
Heim >Backend-Entwicklung >Python-Tutorial >So implementieren Sie reguläre Ausdrücke in Python
So implementieren Sie reguläre Ausdrücke in Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-11 17:40:061560Durchsuche
Python-regulärer Ausdruck
Regulärer Ausdruck selbst ist ein Wissen, das unabhängig von der Programmiersprache ist, aber grundsätzlich hängt die von uns verwendete Programmiersprache von der Implementierung ab. Natürlich gibt es auch einige Unterschiede in der Bei der Implementierung unterstützen einige mehr Funktionen, andere weniger.
Da reguläre Ausdrücke in der Praxis ein weit verbreitetes Werkzeug sind, halte ich es für unzuverlässig, sie ohne Sprache zu lernen.
Einführung in reguläre Ausdrucksfunktionen
Haupt-API-Beziehungsdiagramm für reguläre Ausdrücke
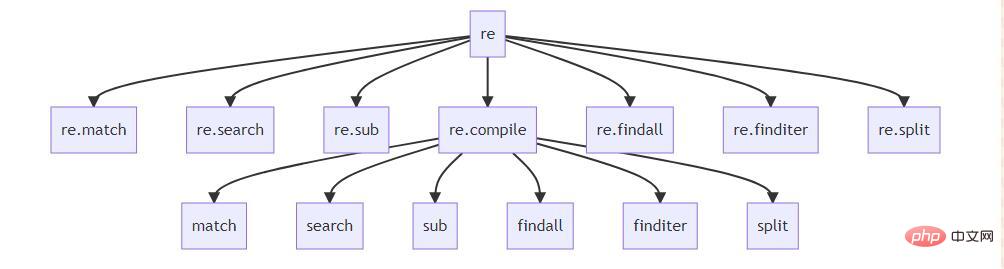
Dieses Diagramm ist meine persönliche Zusammenfassung. Ich denke, ich habe hier im Wesentlichen die Beziehung zwischen den Funktionen geklärt:
match stimmt mit dem regulären Ausdruck vom Anfang des Textes überein und gibt das passende Objekt zurück. Wenn nicht, gibt es None zurück.
search Stimmt mit dem regulären Ausdruck im gesamten Text überein und gibt das erste passende Objekt zurück.
sub verwendet reguläre Ausdrücke zur Textersetzung (Funktion regulärer Ausdrücke: Suchen und Ersetzen)
findall sucht nach regulären Ausdrücken aus dem gesamten Text und gibt alle passenden Ergebnisse in Form einer Liste zurück.
finditer gleicht einen regulären Ausdruck aus dem gesamten Text ab und gibt alle passenden Ergebnisse als Iterator zurück.
split verwendet reguläre Ausdrücke, um Text aufzuteilen
Wie Sie hier sehen können, gibt es viele Funktionen, die direkt unter ·re· verwendet werden können, und es gibt viele Funktionen mit demselben Namen unter re .compile-Funktion. Direkt unter dem ·re·-Modul befinden sich offiziell bereitgestellte Funktionen zur einfachen Verwendung. Die orthodoxste Art, sie zu verwenden, ist re.compile. re.compile 下面有很多同名的函数。直接在 ·re· 模块下的是官方提供方便使用的函数,通过 re.compile 来使用是最正统的方式。所以,接下来的内容,我基本上智慧使用 re.compile 及其下的方法来实现。
re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式 (Pattern)对象,供 match() 和 search() 以及其它函数使用。
语法:
re.compile(pattern[, flags])
pattern: 一个字符串形式的正则表达式
flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 多行模式
re.S 即为 '.' 并且包括换行符在内的任意字符('.' 不包括换行符)
re.U 表示特殊字符集 w, W, b, B, d, D, s, S 依赖 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和 ‘#’ 后面的注释
示例:查找字符串中的所有数字
import re s = 'runoob 123 google 456' result1 = re.findall(r'\d+', s) pattern = re.compile(r'\d+') # 查找数字 result2 = pattern.findall(s) result3 = pattern.findall(s, 0, 20) print(result1) print(result2) print(result3) """ output: [‘123', ‘456'] [‘123', ‘456'] [‘123', ‘45'] """
学习模板
接下来我们要逐渐学习正则表达的内容,这些内容是非常有趣的!Interesting and Excited!
这里给出一个接下来会一直使用的示例模板,这个模板是这篇博客最重要的东西了,之后的内容都会基于它进行扩展。所以,请好好理解它。
import re
# 需要进行搜索或者匹配的文本
text = """I love you yesterday and today."""
# 正则表达式
regexp = r'love'
# 编译(对正则表达式进行编译获取 Pattern Object)
pattern = re.compile(regexp)
# 搜索
m = pattern.search(text)
if m:
print("匹配对象: ", m)
print("匹配的字符串: ", m.group())
print("匹配的开始位置: ", m.start())
print("匹配的结束位置: ", m.end())
print("匹配位置的元组: ", m.span())
else:
print("No match!")
# 替换
new_text = pattern.sub("hate", text)
print(new_text)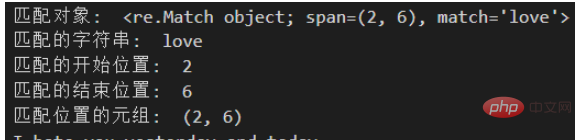
注意: 正则表达式 regexp 在开始前会使用 rFür den folgenden Inhalt verwende ich grundsätzlich re.compile und die folgenden Methoden, um dies zu erreichen.
compile-Funktion wird verwendet, um reguläre Ausdrücke zu kompilieren und ein reguläres Ausdrucksobjekt (Muster) für match() und search( zu generieren ) und andere Funktionen. | Muster: ein regulärer Ausdruck in Form einer Zeichenfolge | |
| re.I Groß- und Kleinschreibung ignorieren | |
| re.L Mehrzeilenmodus | |
| re.U stellt den Sonderzeichensatz w, W, b, B, d, D, s, S dar und basiert auf der Unicode-Zeichenattributdatenbank | |
| re.X, um die Lesbarkeit zu erhöhen. Leerzeichen ignorieren und Kommentare nach „#’ |
🎜🎜🎜Achtung :🎜 Der reguläre Ausdruck regexp verwendet vor dem Start das Präfix r. Der Zweck besteht darin, die Verwendung einer großen Anzahl von Escape-Zeichen im regulären Ausdruck zu vermeiden, was die allgemeine Lesbarkeit beeinträchtigt. 🎜🎜Die regulären Ausdrücke von Python umfassen viele sehr einfach zu verwendende Methoden, aber ich werde sie hier nicht zu sehr vorstellen. Wir werden immer das obige Muster verwenden, da diese einfach zu verwendenden Methoden nur eine Art Kapselung davon sind und das Erlernen der Verwendung dieser grundlegenden Methode natürlich zu anderen führt. 🎜🎜Das Matching -Objekt kann Informationen über reguläre Ausdrücke erhalten. 🎜start()🎜🎜Gibt die Startposition des Matches zurück🎜🎜🎜🎜end()🎜🎜Gibt die Endposition des Matches zurück🎜🎜🎜🎜span()🎜🎜Gibt ein Tupel zurück, das die passende (Start-, End-)Position enthält 🎜 🎜🎜🎜Das obige ist der detaillierte Inhalt vonSo implementieren Sie reguläre Ausdrücke in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!