

 Technologie-PeripheriegeräteKIDie Trainingsgeschwindigkeit wird um 17 % erhöht. Das Open-Source-Forschungsframework für verstärktes Lernen unterstützt das Training mit einzelnen und mehreren Agenten.
Technologie-PeripheriegeräteKIDie Trainingsgeschwindigkeit wird um 17 % erhöht. Das Open-Source-Forschungsframework für verstärktes Lernen unterstützt das Training mit einzelnen und mehreren Agenten.
OpenRL ist ein PyTorch-basiertes Forschungsframework für Reinforcement Learning, das vom Fourth Paradigm Reinforcement Learning Team entwickelt wurde. Es unterstützt das Training von Single-Agent-, Multi-Agent-, Natural-Language- und anderen Aufgaben. OpenRL wird auf Basis von PyTorch entwickelt, mit dem Ziel, der Forschungsgemeinschaft für Reinforcement Learning eine benutzerfreundliche, flexible, effiziente und nachhaltig skalierbare Plattform bereitzustellen. Zu den derzeit von OpenRL unterstützten Funktionen gehören:
- Eine gemeinsame Schnittstelle, die einfach zu verwenden ist und Single-Agent- und Multi-Agent-Training unterstützt
- Unterstützt Reinforcement-Learning-Training für Aufgaben in natürlicher Sprache (z. B. Dialogaufgaben)
- Unterstützt den Import von Modellen und Daten aus Hugging Face.
- Unterstützt LSTM, GRU, Transformer und andere Modelle Sammlung usw.
- Unterstützte benutzerdefinierte Trainingsmodelle, Belohnungsmodelle, Trainingsdaten und -umgebungen
- Unterstützte Turnhallenumgebung
- Unterstützt Wörterbuchbeobachtungsraum
- Unterstützt Wandb, TensorboardX und andere gängige Trainingsvisualisierungen Tools
- Unterstützen Sie die Serialisierung der Umgebung und das parallele Training und stellen Sie gleichzeitig konsistente Trainingseffekte in den beiden Modi sicher Typprüfung
- Derzeit ist OpenRL Open Source auf GitHub:
- Projektadresse: https://github.com/OpenRL-Lab/openrl
- Erste Erfahrung mit OpenRL
OpenRL kann derzeit über pip installiert werden:
<code>pip install openrl</code>
kann auch über conda installiert werden: 
<code>conda install -c openrl openrl</code>
OpenRL bietet eine einfache und benutzerfreundliche Oberfläche für Einsteiger in das Reinforcement Learning Ein Beispiel für die Verwendung des PPO-Algorithmus zum Trainieren der CartPole-Umgebung: <code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentenv = make ("CartPole-v1", env_num=9) # 创建环境,并设置环境并行数为 9net = Net (env) # 创建神经网络agent = Agent (net) # 初始化智能体agent.train (total_time_steps=20000) # 开始训练,并设置环境运行总步数为 20000</code>
Umgebung erstellen=> Initialisieren des Agenten=>
Führen Sie den obigen Code auf einem normalen Laptop aus, und die Schulung des Agenten dauert nur wenige Sekunden:
Darüber hinaus für Multi-Agenten, natürliche Sprache und andere Aufgaben Für das Training bietet OpenRL auch die gleiche einfache und benutzerfreundliche Oberfläche. Für die MPE-Umgebung in Multi-Agent-Aufgaben muss OpenRL beispielsweise nur wenige Codezeilen aufrufen, um das Training abzuschließen: <code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentdef train ():# 创建 MPE 环境,使用异步环境,即每个智能体独立运行env = make ("simple_spread",env_num=100,asynchrnotallow=True,)# 创建 神经网络,使用 GPU 进行训练net = Net (env, device="cuda")agent = Agent (net) # 初始化训练器# 开始训练agent.train (total_time_steps=5000000)# 保存训练完成的智能体agent.save ("./ppo_agent/")if __name__ == "__main__":train ()</code>Die folgende Abbildung zeigt die Leistung des Agenten vor und nach dem Training durch OpenRL:
Wenn es viele Konfigurationsparameter gibt, unterstützt OpenRL Benutzer auch dabei, ihre eigenen Konfigurationsdateien zu schreiben, um Trainingsparameter zu ändern. Benutzer können beispielsweise die folgende Konfigurationsdatei (mpe_ppo.yaml) erstellen und die darin enthaltenen Parameter ändern:
<code># mpe_ppo.yamlseed: 0 # 设置 seed,保证每次实验结果一致lr: 7e-4 # 设置学习率episode_length: 25 # 设置每个 episode 的长度use_recurrent_policy: true # 设置是否使用 RNNuse_joint_action_loss: true # 设置是否使用 JRPO 算法use_valuenorm: true # 设置是否使用 value normalization</code>
<code>python train_ppo.py --config mpe_ppo.yaml</code>
训练与测试可视化
此外,通过 OpenRL,用户还可以方便地使用 wandb 来可视化训练过程:

OpenRL 还提供了各种环境可视化的接口,方便用户对并行环境进行可视化。用户可以在创建并行环境的时候设置环境的渲染模式为 "group_human",便可以同时对多个并行环境进行可视化:
<code>env = make ("simple_spread", env_num=9, render_mode="group_human")</code>
此外,用户还可以通过引入 GIFWrapper 来把环境运行过程保存为 gif 动画:
<code>from openrl.envs.wrappers import GIFWrapperenv = GIFWrapper (env, "test_simple_spread.gif")</code>
智能体的保存和加载
OpenRL 提供 agent.save () 和 agent.load () 接口来保存和加载训练好的智能体,并通过 agent.act () 接口来获取测试时的智能体动作:
<code># test_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.envs.wrappers import GIFWrapper # 用于生成 gifdef test ():# 创建 MPE 环境env = make ( "simple_spread", env_num=4)# 使用 GIFWrapper,用于生成 gifenv = GIFWrapper (env, "test_simple_spread.gif")agent = Agent (Net (env)) # 创建 智能体# 保存智能体agent.save ("./ppo_agent/")# 加载智能体agent.load ('./ppo_agent/')# 开始测试obs, _ = env.reset ()while True:# 智能体根据 observation 预测下一个动作action, _ = agent.act (obs)obs, r, done, info = env.step (action)if done.any ():breakenv.close ()if __name__ == "__main__":test ()</code>
执行该测试代码,便可以在同级目录下找到保存好的环境运行动画文件 (test_simple_spread.gif):

训练自然语言对话任务
最近的研究表明,强化学习也可以用于训练语言模型, 并且能显著提升模型的性能。目前,OpenRL 已经支持自然语言对话任务的强化学习训练。OpenRL 通过模块化设计,支持用户加载自己的数据集 ,自定义训练模型,自定义奖励模型,自定义 wandb 信息输出以及一键开启混合精度训练等。
对于对话任务训练,OpenRL 提供了同样简单易用的训练接口:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserdef train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)net = Net (env, cfg=cfg, device="cuda")agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>
可以看出,OpenRL 训练对话任务和其他强化学习任务一样,都是通过创建交互环境的方式进行训练。
加载自定义数据集
训练对话任务,需要对话数据集。这里我们可以使用 Hugging Face 上的公开数据集(用户可以替换成自己的数据集)。加载数据集,只需要在配置文件中传入数据集的名称或者路径即可:
<code># nlp_ppo.yamldata_path: daily_dialog # 数据集路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径seed: 0 # 设置 seed,保证每次实验结果一致lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 20 # 设置每个 episode 的长度use_recurrent_policy: true</code>
上述配置文件中的 data_path 可以设置为 Hugging Face 数据集名称或者本地数据集路径。此外,环境参数中的 tokenizer_path 用于指定加载文字编码器的 Hugging Face 名称或者本地路径。
自定义训练模型
在 OpenRL 中,我们可以使用 Hugging Face 上的模型来进行训练。为了加载 Hugging Face 上的模型,我们首先需要在配置文件 nlp_ppo.yaml 中添加以下内容:
<code># nlp_ppo.yaml# 预训练模型路径model_path: rajkumarrrk/gpt2-fine-tuned-on-daily-dialog use_share_model: true # 策略网络和价值网络是否共享模型ppo_epoch: 5 # ppo 训练迭代次数data_path: daily_dialog # 数据集名称或者路径env: # 环境所用到的参数args: {'tokenizer_path': 'gpt2'} # 读取 tokenizer 的路径lr: 1e-6 # 设置 policy 模型的学习率critic_lr: 1e-6 # 设置 critic 模型的学习率episode_length: 128 # 设置每个 episode 的长度num_mini_batch: 20</code>
然后在 train_ppo.py 中添加以下代码:
<code># train_ppo.pyfrom openrl.envs.common import makefrom openrl.modules.common import PPONet as Netfrom openrl.runners.common import PPOAgent as Agentfrom openrl.configs.config import create_config_parserfrom openrl.modules.networks.policy_value_network_gpt import (PolicyValueNetworkGPT as PolicyValueNetwork,)def train ():# 添加读取配置文件的代码cfg_parser = create_config_parser ()cfg = cfg_parser.parse_args ()# 创建 NLP 环境env = make ("daily_dialog",env_num=2,asynchrnotallow=True,cfg=cfg,)# 创建自定义神经网络model_dict = {"model": PolicyValueNetwork}net = Net (env, cfg=cfg, model_dict=model_dict)# 创建训练智能体agent = Agent (net)agent.train (total_time_steps=5000000)if __name__ == "__main__":train ()</code>
通过以上简单几行的修改,用户便可以使用 Hugging Face 上的预训练模型进行训练。如果用户希望分别自定义策略网络和价值网络,可以写好 CustomPolicyNetwork 以及 CustomValueNetwork 后通过以下方式从外部传入训练网络:
<code>model_dict = {"policy": CustomPolicyNetwork,"critic": CustomValueNetwork,}net = Net (env, model_dict=model_dict)</code>
自定义奖励模型
通常,自然语言任务的数据集中并不包含奖励信息。因此,如果需要使用强化学习来训练自然语言任务,就需要使用额外的奖励模型来生成奖励。在该对话任务中,我们可以使用一个复合的奖励模型,它包含以下三个部分:
●意图奖励:即当智能体生成的语句和期望的意图接近时,智能体便可以获得更高的奖励。
●METEOR 指标奖励:METEOR 是一个用于评估文本生成质量的指标,它可以用来衡量生成的语句和期望的语句的相似程度。我们把这个指标作为奖励反馈给智能体,以达到优化生成的语句的效果。
●KL 散度奖励:该奖励用来限制智能体生成的文本偏离预训练模型的程度,防止出现 reward hacking 的问题。
我们最终的奖励为以上三个奖励的加权和,其中 KL 散度奖励的系数是随着 KL 散度的大小动态变化的。想在 OpenRL 中使用该奖励模型,用户无需修改训练代码,只需要在 nlp_ppo.yaml 文件中添加 reward_class 参数即可:
<code># nlp_ppo.yamlreward_class:id: NLPReward # 奖励模型名称args: {# 用于意图判断的模型的名称或路径"intent_model": rajkumarrrk/roberta-daily-dialog-intent-classifier,# 用于计算 KL 散度的预训练模型的名称或路径"ref_model": roberta-base, # 用于意图判断的 tokenizer 的名称或路径}</code>
OpenRL 支持用户使用自定义的奖励模型。首先,用户需要编写自定义奖励模型 (需要继承 BaseReward 类)。接着,用户需要注册自定义的奖励模型,即在 train_ppo.py 添加以下代码:
<code># train_ppo.pyfrom openrl.rewards.nlp_reward import CustomRewardfrom openrl.rewards import RewardFactoryRewardFactory.register ("CustomReward", CustomReward)</code>
最后,用户只需要在配置文件中填写自定义的奖励模型即可:
<code>reward_class:id: "CustomReward" # 自定义奖励模型名称args: {} # 用户自定义奖励函数可能用到的参数</code>
自定义训练过程信息输出
OpenRL 还支持用户自定义 wandb 和 tensorboard 的输出内容。例如,在该任务的训练过程中,我们还需要输出各种类型奖励的信息和 KL 散度系数的信息, 用户可以在 nlp_ppo.yaml 文件中加入 vec_info_class 参数来实现:
<code># nlp_ppo.yamlvec_info_class:id: "NLPVecInfo" # 调用 NLPVecInfo 类以打印 NLP 任务中奖励函数的信息# 设置 wandb 信息wandb_entity: openrl # 这里用于指定 wandb 团队名称,请把 openrl 替换为你自己的团队名称experiment_name: train_nlp # 这里用于指定实验名称run_dir: ./run_results/ # 这里用于指定实验数据保存的路径log_interval: 1 # 这里用于指定每隔多少个 episode 上传一次 wandb 数据# 自行填写其他参数...</code>
修改完配置文件后,在 train_ppo.py 文件中启用 wandb:
<code># train_ppo.pyagent.train (total_time_steps=100000, use_wandb=True)</code>
然后执行 python train_ppo.py –config nlp_ppo.yaml,稍后,便可以在 wandb 中看到如下的输出:
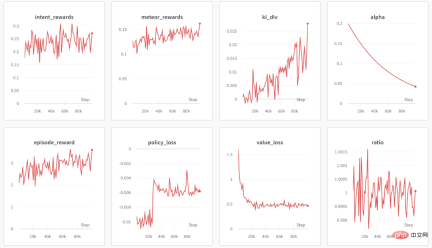
从上图可以看到,wandb 输出了各种类型奖励的信息和 KL 散度系数的信息。
如果用户还需要输出其他信息,还可以参考 NLPVecInfo 类 和 VecInfo 类来实现自己的 CustomVecInfo 类。然后,需要在 train_ppo.py 中注册自定义的 CustomVecInfo 类:
<code># train_ppo.py # 注册自定义输出信息类 VecInfoFactory.register ("CustomVecInfo", CustomVecInfo)</code>
最后,只需要在 nlp_ppo.yaml 中填写 CustomVecInfo 类即可启用:
<code># nlp_ppo.yamlvec_info_class:id: "CustomVecInfo" # 调用自定义 CustomVecInfo 类以输出自定义信息</code>
使用混合精度训练加速
OpenRL 还提供了一键开启混合精度训练的功能。用户只需要在配置文件中加入以下参数即可:
<code># nlp_ppo.yamluse_amp: true # 开启混合精度训练</code>
对比评测
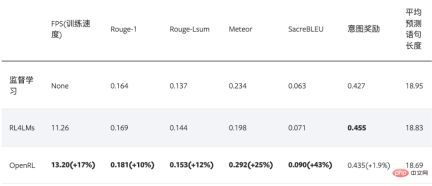
下表格展示了使用 OpenRL 训练该对话任务的结果。结果显示使用强化学习训练后,模型各项指标皆有所提升。另外,从下表可以看出,相较于 RL4LMs , OpenRL 的训练速度更快(在同样 3090 显卡的机器上,速度提升 17% ),最终的性能指标也更好:
最后,对于训练好的智能体,用户可以方便地通过 agent.chat () 接口进行对话:
<code># chat.pyfrom openrl.runners.common import ChatAgent as Agentdef chat ():agent = Agent.load ("./ppo_agent", tokenizer="gpt2",)history = []print ("Welcome to OpenRL!")while True:input_text = input ("> User:")if input_text == "quit":breakelif input_text == "reset":history = []print ("Welcome to OpenRL!")continueresponse = agent.chat (input_text, history)print (f"> OpenRL Agent: {response}")history.append (input_text)history.append (response)if __name__ == "__main__":chat ()</code>
执行 python chat.py ,便可以和训练好的智能体进行对话了:

总结
OpenRL 框架经过了 OpenRL-Lab 的多次迭代并应用于学术研究和 AI 竞赛,目前已经成为了一个较为成熟的强化学习框架。OpenRL-Lab 团队将持续维护和更新 OpenRL,欢迎大家加入我们的开源社区,一起为强化学习的发展做出贡献。更多关于 OpenRL 的信息,可以参考:
- OpenRL 官方仓库:https://github.com/OpenRL-Lab/openrl/
- OpenRL 中文文档:https://openrl-docs.readthedocs.io/zh/latest/
致谢
OpenRL 框架的开发吸取了其他强化学习框架的优点:
- Stable-baselines3: https://github.com/DLR-RM/stable-baselines3
- pytorch-a2c -ppo-acktr-gail: https://github.com/ikostrikov/pytorch-a2c-ppo-acktr-gail
- MAPPO: https://github. com/marlbenchmark/on-policy
- Gymnasium: https://github.com/Farama-Foundation/Gymnasium
- DI-engine:https://github.com/opendilab/DI-engine/
- Tianshou: https://github.com/thu- ml/tianshou
- RL4LMs: https://github.com/allenai/RL4LMs
Future Work
Derzeit befindet sich OpenRL noch in der kontinuierlichen Entwicklungs- und Konstruktionsphase. In Zukunft wird OpenRL weitere Funktionen öffnen:
- #🎜 🎜##🎜 🎜#Selbstspieltraining für Support-Agenten
- Offline-Algorithmen für Verstärkungslernen, Modelllernen und inverses Verstärkungslernen hinzufügen
- # ?? 🎜#Unterstützung mehrerer Maschinen Verteiltes Training
- OpenRL Lab-Team
- Das OpenRL-Framework wird vom OpenRL Lab-Team entwickelt, a Das 4. Paradigma-Unternehmen ist sein Forschungsteam für verstärktes Lernen. Fourth Paradigm engagiert sich seit langem für die Forschung, Entwicklung und industrielle Anwendung von Reinforcement Learning. Um die Integration von Industrie, Wissenschaft und Forschung im Bereich Reinforcement Learning zu fördern, gründete 4Paradigm das OpenRL Lab-Forschungsteam mit dem Ziel, fortschrittliche Open-Source-Technologie und bahnbrechende Erforschung künstlicher Intelligenz zu entwickeln. Weniger als ein Jahr nach seiner Gründung hat das OpenRL Lab-Team drei Artikel in AAMAS veröffentlicht, am Google Football Game 11 vs 11-Wettbewerb teilgenommen und den dritten Platz gewonnen. Der vom Team vorgeschlagene TiZero-Agent ist der erste, der die Ausbildung zum vollständigen Spielagenten von Google Football durch Lehrplanlernen, verteiltes Verstärkungslernen, Selbstspiele und andere Technologien von Grund auf abschließt: #🎜🎜 ## 🎜🎜#
- Am 28. Oktober 2022 belegte Tizero den ersten Platz auf der Jidi-Bewertungsplattform:
Das obige ist der detaillierte Inhalt vonDie Trainingsgeschwindigkeit wird um 17 % erhöht. Das Open-Source-Forschungsframework für verstärktes Lernen unterstützt das Training mit einzelnen und mehreren Agenten.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Nuitka简介:编译和分发Python的更好方法Apr 13, 2023 pm 12:55 PM
Nuitka简介:编译和分发Python的更好方法Apr 13, 2023 pm 12:55 PM译者 | 李睿审校 | 孙淑娟随着Python越来越受欢迎,其局限性也越来越明显。一方面,编写Python应用程序并将其分发给没有安装Python的人员可能非常困难。解决这一问题的最常见方法是将程序与其所有支持库和文件以及Python运行时打包在一起。有一些工具可以做到这一点,例如PyInstaller,但它们需要大量的缓存才能正常工作。更重要的是,通常可以从生成的包中提取Python程序的源代码。在某些情况下,这会破坏交易。第三方项目Nuitka提供了一个激进的解决方案。它将Python程序编
 ChatGPT 的五大功能可以帮助你提高代码质量Apr 14, 2023 pm 02:58 PM
ChatGPT 的五大功能可以帮助你提高代码质量Apr 14, 2023 pm 02:58 PMChatGPT 目前彻底改变了开发代码的方式,然而,大多数软件开发人员和数据专家仍然没有使用 ChatGPT 来改进和简化他们的工作。这就是为什么我在这里概述 5 个不同的功能,以提高我们的日常工作速度和质量。我们可以在日常工作中使用它们。现在,我们一起来了解一下吧。注意:切勿在 ChatGPT 中使用关键代码或信息。01.生成项目代码的框架从头开始构建新项目时,ChatGPT 是我的秘密武器。只需几个提示,它就可以生成我需要的代码框架,包括我选择的技术、框架和版本。它不仅为我节省了至少一个小时
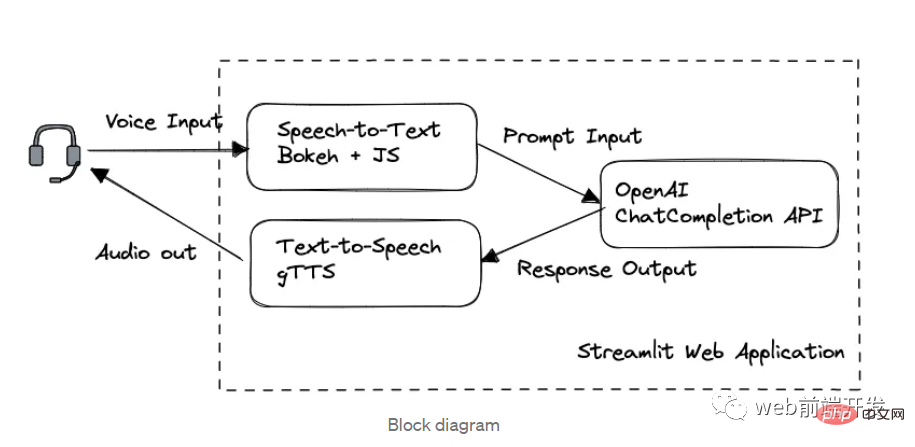 我创建了一个由 ChatGPT API 提供支持的语音聊天机器人,方法请收下Apr 07, 2023 pm 11:01 PM
我创建了一个由 ChatGPT API 提供支持的语音聊天机器人,方法请收下Apr 07, 2023 pm 11:01 PM今天这篇文章的重点是使用 ChatGPT API 创建私人语音 Chatbot Web 应用程序。目的是探索和发现人工智能的更多潜在用例和商业机会。我将逐步指导您完成开发过程,以确保您理解并可以复制自己的过程。为什么需要不是每个人都欢迎基于打字的服务,想象一下仍在学习写作技巧的孩子或无法在屏幕上正确看到单词的老年人。基于语音的 AI Chatbot 是解决这个问题的方法,就像它如何帮助我的孩子要求他的语音 Chatbot 给他读睡前故事一样。鉴于现有可用的助手选项,例如,苹果的 Siri 和亚马
 解决Batch Norm层等短板的开放环境解决方案Apr 26, 2023 am 10:01 AM
解决Batch Norm层等短板的开放环境解决方案Apr 26, 2023 am 10:01 AM测试时自适应(Test-TimeAdaptation,TTA)方法在测试阶段指导模型进行快速无监督/自监督学习,是当前用于提升深度模型分布外泛化能力的一种强有效工具。然而在动态开放场景中,稳定性不足仍是现有TTA方法的一大短板,严重阻碍了其实际部署。为此,来自华南理工大学、腾讯AILab及新加坡国立大学的研究团队,从统一的角度对现有TTA方法在动态场景下不稳定原因进行分析,指出依赖于Batch的归一化层是导致不稳定的关键原因之一,另外测试数据流中某些具有噪声/大规模梯度的样本
 摔倒检测-完全用ChatGPT开发,分享如何正确地向ChatGPT提问Apr 07, 2023 pm 03:06 PM
摔倒检测-完全用ChatGPT开发,分享如何正确地向ChatGPT提问Apr 07, 2023 pm 03:06 PM哈喽,大家好。之前给大家分享过摔倒识别、打架识别,今天以摔倒识别为例,我们看看能不能完全交给ChatGPT来做。让ChatGPT来做这件事,最核心的是如何向ChatGPT提问,把问题一股脑的直接丢给ChatGPT,如:用 Python 写个摔倒检测代码 是不可取的, 而是要像挤牙膏一样,一点一点引导ChatGPT得到准确的答案,从而才能真正让ChatGPT提高我们解决问题的效率。今天分享的摔倒识别案例,与ChatGPT对话的思路清晰,代码可用度高,按照GPT返回的结果完全可以开
 17 个可以实现高效工作与在线赚钱的 AI 工具网站Apr 11, 2023 pm 04:13 PM
17 个可以实现高效工作与在线赚钱的 AI 工具网站Apr 11, 2023 pm 04:13 PM自 2020 年以来,内容开发领域已经感受到人工智能工具的存在。1.Jasper AI网址:https://www.jasper.ai在可用的 AI 文案写作工具中,Jasper 作为那些寻求通过内容生成赚钱的人来讲,它是经济实惠且高效的选择之一。该工具精通短格式和长格式内容均能完成。Jasper 拥有一系列功能,包括无需切换到模板即可快速生成内容的命令、用于创建文章的高效长格式编辑器,以及包含有助于创建各种类型内容的向导的内容工作流,例如,博客文章、销售文案和重写。Jasper Chat 是该
 为什么特斯拉的人形机器人长得并不像人?一文了解恐怖谷效应对机器人公司的影响Apr 14, 2023 pm 11:13 PM
为什么特斯拉的人形机器人长得并不像人?一文了解恐怖谷效应对机器人公司的影响Apr 14, 2023 pm 11:13 PM1970年,机器人专家森政弘(MasahiroMori)首次描述了「恐怖谷」的影响,这一概念对机器人领域产生了巨大影响。「恐怖谷」效应描述了当人类看到类似人类的物体,特别是机器人时所表现出的积极和消极反应。恐怖谷效应理论认为,机器人的外观和动作越像人,我们对它的同理心就越强。然而,在某些时候,机器人或虚拟人物变得过于逼真,但又不那么像人时,我们大脑的视觉处理系统就会被混淆。最终,我们会深深地陷入一种对机器人非常消极的情绪状态里。森政弘的假设指出:由于机器人与人类在外表、动作上相似,所以人类亦会对
 Python面向对象里常见的内置成员介绍Apr 12, 2023 am 09:10 AM
Python面向对象里常见的内置成员介绍Apr 12, 2023 am 09:10 AM好嘞,今天我们继续剖析下Python里的类。[[441842]]先前我们定义类的时候,使用到了构造函数,在Python里的构造函数书写比较特殊,他是一个特殊的函数__init__,其实在类里,除了构造函数还有很多其他格式为__XXX__的函数,另外也有一些__xx__的属性。下面我们一一说下:构造函数Python里所有类的构造函数都是__init__,其中根据我们的需求,构造函数又分为有参构造函数和无惨构造函数。如果当前没有定义构造函数,那么系统会自动生成一个无参空的构造函数。例如:在有继承关系


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)

Dreamweaver Mac
Visuelle Webentwicklungstools

PHPStorm Mac-Version
Das neueste (2018.2.1) professionelle, integrierte PHP-Entwicklungstool

ZendStudio 13.5.1 Mac
Leistungsstarke integrierte PHP-Entwicklungsumgebung

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

