
Heim >Java >javaLernprogramm >Wie verwende ich ConcurrentHashMap, um eine threadsichere Zuordnung in Java zu implementieren?
Wie verwende ich ConcurrentHashMap, um eine threadsichere Zuordnung in Java zu implementieren?

- PHPznach vorne
- 2023-05-10 10:25:12956Durchsuche
jdk1.7-Version
Datenstruktur
/**
* The segments, each of which is a specialized hash table.
*/
final Segment<K,V>[] segments;Sie können sehen, dass es sich hauptsächlich um ein Segment-Array mit geschriebenen Kommentaren handelt, von denen jeder ein spezieller Hash ist Tisch .
Werfen wir einen Blick darauf, was Segment ist.
static final class Segment<K,V> extends ReentrantLock implements Serializable {
......
/**
* The per-segment table. Elements are accessed via
* entryAt/setEntryAt providing volatile semantics.
*/
transient volatile HashEntry<K,V>[] table;
transient int threshold;
final float loadFactor;
// 构造函数
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
......
}Das Obige ist Teil des Codes. Sie können sehen, dass Segment ReentrantLock erbt, sodass jedes Segment tatsächlich eine Sperre ist.
Das HashEntry-Array wird darin gespeichert und die Variable ist mit flüchtig versehen. HashEntry ähnelt dem Knoten von Hashmap und ist auch ein Knoten einer verknüpften Liste.
Werfen wir einen Blick auf den spezifischen Code. Sie können sehen, dass er sich geringfügig von Hashmap unterscheidet, da seine Mitgliedsvariablen mit volatile geändert werden.
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
......
}Die Datenstruktur von ConcurrentHashMap entspricht also fast der Abbildung unten.
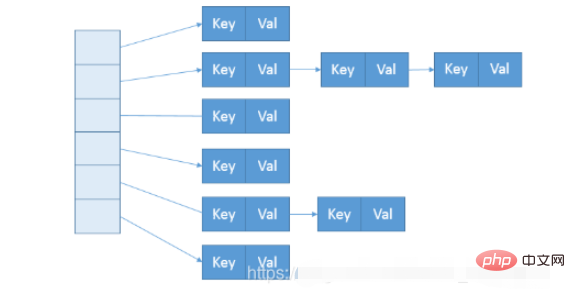
Während der Konstruktion wird die Anzahl der Segmente durch den sogenannten ConcurrentcyLevel bestimmt, der standardmäßig 16 beträgt. Er kann auch direkt im entsprechenden angegeben werden Konstrukteur. Beachten Sie, dass Java einen Zweierpotenzwert wie 15 erfordert, der automatisch auf einen Zweierpotenzwert wie 16 angepasst wird.
Werfen wir einen Blick auf den Quellcode, beginnend mit der einfachen Get-Methode
get()
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 通过unsafe获取Segment数组的元素
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 还是通过unsafe获取HashEntry数组的元素
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}Die Logik von get ist sehr einfach Dies bedeutet, das Segment zu finden, das dem Index des HashEntry-Arrays entspricht, dann den Header der verknüpften Liste zu finden, der dem Index im HashEntry-Array entspricht, und dann die verknüpfte Liste zu durchlaufen, um die Daten zu erhalten.
Um die Daten im Array abzurufen, verwenden Sie UNSAFE.getObjectVolatile(segments, u). Unsafe bietet die Möglichkeit, direkt auf den Speicher wie in der C-Sprache zuzugreifen. Diese Methode kann die Daten des entsprechenden Versatzes des Objekts abrufen. u ist ein berechneter Offset, also äquivalent zu segmentes[i], aber effizienter.
put()
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}Was die Put-Operation betrifft, wird das entsprechende Segment direkt durch die unsichere Aufrufmethode abgerufen und dann die threadsichere Put-Operation ausgeführt: #🎜 🎜## 🎜🎜#Die Hauptlogik ist die Put-Methode in Segment
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// scanAndLockForPut会去查找是否有key相同Node
// 无论如何,确保获取锁
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 更新已有value...
}
else {
// 放置HashEntry到特定位置,如果超过阈值,进行rehash
// ...
}
}
} finally {
unlock();
}
return oldValue;
}size()
Werfen wir einen Blick auf den Hauptcode,
for (;;) {
// 如果重试次数等于默认的2,就锁住所有的segment,来计算值
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// 如果sum不再变化,就表示得到了一个确切的值
if (sum == last)
break;
last = sum;
}# 🎜🎜#Dies ist tatsächlich die Summe der Zahlen aller Segmente. Wenn die Summe dem beim letzten Mal erhaltenen Wert entspricht, bedeutet dies, dass die Karte nicht relativ korrekt ist. Wenn Sie nach zweimaligem Wiederholen immer noch keinen einheitlichen Wert erhalten, sperren Sie alle Segmente und rufen Sie den Wert erneut ab. Erweiterungprivate void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 新表的大小是原来的两倍
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// 如果有多个节点
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// 这里操作就是找到末尾的一段索引值都相同的链表节点,这段的头结点是lastRun.
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// 然后将lastRun结点赋值给数组位置,这样lastRun后面的节点也跟着过去了。
newTable[lastIdx] = lastRun;
// 之后就是复制开头到lastRun之间的节点
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}jdk1.8-VersionDatenstrukturDie 1.8-Version von ConcurrentHashmap ist insgesamt etwas anders von Hashmap Wie, aber das Segment wird entfernt und stattdessen wird ein Array von Knoten verwendet. transient volatile Node<K,V>[] table;
In 1.8 gibt es immer noch eine interne Klasse namens Segment, deren Existenz jedoch nur der Serialisierungskompatibilität dient und nicht mehr verwendet wird. Werfen wir einen Blick auf den Knotenknoten static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
Node(int hash, K key, V val, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
......
}, der dem Knotenknoten in HashMap ähnelt und auch Map.Entry implementiert. Der Unterschied besteht darin, dass val und next geändert werden mit flüchtig, um Sichtbarkeit zu gewährleisten. put() final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
// 初始化
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 利用CAS去进行无锁线程安全操作,如果bin是空的
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {
// 细粒度的同步修改操作...
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 找到相同key就更新
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 没有相同的就新增
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果是树节点,进行树的操作
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// Bin超过阈值,进行树化
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}Sie können sehen, dass in der Synchronisationslogik synchronisiert statt des normalerweise empfohlenen ReentrantLock und dergleichen verwendet wird. In JDK1.8 wurde die Synchronisierung nun kontinuierlich optimiert, sodass Sie sich keine allzu großen Sorgen mehr über Leistungsunterschiede machen müssen. Darüber hinaus kann es im Vergleich zu ReentrantLock den Speicherverbrauch reduzieren, was ein sehr großer Vorteil ist. Gleichzeitig wurden detailliertere Implementierungen durch die Verwendung von Unsafe optimiert. Beispielsweise verwendet tabAt getObjectAcquire direkt, um den Overhead indirekter Aufrufe zu vermeiden. Werfen wir also einen Blick darauf, wie die Größe funktioniert? final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}Hier erhalten Sie die Mitgliedsvariable counterCells und durchlaufen, um die Gesamtzahl zu erhalten. Tatsächlich basiert der Betrieb von CounterCell auf java.util.concurrent.atomic.LongAdder. Dabei handelt es sich um eine Methode für JVM, Speicherplatz im Austausch für eine höhere Effizienz zu nutzen und dabei die komplexe Logik im Inneren zu nutzen Gestreift64. In den meisten Fällen wird die Verwendung von AtomicLong empfohlen, was ausreicht, um die Leistungsanforderungen der meisten Anwendungen zu erfüllen. Expansion private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
......
// 初始化
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// 是否继续处理下一个
boolean advance = true;
// 是否完成
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// 首次循环才会进来这里
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//扩容结束后做后续工作
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//每当一条线程扩容结束就会更新一次 sizeCtl 的值,进行减 1 操作
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
// 如果是null,设置fwd
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// 说明该位置已经被处理过了,不需要再处理
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
// 真正的处理逻辑
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
// 树节点操作
else if (f instanceof TreeBin) {
......
}
}
}
}
}
} }
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
// 树节点操作
else if (f instanceof TreeBin) {
......
}
}
}
}
}
}
Die Kernlogik ist dieselbe wie bei HashMap zum Erstellen zweier verknüpfter Listen, jedoch mit der Hinzufügung der Operation zum Abrufen von lastRun.
Das obige ist der detaillierte Inhalt vonWie verwende ich ConcurrentHashMap, um eine threadsichere Zuordnung in Java zu implementieren?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Wie gehe ich mit gleichzeitigen Verbindungen in der Java-Netzwerkprogrammierung um?
- Das innovative Potenzial von Java-Frameworks im Gesundheitswesen
- Welche Rollen und Vorteile hat Spring Cloud in der Microservice-Architektur?
- Die Entwicklungsvorteile des Java-Frameworks in Cloud-nativen Projekten
- Methoden zum Überladen der main()-Methode in Java: Ist das möglich?