
Heim >Backend-Entwicklung >Python-Tutorial >Wie Python Vaex schnell 100G große Datenmengen analysieren kann
Wie Python Vaex schnell 100G große Datenmengen analysieren kann

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-13 08:34:051404Durchsuche
Pandas Einschränkungen bei der Verarbeitung großer Datenmengen
Heutzutage wird die Datenmenge, die von Data-Science-Wettbewerben bereitgestellt wird, immer größer und reicht von Dutzenden Gigabyte bis zu Hunderten von Gigabyte. Dies wird die Maschinenleistung auf die Probe stellen und Datenverarbeitungsfunktionen.
Pandas in Python ist ein häufig verwendetes Datenverarbeitungstool. Es kann größere Datensätze (zig Millionen Zeilen) verarbeiten, wenn das Datenvolumen jedoch Milliarden von Dutzenden von Milliarden Zeilen erreicht etwas schwierig zu verarbeiten. Es übersteigt meine Fähigkeiten, man kann sagen, dass es sehr langsam ist.
Es gibt Leistungsfaktoren wie den Computerspeicher, aber Pandas eigener Datenverarbeitungsmechanismus (der auf dem Speicher basiert) schränkt auch seine Fähigkeit ein, große Datenmengen zu verarbeiten.
Natürlich können Pandas Daten stapelweise über Blöcke lesen, aber der Nachteil besteht darin, dass die Datenverarbeitung komplexer ist und jeder Analyseschritt Speicher und Zeit verbraucht.
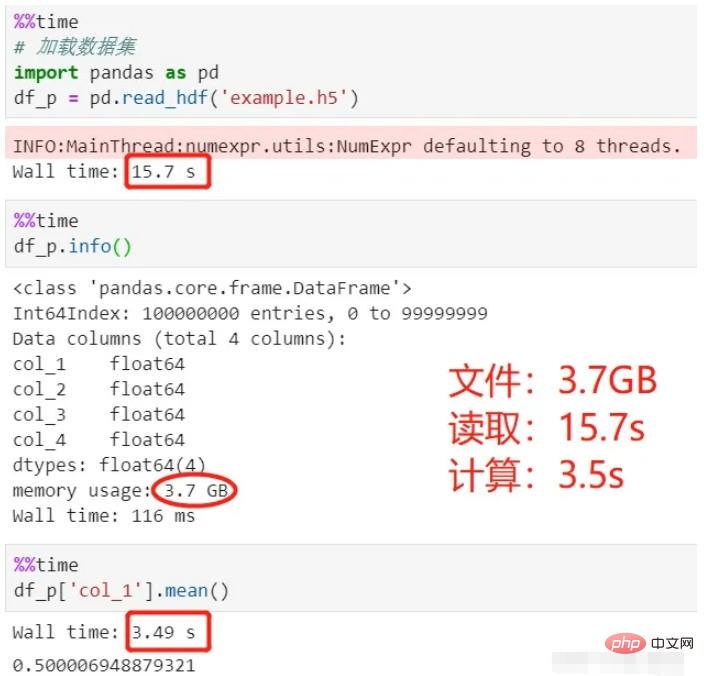
Als nächstes lesen Sie mit Pandas einen 3,7G-Datensatz (HDF5-Format) und berechnen Sie den Durchschnitt der ersten Zeile. Die CPU meines Computers ist i7-8550U und der Speicher ist 8G. Mal sehen, wie lange dieser Lade- und Berechnungsvorgang dauert.
Datensatz:
Verwenden Sie Pandas zum Lesen und Berechnen:
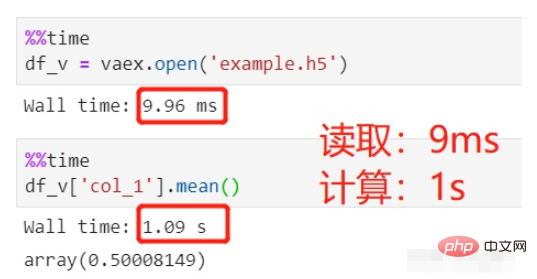
 # 🎜🎜#
# 🎜🎜#
installiert werden kann. pip
- vaex ist ein Datentabellentool zur Verarbeitung und Anzeige von Daten , ähnlich wie Pandas;
- vaex verwendet Speicherzuordnung und verzögerte Berechnung, belegt keinen Speicher und ist für die Verarbeitung großer Datenmengen geeignet; vaex kann eine statistische Analyse der zweiten Ebene und eine visuelle Anzeige von zig Milliarden Datensätzen durchführen;
- Die Vorteile von vaex sind: 🎜🎜#Leistung: Verarbeitung großer Datenmengen, 109 Zeilen/Sekunde;
- Kein Speicher Kopieren: Kein Kopieren des Speichers beim Filtern/Transformieren/Berechnen, Streaming bei Bedarf;
API: ähnlich wie Pandas, mit umfangreichen Datenverarbeitungs- und Berechnungsfunktionen;
#🎜 🎜#Interaktiv: Wird mit Jupyter-Notebook verwendet, flexible interaktive Visualisierung; 🎜🎜# Vaex installieren
Verwenden Sie Pip oder Conda zum Installieren: #🎜 🎜#- Daten lesen
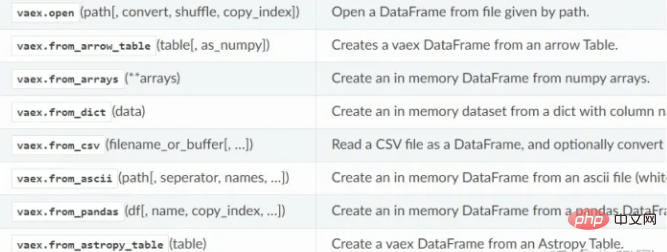
vaex unterstützt das Lesen von HDF5-, CSV-, Parkett- und anderen Dateien mithilfe der Lesemethode. HDF5 kann träge gelesen werden, während CSV nur in den Speicher gelesen werden kann.
- Vaex-Datenlesefunktion:
Datenverarbeitung
Manchmal müssen wir verschiedene Transformationen, Überprüfungen, Berechnungen usw. an den Daten durchführen. Jeder Schritt der Pandas-Verarbeitung verbraucht Speicher und ist zeitaufwändig. Sofern Sie keine Kettenverarbeitung verwenden, ist der Prozess sehr unklar.
vaex verwendet während des gesamten Prozesses keinen Speicher. Da seine Verarbeitung nur einen Ausdruck generiert, der eine logische Darstellung ist und nicht ausgeführt wird, wird er erst in der Phase der Endergebnisgenerierung ausgeführt. Darüber hinaus werden die Daten im gesamten Prozess gestreamt und es entsteht kein Speicherrückstand.
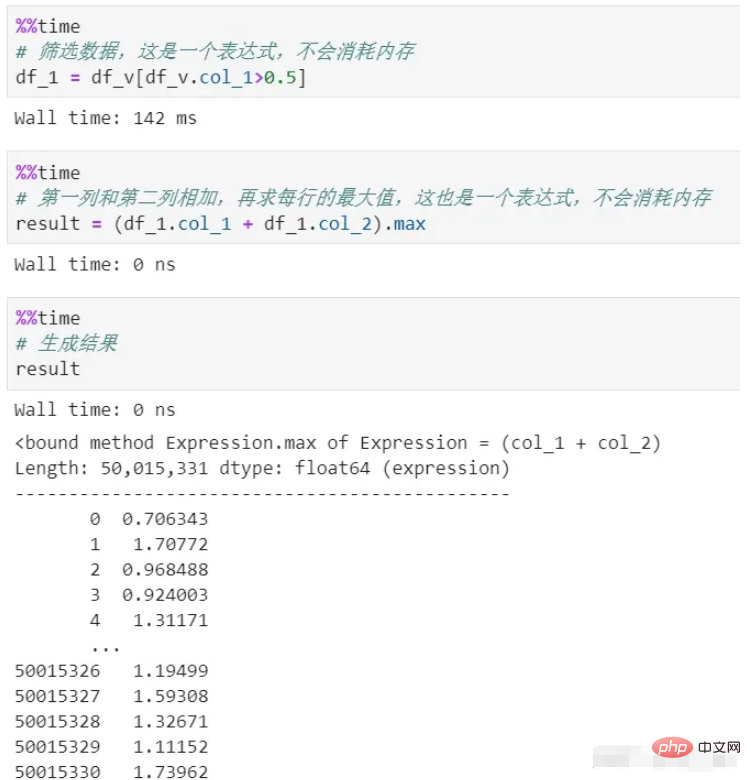
Sie können sehen, dass es zwei Prozesse zum Filtern und Berechnen gibt und hier kein Kopieren des Speichers erfolgt, was ein verzögerter Mechanismus ist. Wenn jeder Prozess tatsächlich berechnet wird, ganz zu schweigen vom Speicherverbrauch, ist allein der Zeitaufwand enorm.
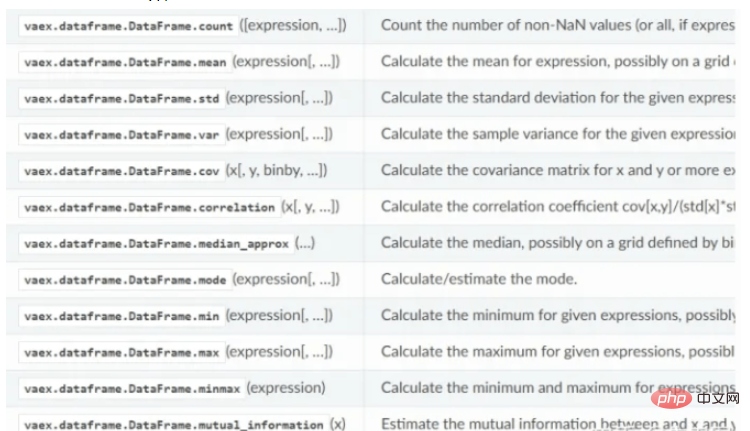
Statistische Berechnungsfunktion von vaex:
Visuelle Anzeige
vaex kann auch eine schnelle visuelle Anzeige durchführen, selbst bei zig Milliarden Datensätzen kann es immer noch Diagramme in Sekundenschnelle erstellen.
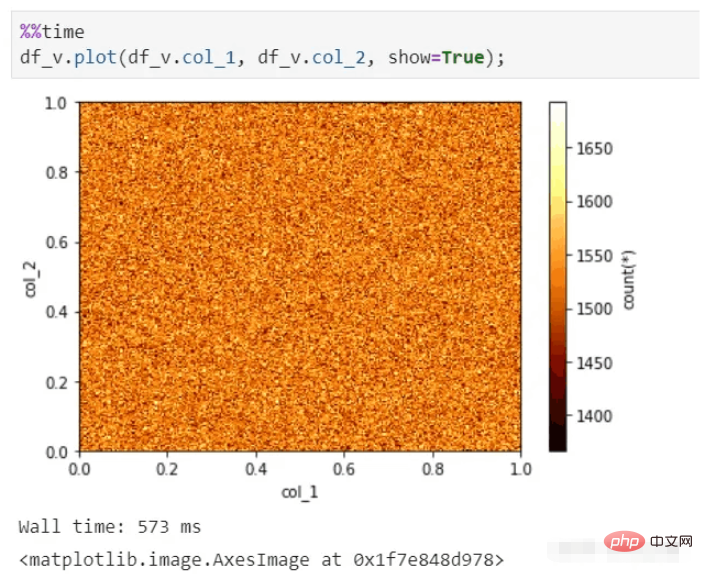
vaex-Visualisierungsfunktion:

Fazit
vaex ähnelt in gewisser Weise einer Kombination aus Spark und Pandas. Je größer die Datenmenge, desto mehr können ihre Vorteile widergespiegelt werden. Solange Ihre Festplatte so viele Daten speichern kann, wie sie benötigt, kann sie die Daten schnell analysieren.
vaex entwickelt sich immer noch rasant und integriert immer mehr Pandas-Funktionen. Die Anzahl der Sterne auf Github beträgt 5.000 und das Wachstumspotenzial ist riesig.
Anhang: HDF5-Datensatz-Generierungscode (4 Spalten und 100 Millionen Datenzeilen)
import pandas as pd import vaex df = pd.DataFrame(np.random.rand(100000000,4),columns=['col_1','col_2','col_3','col_4']) df.to_csv('example.csv',index=False) vaex.read('example.csv',convert='example1.hdf5')
Bitte beachten Sie, dass Sie hier nicht Pandas verwenden, um HDF5 direkt zu generieren, da sein Format nicht mit Vaex kompatibel ist.
Das obige ist der detaillierte Inhalt vonWie Python Vaex schnell 100G große Datenmengen analysieren kann. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!