt, die die aufgetretenen Probleme lösen können Beim Erstellen der Master-Slave-Bibliothek habe ich nicht viel darauf geachtet, dass sie konsistent ist. Sie können sie selbst überprüfen.
1.2.1. Hauptbibliothekskonfiguration-
Server: 192.168.150.100 (versuchen Sie nicht, es zu hacken, es ist die IP der virtuellen Maschine)
1. Ändern Sie die Konfigurationsdatei der MySQL-Datenbank vim /etc/my .cnf 在打开的文件中加入下面两行,其中的server-id不一定是100,确保唯一即可 log-bin=mysql-bin #[必须]启用二进制日志 server-id=100 #[必须]服务器唯一ID
2. Starten Sie den MySQL-Dienst neu. Es gibt drei Methoden, um MySQL neu zu starten: 
net stop mysql;net start mysql; systemctl restart mysqld service mysqld restart
3. Erstellen Sie einen Benutzer für die Datensynchronisierung und autorisieren Sie ihn
Sie können den folgenden Befehl nur ausführen, nachdem Sie sich bei MySQL angemeldet haben, da es sich um einen SQL-Befehl handelt und Linux nicht weiß, was er ist.GRANT REPLICATION SLAVE ON *.* to '用户名'@'开放的地址' identified by '密码'; eg: GRANT REPLICATION SLAVE ON *.* to 'masterDb'@'%' identified by 'Master@123456'; 记得刷一下权限 FLUSH PRIVILEGES;
4. Überprüfen Sie den Master-Synchronisationsstatus
Zu diesem Zeitpunkt besteht keine Notwendigkeit, MySQL zu beenden, da der folgende Befehl immer noch ein SQL-Befehl ist, können Sie die beiden wichtigen Parameter abrufen wir brauchen später.show master status;
Nach der Ausführung dieses SQL-Satzes == Betreiben Sie die Hauptdatenbank nicht erneut! Betreiben Sie die Hauptbibliothek nicht mehr! Betreiben Sie die Hauptbibliothek nicht mehr! ==Ich sage wichtige Dinge dreimal, da der Betrieb der Hauptbibliothek dazu führen kann, dass sich die 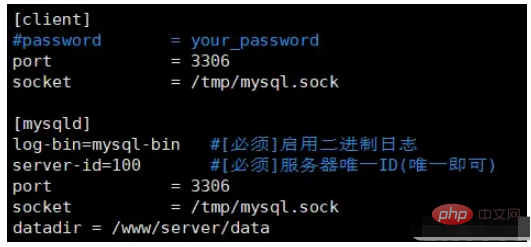 zwei Attributwerte im roten Feld ändern
zwei Attributwerte im roten Feld ändern
1.2.2、从库配置
服务器:192.168.150.101(别试了黑不了的,这也是虚拟机的ip)
1、 修改Mysql数据库的配置文件 vim /etc/my.cnf

这里要注意server-id和主库以及其他从库都不能相同,否则后面将会配置不成功。
2、重启Mysql服务
这里有三个方法都能重启MySQL,最简单的无疑就是一关一开:
net stop mysql;net start mysql; systemctl restart mysqld service mysqld restart
3、设置主库地址及同步位置
登录进去MySQL之后才能够执行下面的命令,因为这是SQL命令
设置主库地址和同步位置 change master to master_host='192.168.150.100',master_user='masterDb',master_password='Master@123456',master_log_file='mysql-bin.000010',master_log_pos=68479; 记得记得开启从库配置 start slave;
参数说明:
master_host: 主库的 IP地址
master_user: 访问主库进行主从复制的 用户名 ( 上面在主库创建的 )
master_password: 访问主库进行主从复制的用户名对应的 密码
master_log_file: 从哪个 日志文件 开始同步 ( 即1.2.1中第4步获取的 File )
master_log_pos: 从指定日志文件的哪个 位置 开始同步 ( 即1.2.1中第4步获取的 Position )
4、查看从数据库的状态
这个时候还 不用退出MySQL ,因为下面的命令还是SQL命令,执行下面的SQL,可以看到从库的状态信息。通过状态信息中的 Slave_IO_running 和 Slave_SQL_running 可以看出主从同步是否就绪,如果这两个参数全为 Yes ,表示主从同步已经配置完成。
show slave status\G;

1.3、坑位介绍
1.3.1、UUID报错
这可能是由于linux 是复制出来的,MySQL中还有一个 server_uuid 是一样的,我们也需要修改。 vim /var/lib/mysql/auto.cnf

1.3.2、server_id报错
这应该就是各位大牛设置server_id的时候不小心设置相同的id了,修改过来就行,步骤在上面的配置中。
1.3.3、同步异常解决
这是狗子在操作过程中搞出来的一个错误……
出错的原因是在主库中删除了用户信息,但是在从库中同步的时候失败导致同步停止,下面记录自己的操作(是在进入MySQL的操作且是从库)。
MASTER_LOG_POS
STOP SLAVE; SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1; START SLAVE; SHOW SLAVE STATUS\G;
在数据库中操作时,一定要注意当前所在的数据库是哪个,作为一个良好的实践:在SQL语句前加 USE dbname 。
操作不规范,亲人两行泪……
2、项目中实现
2.1、ShardingJDBC
Sharding-JDBC定位为 轻量级Java框架 ,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以 jar包 形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动, 完全兼容JDBC和各种ORM框架 。
使用Sharding-JDBC可以在程序中轻松的实现数据库 读写分离 。
Sharding-JDBC具有以下几个特点:
适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
下面我们将用ShardingJDBC在项目中实现MySQL的读写分离。
2.2、依赖导入
在pom.xml文件中导入ShardingJDBC的依赖坐标
<!--sharding-jdbc-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>2.3、配置文件
在application.yml中增加数据源的配置
spring:
shardingsphere:
datasource:
names:
master,slave
# 主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.150.100:3306/db_test?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
# 从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.150.101:3306/db_test?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
masterslave:
# 读写分离配置,设置负载均衡的模式为轮询
load-balance-algorithm-type: round_robin
# 最终的数据源名称
name: dataSource
# 主库数据源名称
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启SQL显示,默认false
# 覆盖注册bean,后面创建数据源会覆盖前面创建的数据源
main:
allow-bean-definition-overriding: true2.4、测试跑路
这时我们就可以对我们项目中的配置进行一个测试,下面分别调用一个更新接口和一个查询接口,通过查看日志中记录的数据源来判断是否能够按照我们预料中的跑。
更新操作(写操作)

查询操作(读操作)

Fertig! ! ! Das Programm lief wie erwartet normal und erfolgreich und nutzte ShardingJDBC erfolgreich, um die Trennung von Lesen und Schreiben der Datenbank in unserem Projekt zu realisieren.
Das obige ist der detaillierte Inhalt vonSo realisieren Sie die MySQL-Lese- und Schreibtrennung im SpringBoot-Projekt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!