
Heim >Backend-Entwicklung >Python-Tutorial >Was ist die Datenbereinigungsmethode in Python?
Was ist die Datenbereinigungsmethode in Python?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-13 16:19:062127Durchsuche
Die hier für die Datenbereinigung benötigte Bibliothek ist die Pandas-Bibliothek. Die Download-Methode muss noch im Terminal ausgeführt werden: pip install pandas.
Zuerst müssen wir die Daten lesen
import pandas as pd data = pd.read_csv(r'E:\PYthon\用户价值分析 RFM模型\data.csv') pd.set_option('display.max_columns', 888) # 大于总列数 pd.set_option('display.width', 1000) print(data.head()) print(data.info())#🎜 🎜# Zeile 3 dient zum Lesen der Daten. In der Pandas-Bibliothek gibt es einen Lesefunktionsaufruf. Das CSV-Format ist am schnellsten zu lesen und zu schreiben. Die 4. und 5. Zeile dienen dazu, alle Spalten zum Zweck des Lesens anzuzeigen. Denn wenn es viele Spalten gibt, verbirgt Pycharm einige der mittleren Spalten, also fügen wir diese beiden Zeilen hinzu, damit sie angezeigt werden sind nicht versteckt. Die 6. Zeile zeigt die Tabellenüberschrift und die Spaltennamen. Die 7. Zeile zeigt die grundlegenden Informationen der Tabelle, wie viele Daten vorhanden sind Geben Sie in jeder Spalte Folgendes ein: Um welche Art von Daten handelt es sich in dem Feld? Wie viele nicht leere Daten vorhanden sind, damit wir im ersten Schritt sehen können, welche Basisspalte einen Nullwert hat.
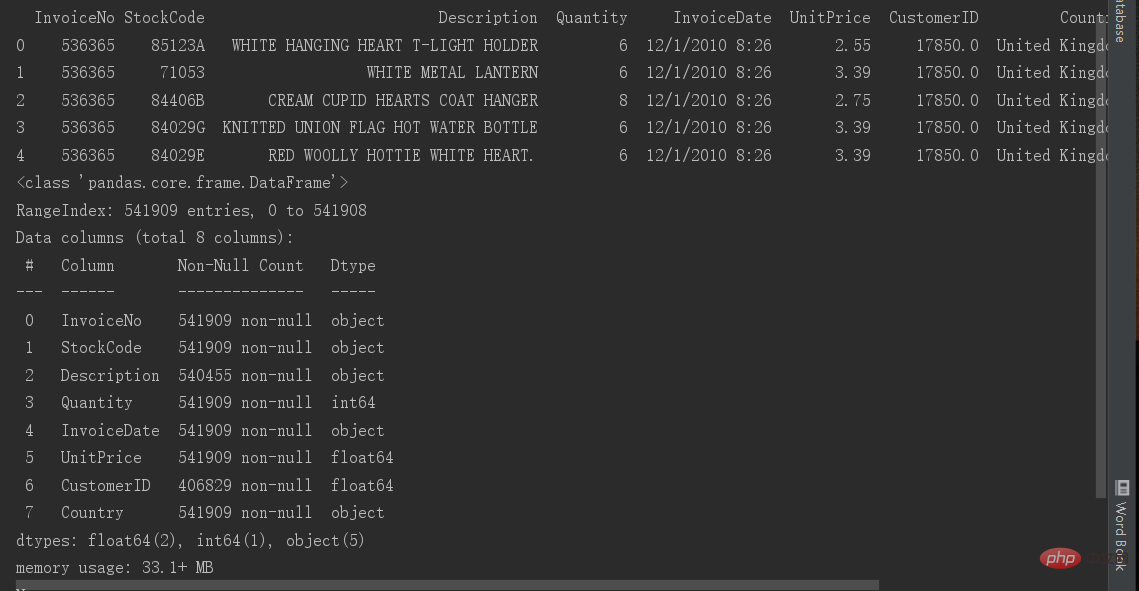
# 空值处理 print(data.isnull().sum()) # 空值中和,查看每一列的空值 # 空值删除 data.drop(columns=['Description'], inplace=True) print(data.info()) data.isnull()判断是否为空。data.isnumll().sum()计算空值数量。Zeile 5 löscht den Nullwert. Löschen Sie hier zuerst den Nullwert der Spalte „Inplace=True“. Wenn inplace=True fehlt, werden die Daten nicht geändert, die gedruckten Daten bleiben dieselben wie zuvor oder eine Variable wird für die Zuweisung neu definiert. Da diese Spalte relativ wenige Nullwerte enthält, ist diese Datenspalte für unsere Datenanalyse nicht so wichtig, daher haben wir uns entschieden, die gesamte Spalte zu löschen. Unsere Tabelle wird zum Filtern von Kunden verwendet, daher wird die Kunden-ID als Kriterium verwendet und andere Spalten müssen zwangsweise gelöscht werden
# CustomerID有空值 # 删除所有列的空值 data.dropna(inplace=True) # print(data.info()) print(data.isnull().sum()) # 由于CustomerID为必须字段,所以强制删除其他列,以CustomerID为准Hier führen wir zunächst eine Typkonvertierung für andere Felder durch# 🎜🎜# Typkonvertierung
# 转换为日期类型
data['InvoiceDate'] = pd.to_datetime(data['InvoiceDate'])
# CustomerID 转换为整型
data['CustomerID'] = data['CustomerID'].astype('int')
print(data.info())
Oben haben wir uns mit Nullwerten beschäftigt, als nächstes beschäftigen wir uns mit Ausreißern.
Ausreißerverarbeitung
Um die grundlegende Datenverteilung der Tabelle anzuzeigen, können Sie beschreiben
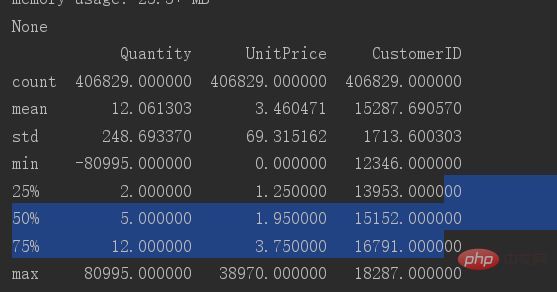
print(data.describe())
Sie können sehen, dass der Mindestwert in der Die Spalte „Datenmenge“ ist -80995. Diese Spalte enthält offensichtlich Ausreißer, daher muss diese Spalte nach Ausreißern gefiltert werden.
Es sind nur Werte größer 0 erforderlich.
data = data[data['Quantity'] > 0] print(data)
 Im Ausdruck sind es nur 397924 Zeilen.
Im Ausdruck sind es nur 397924 Zeilen.
Verarbeitung doppelter Werte
# 查看重复值 print(data[data.duplicated()])
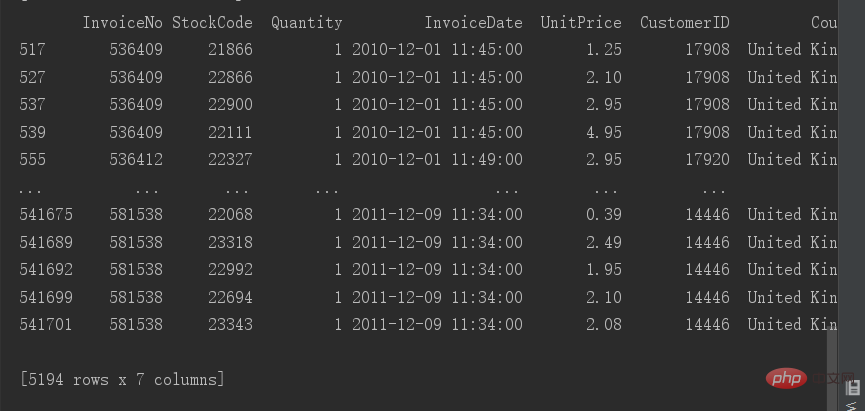 Es gibt 5194 Zeilen mit doppelten Werten. Die doppelten Werte sind hier vollständig dupliziert. Es besteht also keine Löschung der verwendeten Daten.
Es gibt 5194 Zeilen mit doppelten Werten. Die doppelten Werte sind hier vollständig dupliziert. Es besteht also keine Löschung der verwendeten Daten.
Doppelte Werte löschen
# 删除重复值 data.drop_duplicates(inplace=True) print(data.info())
Speichern Sie nach dem Löschen die Originaltabelle und überprüfen Sie dann die grundlegenden Informationen der Tabelle
# 🎜🎜#Es sind jetzt noch 392730 Daten übrig. In diesem Schritt ist die Datenbereinigung abgeschlossen. 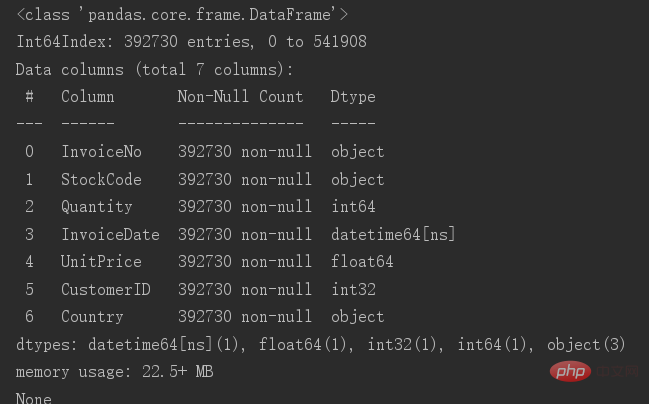
Das obige ist der detaillierte Inhalt vonWas ist die Datenbereinigungsmethode in Python?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!