
Heim >Betrieb und Instandhaltung >Nginx >So konfigurieren Sie den Lastausgleich für TCP im Nginx-Server
So konfigurieren Sie den Lastausgleich für TCP im Nginx-Server

- PHPznach vorne
- 2023-05-13 23:58:041685Durchsuche
1. Installieren Sie nginx
1. Laden Sie nginx
# wget http://nginx.org/download/nginx-1.2.4.tar.gz
2 herunter #
# wget https://github.com/yaoweibin/nginx_tcp_proxy_module/tarball/master
Quellcode-Homepage: https://github.com/yaoweibin/nginx_tcp_proxy_module
3. Installieren Sie nginx
# tar xvf nginx-1.2.4.tar.gz # tar xvf yaoweibin-nginx_tcp_proxy_module-v0.4-45-ga40c99a.tar.gz # cd nginx-1.2.4 # patch -p1 < ../yaoweibin-nginx_tcp_proxy_module-a40c99a/tcp.patch #./configure --prefix=/usr/local/nginx --with-pcre=../pcre-8.30 --add-module=../yaoweibin-nginx_tcp_proxy_module-ae321fd/ # make # make install
II, Ändern Sie die Konfigurationsdatei
Ändern Sie die Konfigurationsdatei nginx.conf
# cd /usr/local/nginx/conf # vim nginx.conf
worker_processes 1;
events {
worker_connections 1024;
}
tcp {
upstream mssql {
server 10.0.1.201:1433;
server 10.0.1.202:1433;
check interval=3000 rise=2 fall=5 timeout=1000;
}
server {
listen 1433;
server_name 10.0.1.212;
proxy_pass mssql;
}
}3. Starten Sie nginx
#🎜🎜 ## cd /usr/local/nginx/sbin/
# ./nginx
Port 1433 anzeigen:
#lsof :1433
4. Test
# telnet 10.0.1.201 1433
#🎜 🎜# #🎜🎜 #5. Test mit SQL Server-Client-Tool
6. Ausführungsprinzip von TCP Lastausgleich# 🎜🎜#
TCP-Lastausgleich unterstützt den ursprünglichen Planungsalgorithmus von Nginx, einschließlich Round Robin (Standard, Abfrageplanung), Hash (konsistent auswählen) usw. Gleichzeitig arbeiten die Planungsinformationsdaten auch mit dem Robustheitserkennungsmodul zusammen, um für jede Verbindung den geeigneten Ziel-Upstream-Server auszuwählen. Wenn Sie die Planungsmethode für den Hash-Lastausgleich verwenden, können Sie $remote_addr (Client-IP) verwenden, um eine einfache dauerhafte Sitzung zu erreichen (Verbindungen mit derselben Client-IP erfolgen immer auf demselben Dienstserver).
Wie andere Upstream-Module unterstützt das TCP-Stream-Modul auch die benutzerdefinierte Weiterleitungsgewichtung für den Lastausgleich (Konfiguration „weight=2“) sowie Backup- und Down-Parameter zum Beheben von Ausfällen des Upstream-Servers. Der Parameter max_conns kann die Anzahl der TCP-Verbindungen eines Servers begrenzen und den entsprechenden Konfigurationswert entsprechend der Kapazität des Servers festlegen. Insbesondere in Szenarien mit hoher Parallelität kann er den Zweck des Überlastungsschutzes erreichen.
nginx überwacht die Client-Verbindung und die Upstream-Verbindung. Sobald die Daten empfangen werden, liest Nginx sie sofort und überträgt sie an die Upstream-Verbindung, ohne eine Datenerkennung innerhalb der TCP-Verbindung durchzuführen. Nginx unterhält einen Speicherpuffer für das Schreiben von Client- und Upstream-Daten. Wenn der Client oder Server eine große Datenmenge überträgt, erhöht der Puffer die Speichergröße entsprechend. 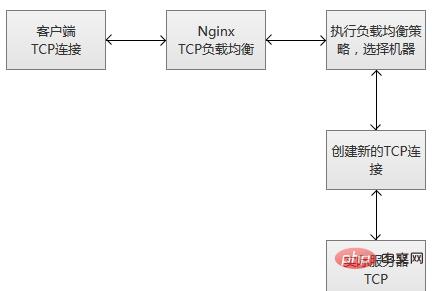

Wenn ein Server wiederholt ausfällt (die durch max_fails oder fail_timeout konfigurierten Parameter überschreiten), wird Nginx den Server ebenfalls kicken. 60 Sekunden nach dem Start des Servers versucht Nginx gelegentlich, die Verbindung wiederherzustellen, um zu überprüfen, ob der Normalzustand wieder hergestellt ist. Wenn der Server wieder normal ist, fügt Nginx ihn wieder der Upstream-Gruppe hinzu und erhöht langsam den Anteil der Verbindungsanfragen. Der Grund für „langsam ansteigend“ liegt darin, dass ein Dienst normalerweise über „heiße Daten“ verfügt, d. h. mehr als 80 % oder mehr der Anfragen werden tatsächlich im „Hot Data Cache“ blockiert „Davon wird nur ein kleiner Teil der Anfragen tatsächlich bearbeitet. Wenn die Maschine gerade gestartet wird, ist der „Hot-Data-Cache“ noch nicht eingerichtet. Zu diesem Zeitpunkt wird eine große Anzahl von Anfragen explosionsartig weitergeleitet, was wahrscheinlich dazu führt, dass die Maschine nicht mehr „aushalten“ kann und wieder auflegt . Am Beispiel von MySQL fallen normalerweise mehr als 95 % unserer MySQL-Abfragen in den Speichercache und nicht viele Abfragen werden tatsächlich ausgeführt.
Tatsächlich besteht dieses Risiko, unabhängig davon, ob es sich um eine einzelne Maschine oder einen Cluster handelt, beim Neustart oder beim Wechsel in einem Szenario mit hoher gleichzeitiger Anforderung. Es gibt zwei Möglichkeiten, es zu lösen:
# 🎜🎜 #(1) Die Anfragen nehmen allmählich zu, von weniger zu mehr, es sammeln sich nach und nach Hotspot-Daten an und erreichen schließlich den normalen Servicestatus.
Das TCP-Lastausgleichsmodul unterstützt die integrierte Robustheitserkennung. Wenn ein Upstream-Server eine TCP-Verbindung länger als die konfigurierte Zeit für „proxy_connect_timeout“ verweigert, wird davon ausgegangen, dass sie fehlgeschlagen ist. In diesem Fall versucht Nginx sofort, eine Verbindung zu einem anderen normalen Server in der Upstream-Gruppe herzustellen. Informationen zu Verbindungsfehlern werden im Nginx-Fehlerprotokoll aufgezeichnet.
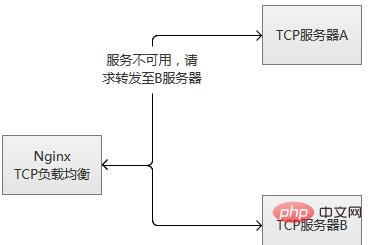
Wenn ein Server wiederholt ausfällt (die durch max_fails oder fail_timeout konfigurierten Parameter überschreiten), wird Nginx den Server ebenfalls kicken. 60 Sekunden nach dem Hochfahren des Servers versucht Nginx gelegentlich, die Verbindung wiederherzustellen, um zu überprüfen, ob der Normalzustand wieder hergestellt ist. Wenn der Server wieder normal ist, fügt Nginx ihn wieder der Upstream-Gruppe hinzu und erhöht langsam den Anteil der Verbindungsanfragen.
Der Grund für „langsam ansteigend“ liegt darin, dass ein Dienst normalerweise über „Hot Data“ verfügt, d. h. mehr als 80 % oder sogar mehr Anfragen werden tatsächlich im „Hot Data Cache“ blockiert. “, wird nur ein kleiner Teil der Anfragen tatsächlich bearbeitet. Wenn die Maschine gerade gestartet wird, ist der „Hot-Data-Cache“ noch nicht eingerichtet. Zu diesem Zeitpunkt wird eine große Anzahl von Anfragen explosionsartig weitergeleitet, was wahrscheinlich dazu führt, dass die Maschine nicht mehr „aushalten“ kann und wieder auflegt . Am Beispiel von MySQL fallen normalerweise mehr als 95 % unserer MySQL-Abfragen in den Speichercache und nicht viele Abfragen werden tatsächlich ausgeführt.
Tatsächlich besteht dieses Risiko, unabhängig davon, ob es sich um eine einzelne Maschine oder einen Cluster handelt, beim Neustart oder beim Wechsel in einem Szenario mit hoher gleichzeitiger Anforderung. Es gibt zwei Möglichkeiten, es zu lösen:
# 🎜🎜 #(1) Die Anfragen nehmen allmählich zu, von weniger zu mehr, sammeln nach und nach Hotspot-Daten an und erreichen schließlich den normalen Dienststatus. (2) Bereiten Sie „häufig verwendete“ Daten im Voraus vor, „heizen“ Sie den Dienst proaktiv vor und öffnen Sie dann den Zugriff auf den Server, nachdem das Vorheizen abgeschlossen ist.
Das obige ist der detaillierte Inhalt vonSo konfigurieren Sie den Lastausgleich für TCP im Nginx-Server. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!