
Heim >Betrieb und Instandhaltung >Sicherheit >Prozessanalyse von der Eingabe der URL bis zur endgültigen Browserdarstellung des Seiteninhalts
Prozessanalyse von der Eingabe der URL bis zur endgültigen Browserdarstellung des Seiteninhalts

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-16 11:28:121641Durchsuche
Vorbereitung
Wenn Sie die URL in den Browser eingeben (z. B. www.coder.com) und die Eingabetaste drücken, ist das Erste, was der Browser tut Die spezifische Methode besteht darin, ein UDP-Paket an den DNS-Server zu senden. Zu diesem Zeitpunkt speichert der Browser normalerweise die IP-Adresse Beim nächsten Mal kann darauf zugegriffen werden.
Zum Beispiel Chrome können Sie es über chrome://net-internals/#dns anzeigen.
Mit der IP des Servers kann der Browser HTTP-Anfragen initiieren, HTTP-Request/Response muss jedoch über die „virtuelle Verbindung“ von TCP gesendet und empfangen werden.
Um eine „virtuelle“ TCP-Verbindung herzustellen, muss TCP Postman vier Dinge wissen: (lokale IP, lokaler Port, Server-IP, Server-Port). Jetzt kennt er nur noch die lokale IP. Was ist mit dem Server? IP und zwei Ports?
Der lokale Port ist sehr einfach. Der Server-Port ist noch einfacher. Der HTTP-Dienst ist 80 Sagen Sie es einfach direkt dem TCP-Postboten.
Nach drei Handshakes ist die TCP-Verbindung zwischen Client und Server aufgebaut! Endlich können wir HTTP-Anfragen senden.

Der Grund, warum die TCP-Verbindung als gepunktete Linie dargestellt wird, liegt darin, dass diese Verbindung virtuell ist
Webserver
Eine HTTP-GET-Anfrage durchläuft Tausende von Kilometern und wird von mehreren Routern weitergeleitet, bevor sie schließlich den Server erreicht (HTTP-Pakete können fragmentiert sein und von der unteren Schicht übertragen werden, die weggelassen wird ).
Der Webserver muss mit der Verarbeitung beginnen. Es gibt drei Möglichkeiten, damit umzugehen:
(1) Ein Thread kann zur Bearbeitung aller Anfragen verwendet werden Es kann nur ein Thread gleichzeitig verwendet werden. Diese Struktur ist einfach zu implementieren, kann jedoch zu ernsthaften Leistungsproblemen führen.
(2) Für jede Anforderung kann ein Prozess/Thread zugewiesen werden. Wenn jedoch zu viele Verbindungen vorhanden sind, verbraucht der serverseitige Prozess/Thread viele Speicherressourcen und Prozesse /thread-Wechsel Es wird auch die CPU überlasten.
(3) Um E/A wiederzuverwenden, verwenden viele Webserver eine Wiederverwendungsstruktur. Beispielsweise werden alle Verbindungen über Epoll überwacht (wenn Daten verfügbar sind, Lesen). , verwenden Sie einen Prozess/Thread, um diese Verbindung zu verarbeiten, setzen Sie die Überwachung nach der Verarbeitung fort und warten Sie auf die nächste Statusänderung. Auf diese Weise können Tausende von Verbindungsanfragen mit einer kleinen Anzahl von Prozessen/Threads bearbeitet werden.
Wir verwenden Nginx, einen sehr beliebten Webserver, um die folgende Geschichte fortzusetzen.
Für die HTTP-GET-Anfrage verwendet Nginx epoll, um sie zu lesen. Als nächstes muss Nginx feststellen, ob es sich um eine statische oder eine dynamische Anfrage handelt.
Wenn es sich um eine statische Anfrage handelt (HTML-Datei, JavaScript-Datei, CSS-Datei, Bild usw.), können Sie diese möglicherweise selbst bearbeiten (natürlich hängt es von der Nginx-Konfiguration ab und möglicherweise auch). an andere Cache-Server weitergeleitet). Lesen Sie die relevanten Dateien auf der lokalen Festplatte und geben Sie sie direkt zurück.
Wenn es sich um eine dynamische Anfrage handelt, die vom Backend-Server (z. B. Tomcat) verarbeitet werden muss, bevor sie zurückgegeben werden kann, muss sie an Tomcat weitergeleitet werden. Wenn es mehr als einen Tomcat gibt Im Backend muss es nach einer bestimmten Strategie ausgewählt werden.
Zum Beispiel unterstützt Ngnix die folgenden Typen:
Es ist ersichtlich, dass Nginx in diesem Szenario die Rolle eines Agenten spielt.Polling: Nacheinander an den Backend-Server weiterleiten
Gewichtung : Geben Sie jedem Backend-Server eine Gewichtung, die der Wahrscheinlichkeit einer Weiterleitung an den Backend-Server entspricht.
ip_hash: Führen Sie eine Hash-Operation basierend auf der IP durch und suchen Sie dann einen Server, um sie weiterzuleiten. In diesem Fall wird dieselbe Client-IP immer an denselben Back-End-Server weitergeleitet.
fair: Ordnen Sie Anfragen basierend auf der Antwortzeit des Backend-Servers zu und priorisieren Sie den Antwortzeitraum. Unabhängig davon, welcher Algorithmus verwendet wird, wird schließlich ein Backend-Server ausgewählt, und dann muss Nginx die HTTP-Anfrage an das Backend Tomcat weiterleiten und die HttpResponse-Ausgabe von Tomcat an den Browser weiterleiten.
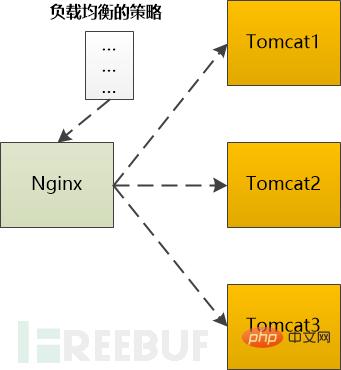
Anwendungsserver
 Http-Anfrage kam schließlich an Tomcat, einen Java-Server Ein Container, der für die Verarbeitung von Servlet/JSP geschrieben wurde. Unser Code wird in diesem Container ausgeführt.
Http-Anfrage kam schließlich an Tomcat, einen Java-Server Ein Container, der für die Verarbeitung von Servlet/JSP geschrieben wurde. Unser Code wird in diesem Container ausgeführt.
Wie der Webserver kann auch Tomcat jeder zu verarbeitenden Anforderung einen Thread zuweisen, was allgemein als BIO-Modus (Blocking I/O-Modus) bekannt ist. Es ist auch möglich, die I/O-Multiplexing-Technologie zu verwenden und nur wenige Threads zur Verarbeitung aller Anforderungen zu verwenden, also den NIO-Modus.
Egal welche Methode verwendet wird, die HTTP-Anfrage wird zur Verarbeitung an ein Servlet übergeben, und das Servlet konvertiert die HTTP-Anfrage in das vom Framework verwendete Parameterformat und verteilt sie dann an ein Controller (wenn Sie Spring verwenden) oder eine Aktion (wenn Sie Struts verwenden).
Der Rest der Geschichte ist relativ einfach (nein, für Programmierer ist es tatsächlich der komplizierteste Teil), nämlich die Logik zum Hinzufügen, Löschen, Ändern und Überprüfen auszuführen, die Programmierer in diesem Prozess häufig schreiben. Es ist sehr wahrscheinlich, dass es mit dem Cache, der Datenbank und anderen Back-End-Komponenten interagiert und schließlich eine HTTP-Antwort zurückgibt. Da die Details von der Geschäftslogik abhängen, werden sie weggelassen.
Nach unserem Beispiel sollte diese HTTP-Antwort eine HTML-Seite sein.
Zurück
Tomcat hat die HTTP-Antwort glücklich an Ngnix gesendet.
Ngnix sendet auch gerne die Http-Antwort an den Browser.

Kann die TCP-Verbindung nach dem Senden geschlossen werden?
Wenn Sie HTTP1.1 verwenden, ist diese Verbindung standardmäßig aufrechterhalten, was bedeutet, dass sie nicht geschlossen werden kann.
Wenn Sie HTTP1.0 verwenden, benötigen Sie Sehen Sie sich das vorherige HTTP an. Gibt es Connection:keep-alive im Request-Header? Wenn ja, kann es nicht deaktiviert werden.
Der Browser funktioniert wieder
Der Browser hat die HTTP-Antwort empfangen, die HTML-Seite daraus gelesen und mit den Vorbereitungen für die Anzeige der Seite begonnen .
Aber diese HTML-Seite verweist möglicherweise auf eine große Anzahl anderer Ressourcen, wie z. B. JS-Dateien, CSS-Dateien, Bilder usw. Diese Ressourcen befinden sich auch auf der Serverseite und können sich unter einem anderen Domänennamen befinden , wie zum Beispiel static.coder com.
Der Browser hat keine andere Wahl, als sie einzeln herunterzuladen. Beginnend mit der Verwendung von DNS zum Abrufen der IP müssen die zuvor durchgeführten Schritte erneut ausgeführt werden. Der Unterschied besteht darin, dass Anwendungsserver wie Tomcat nicht mehr eingreifen.
Wenn zu viele externe Ressourcen heruntergeladen werden müssen, erstellt der Browser mehrere TCP-Verbindungen und lädt sie parallel herunter.
Die Anzahl der gleichzeitigen Anfragen an denselben Domainnamen darf jedoch nicht zu hoch sein, da der Server sonst zu viel Verkehr hat und unerträglich wird. Daher müssen Browser sich selbst einschränken. Beispielsweise kann Chrome unter Http1.1 nur 6 Ressourcen gleichzeitig herunterladen.
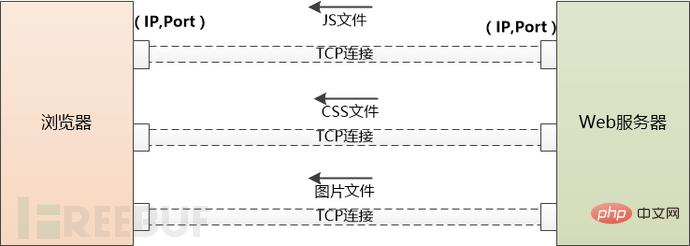
Wenn der Server JS- und CSS-Dateien an den Browser sendet, teilt er dem Browser mit, wann diese Dateien ablaufen (mittels Cache-Control oder Expire). , kann der Browser die Datei lokal zwischenspeichern, wenn sie zum zweiten Mal angefordert wird und nicht abläuft, kann sie direkt aus dem lokalen Bereich abgerufen werden.
Wenn es abläuft, kann der Browser den Server fragen, ob die Datei geändert wurde? (Basierend auf Last-Modified und ETag, die vom letzten Server gesendet wurden). Wenn es nicht geändert wurde (304 Not Modified), können Sie auch Caching verwenden. Andernfalls sendet der Server die neueste Datei an den Browser zurück.
Wenn Sie Strg+F5 drücken, wird natürlich zwangsweise eine GET-Anfrage ausgegeben, wobei der Cache völlig ignoriert wird.
Hinweis: Unter Chrome können Sie den Cache über den Befehl chrome://view-http-cache/ anzeigen.
Jetzt erhält der Browser drei wichtige Dinge:
1.HTML, der Browser verwandelt es in einen DOM-Baum
#🎜🎜 #2. CSS, der Browser wandelt es in einen CSS-Regelbaum um Tree generiert den sogenannten „Render Tree“, berechnet die Position/Größe jedes Elements, ordnet es an und ruft dann die API des Betriebssystems zum Zeichnen auf. Dies ist ein sehr komplizierter Prozess und wird hier nicht aufgeführt. Bisher sehen wir endlich den Inhalt von www.coder.com im Browser.
Das obige ist der detaillierte Inhalt vonProzessanalyse von der Eingabe der URL bis zur endgültigen Browserdarstellung des Seiteninhalts. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Detaillierte Einführung in die Datenübertragungssicherheit von DSMM
- Zusammenfassung von 40 häufig genutzten Intrusion-Ports für Hacker, die es wert sind, gesammelt zu werden
- Drei Prozessinjektionstechniken in der Mitre ATT&CK-Matrix
- Grundsätze der sicheren Entwicklungspraxis
- So beheben Sie die Sicherheitslücke bei der Remote-Befehlsausführung in der Apache-Achsenkomponente