
Heim >Backend-Entwicklung >Python-Tutorial >So verwenden Sie Python, um die Spracherkennungsfunktion unter Linux zu implementieren
So verwenden Sie Python, um die Spracherkennungsfunktion unter Linux zu implementieren

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-11 08:04:052002Durchsuche
Einführung in die Funktionsweise der Spracherkennung
Die Spracherkennung entstand aus Forschungen, die in den frühen 1950er Jahren in den Bell Labs durchgeführt wurden. Frühe Spracherkennungssysteme konnten nur einen einzelnen Sprecher und einen Wortschatz von nur etwa einem Dutzend Wörtern erkennen. Moderne Spracherkennungssysteme haben bei der Erkennung mehrerer Sprecher große Fortschritte gemacht und verfügen über einen großen Wortschatz, der mehrere Sprachen erkennt.
Der erste Teil der Spracherkennung ist natürlich die Sprache. Über das Mikrofon wird Sprache vom physischen Ton in elektrische Signale und dann über einen Analog-Digital-Wandler in Daten umgewandelt. Nach der Digitalisierung können mehrere Modelle zum Transkribieren von Audio in Text angewendet werden.
Die meisten modernen Spracherkennungssysteme basieren auf Hidden-Markov-Modellen (HMM). Sein Funktionsprinzip ist: Das Sprachsignal kann als stationärer Prozess auf einer sehr kurzen Zeitskala (z. B. 10 Millisekunden) angenähert werden, d. h. als ein Prozess, dessen statistische Eigenschaften sich mit der Zeit nicht ändern.
Viele moderne Spracherkennungssysteme nutzen vor der HMM-Erkennung neuronale Netze, um das Sprachsignal durch Merkmalstransformation und Dimensionsreduktionstechniken zu vereinfachen. Sprachaktivitätsdetektoren (VAD) können auch verwendet werden, um das Audiosignal auf Teile zu reduzieren, die möglicherweise nur Sprache enthalten.
Zum Glück für Python-Benutzer sind einige Spracherkennungsdienste online über APIs verfügbar, und die meisten von ihnen stellen auch Python-SDKs bereit.
Wählen Sie das richtige Python-Spracherkennungspaket
Es gibt einige vorgefertigte Spracherkennungspakete in PyPI. Dazu gehören:
apiai
google-cloud-speech
pocketsphinx
SpeechRcognition
watson-developer-cloud
wit
Einige Softwarepakete wie wit und apiai bieten einige integrierte Funktionen, die über die grundlegende Spracherkennung hinausgehen, z. B. die Identifizierung der Sprecherabsicht. Verarbeitung natürlicher Sprache Fähigkeiten. Andere Softwarepakete wie Google Cloud Speech konzentrieren sich auf die Konvertierung von Sprache in Text.
Unter diesen zeichnet sich SpeechRecognition durch seine Benutzerfreundlichkeit aus.
Das Erkennen von Sprache erfordert eine Audioeingabe, und das Abrufen der Audioeingabe in SpeechRecognition ist sehr einfach. Es ist nicht erforderlich, ein Skript zu erstellen, um auf das Mikrofon zuzugreifen und die Audiodatei von Grund auf zu verarbeiten. Der Abruf dauert nur wenige Minuten und laufen.
SpeechRecognition installieren
SpeechRecognition ist mit Python 2.6, 2.7 und 3.3+ kompatibel, bei Verwendung in Python 2 sind jedoch einige zusätzliche Installationsschritte erforderlich. Sie können den Befehl pip verwenden, um SpeechRecognition vom Terminal aus zu installieren: pip3 install SpeechRecognition
Nachdem die Installation abgeschlossen ist, können Sie das Interpreterfenster öffnen, um die Installation zu überprüfen:

Hinweis: Schließen Sie diese Sitzung nicht, Sie werden sie verwenden es in den nächsten Schritten.
Wenn Sie mit vorhandenen Audiodateien arbeiten, rufen Sie SpeechRecognition einfach direkt auf und achten Sie dabei auf einige Abhängigkeiten für den jeweiligen Anwendungsfall. Beachten Sie außerdem, dass Sie das PyAudio-Paket installieren müssen, um Mikrofoneingaben zu erhalten.
Recognizer-Klasse
Der Kern von SpeechRecognition ist die Recognizer-Klasse.
Der Hauptzweck der Recognizer-API besteht darin, Sprache zu erkennen. Jede API verfügt über verschiedene Einstellungen und Funktionen, um die Sprache der Audioquelle zu erkennen. Hier wähle ich „recognize_sphinx()“: CMU Sphinx – erfordert die Installation von PocketSphinx (unterstützt Offline-Spracherkennung). )
Dann müssen wir PocketSphinx über den Befehl pip installieren. Während des Installationsprozesses kann es auch zu einer großen Anzahl roter Schriftfehler kommen.
Verwendung von Audiodateien
Laden Sie die relevanten Audiodateien herunter und speichern Sie sie in einem bestimmten Verzeichnis (speichern Sie sie direkt auf dem Ubuntu-Desktop)
Hinweis:
Die AudioFile-Klasse kann durch den Pfad der Audiodatei initialisiert werden und ermöglicht das Lesen und Verarbeitung der Schnittstelle des Dateiinhalts-Kontextmanagers.
SpeechRecognition unterstützt derzeit die folgenden Dateitypen:
WAV: muss im PCM/LPCM-Format vorliegen
AIFF
-
AIFF-CFLAC: muss im ursprünglichen FLAC-Format vorliegen; OGG-FLAC-Format ist nicht verfügbar
Englische Spracherkennung
Nach Abschluss der oben genannten Grundarbeit können Sie die englische Spracherkennung durchführen.
(1) Öffnen Sie das Terminal.
(2) Geben Sie das Verzeichnis ein, in dem sich die Sprachtestdatei befindet (das Verzeichnis des Bloggers ist der Desktop).
(3) Öffnen Sie den Python-Interpreter.
(4) Geben Sie die relevanten Befehle wie unten gezeigt ein.
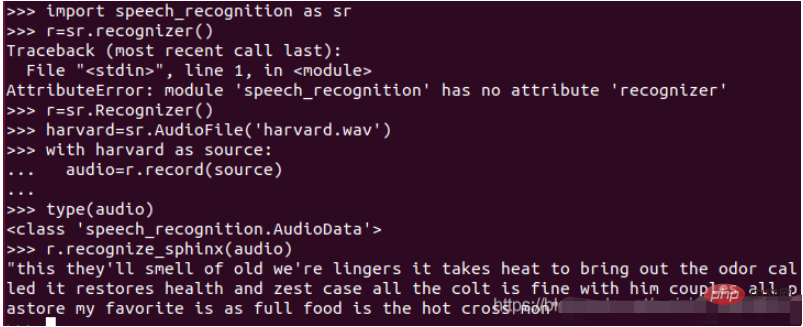
Endlich können Sie sehen, was den Speech-to-Text-Inhalt betrifft (das werden sie riechen...), der Effekt ist tatsächlich sehr gut! Weil es auf Englisch ist und es keinen Lärm gibt.
Der Einfluss von Lärm auf die Spracherkennung
Rauschen gibt es in der realen Welt, alle Aufnahmen weisen ein gewisses Maß an Rauschen auf und unverarbeitetes Rauschen kann die Genauigkeit von Spracherkennungsanwendungen beeinträchtigen.
Da der Versuch, den Effekt zu transkribieren, nicht gut ist, können wir versuchen, den Befehl „adjust_for_ambient_noise()“ der Recognizer-Klasse aufzurufen.
Mikrofonnutzung
Um SpeechRecognizer für den Zugriff auf das Mikrofon zu verwenden, müssen Sie das PyAudio-Paket installieren.
Wenn Sie Debian-basiertes Linux (z. B. Ubuntu) verwenden, können Sie apt verwenden, um PyAudio zu installieren: sudo apt-get install python-pyaudio python3-pyaudio Möglicherweise müssen Sie pip3 install pyaudio noch aktivieren nach Abschluss der Installation, insbesondere bei virtueller Ausführung. sudo apt-get install python-pyaudio python3-pyaudio安装完成后可能仍需要启用 pip3 install pyaudio ,尤其是在虚拟情况下运行。
在安装完pyaudio的情况下可以通过python实现语音录入生成相关文件。
pocketsphinx的使用注意:
支持文件格式:wav
音频文件的解码要求:16KHZ,单声道
利用python实现录音并生成相关文件程序代码如下:
from pyaudio import PyAudio, paInt16
import numpy as np
import wave
class recoder:
NUM_SAMPLES = 2000
SAMPLING_RATE = 16000
LEVEL = 500
COUNT_NUM = 20
SAVE_LENGTH = 8
Voice_String = []
def savewav(self,filename):
wf = wave.open(filename, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(self.SAMPLING_RATE)
wf.writeframes(np.array(self.Voice_String).tostring())
wf.close()
def recoder(self):
pa = PyAudio()
stream = pa.open(format=paInt16, channels=1, rate=self.SAMPLING_RATE, input=True,frames_per_buffer=self.NUM_SAMPLES)
save_count = 0
save_buffer = []
while True:
string_audio_data = stream.read(self.NUM_SAMPLES)
audio_data = np.fromstring(string_audio_data, dtype=np.short)
large_sample_count = np.sum(audio_data > self.LEVEL)
print(np.max(audio_data))
if large_sample_count > self.COUNT_NUM:
save_count = self.SAVE_LENGTH
else:
save_count -= 1
if save_count < 0:
save_count = 0
if save_count > 0:
save_buffer.append(string_audio_data )
else:
if len(save_buffer) > 0:
self.Voice_String = save_buffer
save_buffer = []
print("Recode a piece of voice successfully!")
return True
else:
return False
if __name__ == "__main__":
r = recoder()
r.recoder()
r.savewav("test.wav")注意:在利用python解释器实现时一定要注意空格!!!
最后生成的文件就在Python解释器回话所在目录下,可以通过play来播放测试一下,如果没有安装play可以通过apt命令来安装。
中文的语音识别
在进行完以前的工作以后,我们对语音识别的流程大概有了一定的了解,但是作为一个中国人总得做一个中文的语音识别吧!
我们要在CMU Sphinx语音识别工具包里面下载对应的普通话升学和语言模型。
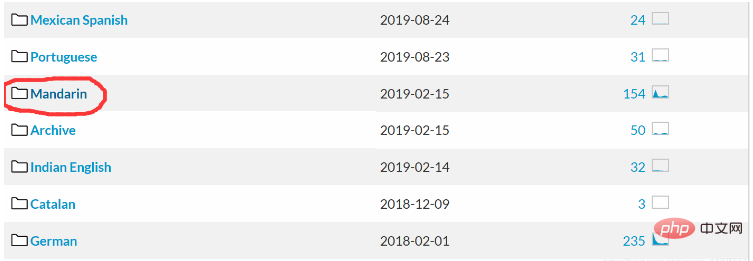
图片中标记的就是普通话!下载相关的语音识别工具包。
但是我们要把zh_broadcastnews_64000_utf8.DMP转化成language-model.lm.bin,再解压zh_broadcastnews_16k_ptm256_8000.tar.bz2得到zh_broadcastnews_ptm256_8000文件夹。
借鉴刚才那位博主的方法,在Ubuntu下找到speech_recognition文件夹。可能会有很多小伙伴找不到相关的文件夹,其实是在隐藏文件下。大家可以点击文件夹右上角的三条杠。如下图所示:

然后给显示隐藏文件打个勾,如下图所示:
然后依次按照以下目录就可以找到啦:

然后把原来的en-US改名成en-US-bak,新建一个文件夹en-US,把解压出来的zh_broadcastnews_ptm256_8000改成acoustic-model,把chinese.lm.bin改成language-model.lm.bin,把pronounciation-dictionary.dic改后缀成dictNach der Installation von Pyaudio können Sie Python verwenden, um Sprachaufzeichnungen und zugehörige Dateien zu generieren.
Hinweise zur Verwendung von Pocketsphinx:
Dekodierungsanforderungen für Audiodateien: 16KHZ, Mono  Verwenden Sie Python, um die Aufnahme zu implementieren und zugehörige Dateien zu generieren:
Verwenden Sie Python, um die Aufnahme zu implementieren und zugehörige Dateien zu generieren:
Hinweis: Unbedingt beachten Verwenden Sie zum Implementieren den Python-Interpreter. Achten Sie auf die Leerzeichen! ! !
Die endgültige generierte Datei befindet sich in dem Verzeichnis, in dem sich der Python-Interpreter befindet. Sie können sie über Play abspielen, um sie zu testen. Wenn Play nicht installiert ist, können Sie sie über den Befehl apt installieren.
Chinesische Spracherkennung
Nach Abschluss der vorherigen Arbeit haben wir ein gewisses Verständnis für den Spracherkennungsprozess, aber als Chinese müssen wir die chinesische Spracherkennung durchführen! 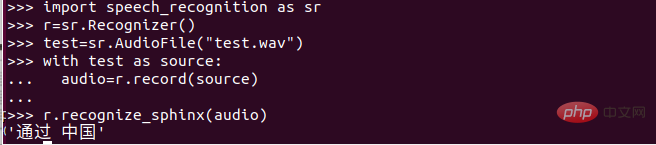
Auf dem Bild ist die Marke Mandarin! Laden Sie das entsprechende Spracherkennungs-Toolkit herunter.
Aber wir müssenzh_broadcastnews_64000_utf8.DMP in language-model.lm.bin konvertieren und dann zh_broadcastnews_16k_ptm256_8000.tar.bz2 entpacken, um den Ordner zh_broadcastnews_ptm256_8000 zu erhalten.
Lernen Sie jetzt von der Blogger-Methode und suchen Sie den Ordner „speech_recognition“ unter Ubuntu. Es mag viele Freunde geben, die die entsprechenden Ordner nicht finden können, sie befinden sich jedoch tatsächlich unter versteckten Dateien. Sie können auf die drei Balken in der oberen rechten Ecke des Ordners klicken. Wie im Bild unten gezeigt:
Dann folgen Sie den folgenden Verzeichnissen, um es zu finden:

en-US in en-US-bak, erstellen Sie einen neuen Ordner in den USA, ändern Sie den extrahierten <code>zh_broadcastnews_ptm256_8000 in acoustic-model und ändern Sie chinese.lm.bin in lingual-model.lm.bin, ändern Sie das Suffix von pronounciation-dictionary.dic in dict und kopieren Sie diese drei Dateien nach en-US . . Kopieren Sie gleichzeitig LICENSE.txt im ursprünglichen en-US-Dateiverzeichnis in den aktuellen Ordner. Schließlich befinden sich in diesem Ordner folgende Dateien:
🎜🎜🎜🎜 Anschließend können wir über das Mikrofon eine Sprachdatei („test.wav“) aufnehmen. 🎜Öffnen Sie den Python-Interpreter im Dateiverzeichnis und geben Sie folgenden Inhalt ein: 🎜🎜 🎜 🎜🎜Ich habe den Ausgabeinhalt gesehen, aber ich habe über zwei Chinas gesprochen. Ich habe auch andere getestet und festgestellt, dass der Erkennungseffekt sehr schlecht war! ! ! 🎜🎜🎜Chinesische Erkennung im kleinen Maßstab🎜🎜Die Wirkung der offiziellen Version ist so gering, dass sie fast unbrauchbar ist! Dann habe ich nach dem Lesen vieler Artikel über eine Optimierungsmethode nachgedacht, die jedoch nur für die Erkennung im kleinen Maßstab geeignet ist! Einige Befehle und Ähnliches sollten in Ordnung sein, aber Chatten und Ähnliches funktionieren möglicherweise nicht so gut. 🎜Suchen Sie die 4 Ordner, die Sie gerade kopiert haben. Nach dem Öffnen wird der folgende Inhalt gefunden: 🎜🎜🎜🎜🎜Es fühlt sich an, als ob dieser Inhalt einem Wörterbuch ähnelt, mit vielen Wörtern Worte für die tägliche Kommunikation sind relativ groß. Dann können wir es einfach in die Wörter ändern, die wir gewohnt sind! Mit der Idee, es auszuprobieren, ist das Ergebnis wirklich gut. Der Wiedererkennungseffekt ist wirklich gut! 🎜Mein Ansatz ist: 🎜(1) Behalten Sie den Inhalt oberhalb der roten Markierung im Bild bei und löschen Sie den Inhalt unterhalb der roten Markierung. Aus versicherungstechnischen Gründen empfiehlt es sich natürlich, diese Datei zu sichern! 🎜(2) Geben Sie unterhalb der roten Linie den Inhalt ein, den Sie identifizieren möchten! (Eingabe gemäß den Regeln, anders als Pinyin!!!) Die Situation der neuen Lungenentzündung hat sich in letzter Zeit verbessert. Der am häufigsten gehörte Satz ist „Come on China“. Ich hoffe, die Schule kann bald beginnen, hahahaha. 🎜🎜🎜🎜🎜3) Geben Sie Folgendes ein: 🎜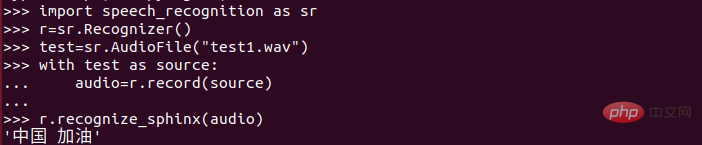
Sprachsynthese
Mein persönliches Verständnis von Sprachsynthese ist Text-to-Speech. Allerdings können Sie in diesem Satz Lautstärke, Ton, Geschwindigkeit, männlich/weiblich/loli/frei einstellen. client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('你好百度', 'zh', 1, { 'vol': 5,'spd': 3,'pit':9,'per': 3})
Das obige ist der detaillierte Inhalt vonSo verwenden Sie Python, um die Spracherkennungsfunktion unter Linux zu implementieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!