
Heim >Backend-Entwicklung >Python-Tutorial >Wie implementiert man Multitasking und Multithreading mit Python?
Wie implementiert man Multitasking und Multithreading mit Python?

- PHPznach vorne
- 2023-05-10 09:13:443769Durchsuche
1 Multithreading zur Erzielung von Multitasking
1.1 Was ist ein Thread?
Der Prozess ist die Einheit, über die das Betriebssystem Programmausführungsressourcen zuweist, während der Thread eine Entität des Prozesses und die Einheit für die CPU-Planung und -Zuweisung ist. Ein Prozess muss einen Hauptthread haben. Wir können mehrere Threads in einem Prozess erstellen, um Multitasking zu erreichen.
1.2 Methoden zur Implementierung von Multitasking in einem Programm
Wir können mehrere Methoden verwenden, um Multitasking zu erreichen.
(1) Öffnen Sie mehrere Unterprozesse im Hauptprozess, und der Hauptprozess und mehrere Unterprozesse verarbeiten Aufgaben gemeinsam.
(2) Starten Sie mehrere Unterthreads im Hauptprozess, und der Hauptthread und mehrere Unterthreads verarbeiten Aufgaben gemeinsam.
(3) Öffnen Sie mehrere Coroutinen im Hauptprozess, und mehrere Coroutinen verarbeiten Aufgaben gemeinsam.
Hinweis: Da die Verwendung mehrerer Threads zur gemeinsamen Verarbeitung von Aufgaben zu Thread-Sicherheitsproblemen führt, werden in der Entwicklung im Allgemeinen Multiprozesse + Multi-Coroutinen verwendet, um Multitasking zu erreichen.
1.3 So erstellen Sie Multi-Threading
1.3.1 Erstellen von Threading.Thread-Objekten
import threading p1 = threading.Thread(target=[函数名],args=([要传入函数的参数])) p1.start() # 启动p1线程
Wir werden Multi-Threading simulieren, um Multi-Threading zu erreichen Aufgaben stellen.
Wenn Sie NetEase Cloud Music verwenden, um Songs anzuhören und sie gleichzeitig herunterzuladen. NetEase Cloud Music ist ein Prozess. Angenommen, das interne Programm von NetEase Cloud Music verwendet Multithreading, um Multitasking zu erreichen, und NetEase Cloud Music öffnet zwei Unterthreads. Einer dient zum Zwischenspeichern von Musik für die aktuelle Wiedergabe. Einer wird zum Herunterladen der Musik verwendet, die der Benutzer herunterladen möchte. Das Code-Framework sieht derzeit wie folgt aus:
import threading
import time
def listen_music(name):
while True:
time.sleep(1)
print(name,"正在播放音乐")
def download_music(name):
while True:
time.sleep(2)
print(name,"正在下载音乐")
if __name__ == "__main__":
p1 = threading.Thread(target=listen_music,args=("网易云音乐",))
p2 = threading.Thread(target=download_music,args=("网易云音乐",))
p1.start()
p2.start()Ausgabe:
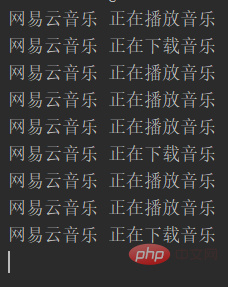
Wenn Sie den obigen Ausgabecode beobachten, können Sie Folgendes wissen: #🎜 🎜#
Die CPU führt untergeordnete Threads im Zeitscheiben-Polling-Verfahren aus. Die CPU wird Zeitscheiben intern sinnvoll zuteilen. Wenn die Zeitscheibe Programm a erreicht und Programm a schläft, wechselt es automatisch zu Programm b. Genau genommen führt die CPU zu einem bestimmten Zeitpunkt nur eine Aufgabe aus, aber aufgrund der hohen Laufgeschwindigkeit und Schaltgeschwindigkeit der CPU sieht es so aus, als würden mehrere Aufgaben gleichzeitig ausgeführt. 1.3.2 Threading erben. Thread ausführen und neu schreiben Zusätzlich zu der oben genannten Methode zum Erstellen eines Threads gibt es eine weitere Methode. Sie können eine Klasse schreiben, die die Klasse threading.Thread erbt und dann die Ausführungsmethode der übergeordneten Klasse überschreibt.import threading
import time
class MyThread(threading.Thread):
def run(self):
for i in range(5):
time.sleep(1)
print(self.name,i)
t1 = MyThread()
t2 = MyThread()
t3 = MyThread()
t1.start()
t2.start()
t3.start()Ausgabe:
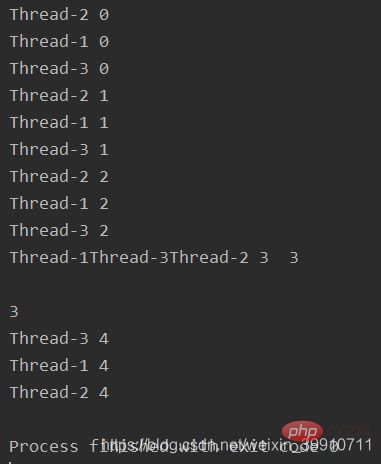
- start(): Nachdem Sie den Thread erstellt haben, starten Sie den Thread durchstarten und warten. Vorbereitung für die Ausführung der Ausführungsfunktion; Vom Benutzer geschriebene Funktion wird im Funktionskörper aufgerufen oder ausgeführt. Überladene Ausführungsfunktion; bis der aufgerufene Thread die Ausführung abschließt oder eine Zeitüberschreitung auftritt. Diese Methode wird normalerweise im Hauptthread aufgerufen und wartet darauf, dass andere Threads die Ausführung abschließen.
- name, getName()&setName(): Thread-Namensbezogene Operationen; des Thread-Bezeichners, der None ist, bevor der Thread mit der Ausführung beginnt (vor dem Aufruf von start); Die Ausführungsfunktion wird bis zum Ende ausgeführt. #daemon, isDaemon()&setDaemon(): Daemon-Thread bezogen auf; wann endet es
-
(1) Wann startet der Sub-Thread und wann wird er ausgeführt? Wenn thread.start() aufgerufen wird, starten Sie den Thread und führen Sie dann den Code des Threads aus
(2) Wann endet der Sub-Thread, nachdem der Sub-Thread die Anweisung in der Funktion ausgeführt hat, auf die das Ziel zeigt, oder nachdem der Ausführungsfunktionscode im Thread die Ausführung abgeschlossen hat, wird der aktuelle Sub-Thread sofort beendet? thread -
(3) Überprüfen Sie die aktuelle Anzahl der Threads und zählen Sie alle aktuell laufenden Threads über threading.enumerate()
(4) Wann endet der Hauptthread? Unterthreads sind mit der Ausführung fertig, der Hauptthread ist gerade zu Ende gegangen -
Beispiel 1:
import threading import time def run(): for i in range(5): time.sleep(1) print(i) t1 = threading.Thread(target=run) t1.start() print("我会在哪里出现")Ausgabe: - Warum wird der Hauptprozesscode (Hauptthread) zuerst angezeigt? Da die CPU Zeitscheibenabfragen verwendet, wird der Hauptthread zuerst ausgeführt, wenn der Sub-Thread abgefragt wird und festgestellt wird, dass er eine Sekunde lang schlafen möchte. Daher kann
CPUs Zeitscheibenabfragemethode
den optimalen Betrieb der CPU sicherstellen. Was passiert, wenn ich möchte, dass der vom Hauptprozess ausgegebene Satz am Ende ausgeführt wird? Was zu tun? Zu diesem Zeitpunkt müssen Sie die Methode
verwenden.
1.5 Join()-Methode des Threads
import threading
import time
def run():
for i in range(5):
time.sleep(1)
print(i)
t1 = threading.Thread(target=run)
t1.start()
t1.join()
print("我会在哪里出现")Ausgabe:
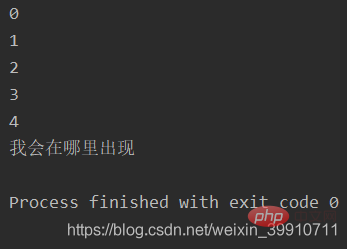
join() 方法可以阻塞主线程(注意只能阻塞主线程,其他子线程是不能阻塞的),直到 t1 子线程执行完,再解阻塞。
1.6 多线程共享全局变量出现的问题
我们开两个子线程,全局变量是0,我们每个线程对他自加1,每个线程加一百万次,这时候就会出现问题了,来,看代码:
import threading
import time
num = 0
def work1(loop):
global num
for i in range(loop):
# 等价于 num += 1
temp = num
num = temp + 1
print(num)
def work2(loop):
global num
for i in range(loop):
# 等价于 num += 1
temp = num
num = temp + 1
print(num)
if __name__ == "__main__":
t1 = threading.Thread(target=work1,args=(1000000,))
t2 = threading.Thread(target=work2, args=(1000000,))
t1.start()
t2.start()
while len(threading.enumerate()) != 1:
time.sleep(1)
print(num)输出
1459526 # 第一个子线程结束后全局变量一共加到这个数
1588806 # 第二个子线程结束后全局变量一共加到这个数
1588806 # 两个线程都结束后,全局变量一共加到这个数
奇怪了,我不是每个线程都自加一百万次吗?照理来说,应该最后的结果是200万才对的呀。问题出在哪里呢?
我们知道CPU是采用时间片轮询的方式进行几个线程的执行。
假设我CPU先轮询到work1(),num此时为100,在我运行到第10行时,时间结束了!此时,赋值了,但是还没有自加!即temp=100,num=100。
然后,时间片轮询到了work2(),进行赋值自加。num=101了。
又回到work1()的断点处,num=temp+1,temp=100,所以num=101。
就这样!num少了一次自加!在次数多了之后,这样的错误积累在一起,结果只得到158806!
这就是线程安全问题!
1.7 互斥锁可以弥补部分线程安全问题。(互斥锁和GIL锁是不一样的东西!)
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
互斥锁有三个常用步骤:
lock = threading.Lock() # 取得锁 lock.acquire() # 上锁 lock.release() # 解锁
下面让我们用互斥锁来解决上面例子的线程安全问题。
import threading
import time
num = 0
lock = threading.Lock() # 取得锁
def work1(loop):
global num
for i in range(loop):
# 等价于 num += 1
lock.acquire() # 上锁
temp = num
num = temp + 1
lock.release() # 解锁
print(num)
def work2(loop):
global num
for i in range(loop):
# 等价于 num += 1
lock.acquire() # 上锁
temp = num
num = temp + 1
lock.release() # 解锁
print(num)
if __name__ == "__main__":
t1 = threading.Thread(target=work1,args=(1000000,))
t2 = threading.Thread(target=work2, args=(1000000,))
t1.start()
t2.start()
while len(threading.enumerate()) != 1:
time.sleep(1)
print(num)输出:
1945267 # 第一个子线程结束后全局变量一共加到这个数
2000000 # 第二个子线程结束后全局变量一共加到这个数
2000000 # 两个线程都结束后,全局变量一共加到这个数
1.8 线程池ThreadPoolExecutor
从Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对threading和multiprocessing的进一步抽象(这里主要关注线程池),不仅可以帮我们自动调度线程,还可以做到:
主线程可以获取某一个线程(或者任务的)的状态,以及返回值。
当一个线程完成的时候,主线程能够立即知道。
让多线程和多进程的编码接口一致。
1.8.1 创建线程池
示例:
from concurrent.futures import ThreadPoolExecutor
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
# 通过submit函数提交执行的函数到线程池中,submit函数立即返回,不阻塞
task1 = executor.submit(get_html, (3))
task2 = executor.submit(get_html, (2))
# done方法用于判定某个任务是否完成
print("1: ", task1.done())
# cancel方法用于取消某个任务,该任务没有放入线程池中才能取消成功
print("2: ", task2.cancel())
time.sleep(4)
print("3: ", task1.done())
# result方法可以获取task的执行结果
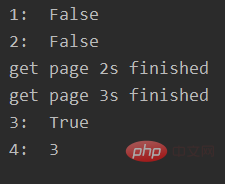
print("4: ", task1.result())输出:
ThreadPoolExecutor构造实例的时候,传入max_workers参数来设置线程池中最多能同时运行的线程数目。
使用submit函数来提交线程需要执行的任务(函数名和参数)到线程池中,并返回该任务的句柄(类似于文件、画图),注意submit()不是阻塞的,而是立即返回。
通过submit函数返回的任务句柄,能够使用done()方法判断该任务是否结束。上面的例子可以看出,由于任务有2s的延时,在task1提交后立刻判断,task1还未完成,而在延时4s之后判断,task1就完成了。
使用cancel()方法可以取消提交的任务,如果任务已经在线程池中运行了,就取消不了。这个例子中,线程池的大小设置为2,任务已经在运行了,所以取消失败。如果改变线程池的大小为1,那么先提交的是task1,task2还在排队等候,这是时候就可以成功取消。
使用result()方法可以获取任务的返回值。查看内部代码,发现这个方法是阻塞的。
1.8.2 as_completed
上面虽然提供了判断任务是否结束的方法,但是不能在主线程中一直判断啊。有时候我们是得知某个任务结束了,就去获取结果,而不是一直判断每个任务有没有结束。这是就可以使用as_completed方法一次取出所有任务的结果。
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
all_task = [executor.submit(get_html, (url)) for url in urls]
for future in as_completed(all_task):
data = future.result()
print("in main: get page {}s success".format(data))
# 执行结果
# get page 2s finished
# in main: get page 2s success
# get page 3s finished
# in main: get page 3s success
# get page 4s finished
# in main: get page 4s success as_completed()方法是一个生成器,在没有任务完成的时候,会阻塞,在有某个任务完成的时候,会yield这个任务,就能执行for循环下面的语句,然后继续阻塞住,循环到所有的任务结束。从结果也可以看出,先完成的任务会先通知主线程。
1.8.3 map
除了上面的as_completed方法,还可以使用executor.map方法,但是有一点不同。
from concurrent.futures import ThreadPoolExecutor
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
for data in executor.map(get_html, urls):
print("in main: get page {}s success".format(data))
# 执行结果
# get page 2s finished
# get page 3s finished
# in main: get page 3s success
# in main: get page 2s success
# get page 4s finished
# in main: get page 4s success 使用map方法,无需提前使用submit方法,map方法与python标准库中的map含义相同,都是将序列中的每个元素都执行同一个函数。上面的代码就是对urls的每个元素都执行get_html函数,并分配各线程池。可以看到执行结果与上面的as_completed方法的结果不同,输出顺序和urls列表的顺序相同,就算2s的任务先执行完成,也会先打印出3s的任务先完成,再打印2s的任务完成。
1.8.4 wait
wait方法可以让主线程阻塞,直到满足设定的要求。
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED, FIRST_COMPLETED
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
all_task = [executor.submit(get_html, (url)) for url in urls]
wait(all_task, return_when=ALL_COMPLETED)
print("main")
# 执行结果
# get page 2s finished
# get page 3s finished
# get page 4s finished
# main wait方法接收3个参数,等待的任务序列、超时时间以及等待条件。等待条件return_when默认为ALL_COMPLETED,表明要等待所有的任务都结束。可以看到运行结果中,确实是所有任务都完成了,主线程才打印出main。等待条件还可以设置为FIRST_COMPLETED,表示第一个任务完成就停止等待。
2 多进程实行多任务
2.1 多线程的创建方式
创建进程的方式和创建线程的方式类似:
实例化一个multiprocessing.Process的对象,并传入一个初始化函数对象(initial function )作为新建进程执行入口;
继承multiprocessing.Process,并重写run函数;
2.1.1 方式1
在开始之前,我们要知道什么是进程。道理很简单,你平时电脑打开QQ客户端,就是一个进程。再打开一个QQ客户端,又是一个进程。那么,在python中如何用一篇代码就可以开启几个进程呢?通过一个简单的例子来演示:
import multiprocessing
import time
def task1():
while True:
time.sleep(1)
print("I am task1")
def task2():
while True:
time.sleep(2)
print("I am task2")
if __name__ == "__main__":
p1 = multiprocessing.Process(target=task1) # multiprocessing.Process创建了子进程对象p1
p2 = multiprocessing.Process(target=task2) # multiprocessing.Process创建了子进程对象p2
p1.start() # 子进程p1启动
p2.start() # 子进程p2启动
print("I am main task") # 这是主进程的任务输出:
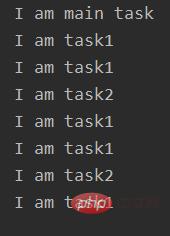
可以看到子进程对象是由multiprocessing模块中的Process类创建的。除了p1,p2两个被创建的子进程外。当然还有主进程。主进程就是我们从头到尾的代码,包括子进程也是由主进程创建的。
注意的点有:
(1)首先解释一下并发:并发就是当任务数大于cpu核数时,通过操作系统的各种任务调度算法,实现多个任务“一起”执行。(实际上总有一些任务不在执行,因为切换任务相当快,看上去想同时执行而已。)
(2)当是并发的情况下,子进程与主进程的运行都是没有顺序的,CPU会采用时间片轮询的方式,哪个程序先要运行就先运行哪个。
(3)主进程会默认等待所有子进程执行完毕后,它才会退出。所以在上面的例子中,p1,p2子进程是死循环进程,主进程的最后一句代码print("I am main task")虽然运行完了,但是主进程并不会关闭,他会一直等待着子进程。
(4)主进程默认创建的是非守护进程。注意,结合3.和5.看。
(5)但是!如果子进程是守护进程的话,那么主进程运行完最后一句代码后,主进程会直接关闭,不管你子进程运行完了没有!
2.1.2 方式2
from multiprocessing import Process
import os, time
class CustomProcess(Process):
def __init__(self, p_name, target=None):
# step 1: call base __init__ function()
super(CustomProcess, self).__init__(name=p_name, target=target, args=(p_name,))
def run(self):
# step 2:
# time.sleep(0.1)
print("Custom Process name: %s, pid: %s "%(self.name, os.getpid()))
if __name__ == "__main__":
p1 = CustomProcess("process_1")
p1.start()
p1.join()
print("subprocess pid: %s"%p1.pid)
print("current process pid: %s" % os.getpid())输出:
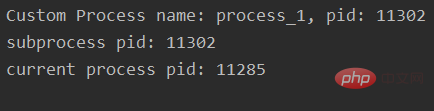
这里可以思考一下,如果像多线程一样,存在一个全局的变量share_data,不同进程同时访问share_data会有问题吗?
由于每一个进程拥有独立的内存地址空间且互相隔离,因此不同进程看到的share_data是不同的、分别位于不同的地址空间,同时访问不会有问题。这里需要注意一下。
2.2 守护进程
测试下:
import multiprocessing
import time
def task1():
while True:
time.sleep(1)
print("I am task1")
def task2():
while True:
time.sleep(2)
print("I am task2")
if __name__ == "__main__":
p1 = multiprocessing.Process(target=task1)
p2 = multiprocessing.Process(target=task2)
p1.daemon = True # 设置p1子进程为守护进程
p2.daemon = True # 设置p2子进程为守护进程
p1.start()
p2.start()
print("I am main task")输出:
I am main task
输出结果是不是有点奇怪。为什么p1,p2子进程都没有输出的?
让我们来整理一下思路:
创建p1,p2子进程
设置p1,p2子进程为守护进程
p1,p2子进程开启
p1,p2子进程代码里面都有休眠时间,所以cpu为了不浪费时间,先做主进程后续的代码。
执行主进程后续的代码,print("I am main task")
主进程后续的代码执行完成了,所以剩下的子进程是守护进程的,全都要关闭了。但是,如果主进程的代码执行完了,有两个子进程,一个是守护的,一个非守护的,怎么办呢?其实,他会等待非守护的那个子进程运行完,然后三个进程一起关闭。
p1,p2还在休眠时间内就被终结生命了,所以什么输出都没有。
例如,把P1设为非守护进程:
import multiprocessing
import time
def task1():
i = 1
while i < 5:
time.sleep(1)
i += 1
print("I am task1")
def task2():
while True:
time.sleep(2)
print("I am task2")
if __name__ == "__main__":
p1 = multiprocessing.Process(target=task1)
p2 = multiprocessing.Process(target=task2)
p2.daemon = True # 设置p2子进程为守护进程
p1.start()
p2.start()
print("I am main task")输出:
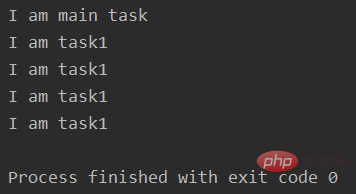
里面涉及到两个知识点:
(1)当主进程结束后,会发一个消息给子进程(守护进程),守护进程收到消息,则立即结束
(2)CPU是按照时间片轮询的方式来运行多进程的。哪个合适的哪个运行,如果你的子进程里都有time.sleep。那我CPU为了不浪费资源,肯定先去干点其他的事情啊。
那么,守护进程随时会被中断,他的存在意义在哪里的?
其实,守护进程主要用来做与业务无关的任务,无关紧要的任务,可有可无的任务,比如内存垃圾回收,某些方法的执行时间的计时等。
2.3 创建的子进程要传入参数
import multiprocessing
def task(a,b,*args,**kwargs):
print("a")
print("b")
print(args)
print(kwargs)
if __name__ == "__main__":
p1 = multiprocessing.Process(target=task,args=(1,2,3,4,5,6),kwargs={"name":"chichung","age":23})
p1.start()
print("主进程已经运行完最后一行代码啦")输出:
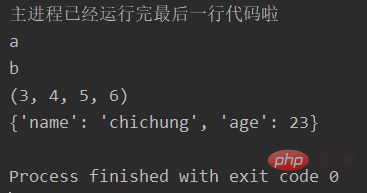
子进程要运行的函数需要传入变量a,b,一个元组,一个字典。我们创建子进程的时候,变量a,b要放进元组里面,task函数取的时候会把前两个取出来,分别赋值给a,b了。
2.4 子进程几个常用的方法
| p.start | 开始执行子线程 |
| p.name | 查看子进程的名称 |
| p.pid | 查看子进程的id |
| p.is_alive | 判断子进程是否存活 |
| p.join(timeout) |
阻塞主进程,当子进程p运行完毕后,再解开阻塞,让主进程运行后续的代码 如果timeout=2,就是阻塞主进程2s,这2s内主进程不能运行后续的代码。过了2s后,就算子进程没有运行完毕,主进程也能运行后续的代码 |
| p.terminate | 终止子进程p的运行 |
import multiprocessing
def task(a,b,*args,**kwargs):
print("a")
print("b")
print(args)
print(kwargs)
if __name__ == "__main__":
p1 = multiprocessing.Process(target=task,args=(1,2,3,4,5,6),kwargs={"name":"chichung","age":23})
p1.start()
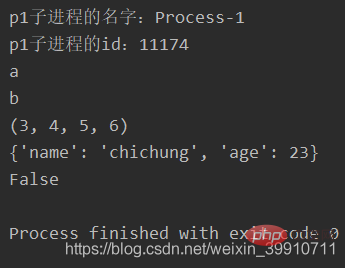
print("p1子进程的名字:%s" % p1.name)
print("p1子进程的id:%d" % p1.pid)
p1.join()
print(p1.is_alive())输出:
2.5 进程之间是不可以共享全局变量
进程之间是不可以共享全局变量的,即使子进程与主进程。道理很简单,一个新的进程,其实就是占用一个新的内存空间,不同的内存空间,里面的变量肯定不能够共享的。实验证明如下:
示例一:
import multiprocessing
g_list = [123]
def task1():
g_list.append("task1")
print(g_list)
def task2():
g_list.append("task2")
print(g_list)
def main_process():
g_list.append("main_processs")
print(g_list)
if __name__ == "__main__":
p1 = multiprocessing.Process(target=task1)
p2 = multiprocessing.Process(target=task2)
p1.start()
p2.start()
main_process()
print("11111: ", g_list)输出:
[123, "main_processs"]
11111: [123, "main_processs"]
[123, "task1"]
[123, "task2"]
示例二:
import multiprocessing
import time
def task1(loop):
global num
for i in range(loop):
# 等价于 num += 1
temp = num
num = temp + 1
print(num)
print("I am task1")
def task2(loop):
global num
for i in range(loop):
# 等价于 num += 1
temp = num
num = temp + 1
print(num)
print("I am task2")
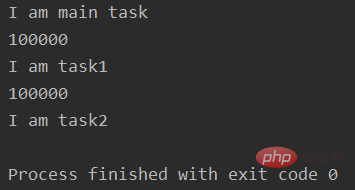
if __name__ == "__main__":
p1 = multiprocessing.Process(target=task1, args=(100000,) # multiprocessing.Process创建了子进程对象p1
p2 = multiprocessing.Process(target=task2, args=(100000,) # multiprocessing.Process创建了子进程对象p2
p1.start() # 子进程p1启动
p2.start() # 子进程p2启动
print("I am main task") # 这是主进程的任务输出:
2.6 python进程池:multiprocessing.pool
进程池可以理解成一个队列,该队列可以容易指定数量的子进程,当队列被任务占满之后,后续新增的任务就得排队,直到旧的进程有任务执行完空余出来,才会去执行新的任务。
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
Pool可以提供指定数量的进程供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来它。
2.6.1 使用进程池(非阻塞)
#coding: utf-8
import multiprocessing
import time
def func(msg):
print("msg:", msg)
time.sleep(3)
print("end")
if __name__ == "__main__":
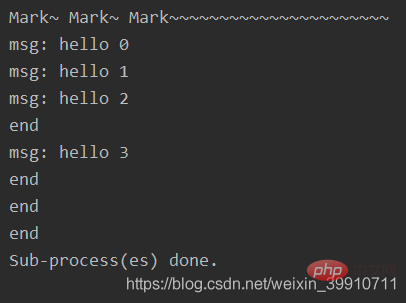
pool = multiprocessing.Pool(processes = 3) # 设定进程的数量为3
for i in range(4):
msg = "hello %d" %(i)
pool.apply_async(func, (msg, )) #维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
print("Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~")
pool.close()
pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print("Sub-process(es) done.")输出:
函数解释:
apply_async(func[, args[, kwds[, callback]]]) 它是非阻塞,apply(func[, args[, kwds]])是阻塞的(理解区别,看例1例2结果区别)
close() 关闭pool,使其不在接受新的任务。
terminate() 结束工作进程,不在处理未完成的任务。
join() 主进程阻塞,等待子进程的退出, join方法要在close或terminate之后使用。
apply(), apply_async():
apply(): 阻塞主进程, 并且一个一个按顺序地执行子进程, 等到全部子进程都执行完毕后 ,继续执行 apply()后面主进程的代码apply_async()非阻塞异步的, 他不会等待子进程执行完毕, 主进程会继续执行, 他会根据系统调度来进行进程切换
执行说明:创建一个进程池pool,并设定进程的数量为3,xrange(4)会相继产生四个对象[0, 1, 2, 4],四个对象被提交到pool中,因pool指定进程数为3,所以0、1、2会直接送到进程中执行,当其中一个执行完事后才空出一个进程处理对象3,所以会出现输出“msg: hello 3”出现在"end"后。因为为非阻塞,主函数会自己执行自个的,不搭理进程的执行,所以运行完for循环后直接输出“mMsg: hark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~”,主程序在pool.join()处等待各个进程的结束。
2.6.2 使用进程池(阻塞)
#coding: utf-8
import multiprocessing
import time
def func(msg):
print("msg:", msg)
time.sleep(3)
print("end")
if __name__ == "__main__":
pool = multiprocessing.Pool(processes = 3) # 设定进程的数量为3
for i in range(4):
msg = "hello %d" %(i)
pool.apply(func, (msg, )) #维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去
print("Mark~ Mark~ Mark~~~~~~~~~~~~~~~~~~~~~~")
pool.close()
pool.join() #调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool,join函数等待所有子进程结束
print("Sub-process(es) done.")输出:

2.6.3 使用进程池,并关注结果
import multiprocessing
import time
def func(msg):
print("msg:", msg)
time.sleep(3)
print("end")
return "done" + msg
if __name__ == "__main__":
pool = multiprocessing.Pool(processes=4)
result = []
for i in range(3):
msg = "hello %d" %(i)
result.append(pool.apply_async(func, (msg, )))
pool.close()
pool.join()
for res in result:
print(":::", res.get())
print("Sub-process(es) done.")输出:
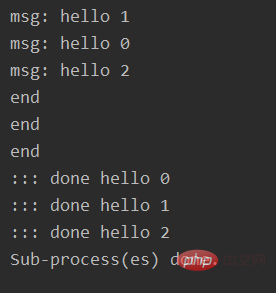
注:get()函数得出每个返回结果的值
3 python多线程与多进程比较
先来看两个例子:
(1)示例一,多线程与单线程,开启两个python线程分别做一亿次加一操作,和单独使用一个线程做一亿次加一操作:
import threading
import time
def tstart(arg):
var = 0
for i in range(100000000):
var += 1
print(arg, var)
if __name__ == "__main__":
t1 = threading.Thread(target=tstart, args=("This is thread 1",))
t2 = threading.Thread(target=tstart, args=("This is thread 2",))
start_time = time.time()
t1.start()
t2.start()
t1.join()
t2.join()
print("Two thread cost time: %s" % (time.time() - start_time))
start_time = time.time()
tstart("This is thread 0")
print("Main thread cost time: %s" % (time.time() - start_time))输出:
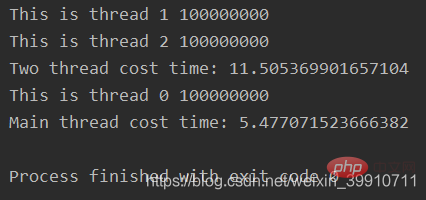
上面的例子如果只开启t1和t2两个线程中的一个,那么运行时间和主线程基本一致。
(2)示例二,使用两个进程
from multiprocessing import Process
import os, time
def pstart(arg):
var = 0
for i in range(100000000):
var += 1
print(arg, var)
if __name__ == "__main__":
p1 = Process(target = pstart, args = ("1", ))
p2 = Process(target = pstart, args = ("2", ))
start_time = time.time()
p1.start()
p2.start()
p1.join()
p2.join()
print("Two process cost time: %s" % (time.time() - start_time))
start_time = time.time()
pstart("0")
print("Current process cost time: %s" % (time.time() - start_time))输出:
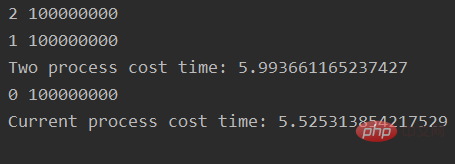
对比分析:
双进程并行执行和单进程执行相同的运算代码,耗时基本相同,双进程耗时会稍微多一些,可能的原因是进程创建和销毁会进行系统调用,造成额外的时间开销。
但是对于python线程,双线程并行执行耗时比单线程要高的多,效率相差近10倍。如果将两个并行线程改成串行执行,即:
import threading
import time
def tstart(arg):
var = 0
for i in range(100000000):
var += 1
print(arg, var)
if __name__ == "__main__":
t1 = threading.Thread(target=tstart, args=("This is thread 1",))
t2 = threading.Thread(target=tstart, args=("This is thread 2",))
start_time = time.time()
t1.start()
t1.join()
print("thread1 cost time: %s" % (time.time() - start_time))
start_time = time.time()
t2.start()
t2.join()
print("thread2 cost time: %s" % (time.time() - start_time))
start_time = time.time()
tstart("This is thread 0")
print("Main thread cost time: %s" % (time.time() - start_time))输出:
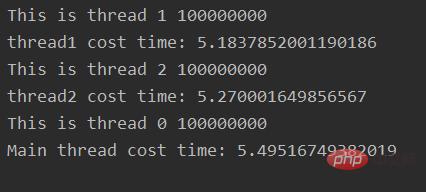
可以看到三个线程串行执行,每一个执行的时间基本相同。
本质原因双线程是并发执行的,而不是真正的并行执行。原因就在于GIL锁。
4 GIL锁
提起python多线程就不得不提一下GIL(Global Interpreter Lock 全局解释器锁),这是目前占统治地位的python解释器CPython中为了保证数据安全所实现的一种锁。不管进程中有多少线程,只有拿到了GIL锁的线程才可以在CPU上运行,即使是多核处理器。对一个进程而言,不管有多少线程,任一时刻,只会有一个线程在执行。对于CPU密集型的线程,其效率不仅仅不高,反而有可能比较低。python多线程比较适用于IO密集型的程序。对于的确需要并行运行的程序,可以考虑多进程。
多线程对锁的争夺,CPU对线程的调度,线程之间的切换等均会有时间开销。
5 线程和进程比较
5.1 线程和进程的区别
下面简单的比较一下线程与进程
进程是资源分配的基本单位,线程是CPU执行和调度的基本单位;
通信/同步方式:
同步方式:互斥锁,递归锁,条件变量,信号量
通信方式:位于同一进程的线程共享进程资源,因此线程间没有类似于进程间用于数据传递的通信方式,线程间的通信主要是用于线程同步。
通信方式:管道,FIFO,消息队列,信号,共享内存,socket,stream流;
同步方式:PV信号量,管程
进程:
线程:
CPU上真正执行的是线程,线程比进程轻量,其切换和调度代价比进程要小;
线程间对于共享的进程数据需要考虑线程安全问题,由于进程之间是隔离的,拥有独立的内存空间资源,相对比较安全,只能通过上面列出的IPC(Inter-Process Communication)进行数据传输;
系统有一个个进程组成,每个进程包含代码段、数据段、堆空间和栈空间,以及操作系统共享部分 ,有等待,就绪和运行三种状态;
一个进程可以包含多个线程,线程之间共享进程的资源(文件描述符、全局变量、堆空间等),寄存器变量和栈空间等是线程私有的;
操作系统中一个进程挂掉不会影响其他进程,如果一个进程中的某个线程挂掉而且OS对线程的支持是多对一模型,那么会导致当前进程挂掉;
如果CPU和系统支持多线程与多进程,多个进程并行执行的同时,每个进程中的线程也可以并行执行,这样才能最大限度的榨取硬件的性能;

5.2 线程和进程的上下文切换
进程切换过程切换牵涉到非常多的东西,寄存器内容保存到任务状态段TSS,切换页表,堆栈等。简单来说可以分为下面两步:
页全局目录切换,使CPU到新进程的线性地址空间寻址;
切换内核态堆栈和硬件上下文,硬件上下文包含CPU寄存器的内容,存放在TSS中;
线程运行于进程地址空间,切换过程不涉及到空间的变换,只牵涉到第二步;
5.3 Multithreading oder Multiprozess verwenden?
-
CPU-intensiv: Das Programm muss die CPU für viele Berechnungen und Datenverarbeitung belegen, die für mehrere Prozesse geeignet ist;
#🎜 🎜# I/O-intensiv: Das Programm erfordert häufige I/O-Vorgänge; z. B. Socket-Datenübertragung und -Lesen im Netzwerk für Multithreading# 🎜🎜#
Da Python-Multithreading nicht parallel ausgeführt wird, eignet es sich besser für E/A-intensive Programme und die parallele Ausführung mehrerer Prozesse geeignet für CPU-intensive Programme
Das obige ist der detaillierte Inhalt vonWie implementiert man Multitasking und Multithreading mit Python?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Ein Anfänger -Leitfaden für HTTP -Python -Anfragen
- Ein Leitfaden für Python Lambda -Funktionen mit Beispielen
- Try vs. If in Python: Wann sollten Sie beide für die Variablenauswertung verwenden?
- Wie führe ich die Erstellung bedingter Spalten in Pythons Pandas DataFrames durch?
- Können SyntaxErrors nach der Codekompilierung in Python abgefangen werden?