
Heim >Backend-Entwicklung >Python-Tutorial >Wie verwende ich die Jieba-Bibliothek in Python?
Wie verwende ich die Jieba-Bibliothek in Python?

- PHPznach vorne
- 2023-05-09 23:10:076804Durchsuche
Tutorial zur Verwendung und Installation der Jieba-Bibliothek (Bibliothek zur Segmentierung chinesischer Wörter) in Python
Einführung
Jieba ist eine hervorragende Bibliothek eines Drittanbieters für die Segmentierung chinesischer Wörter. Da jedes chinesische Zeichen im chinesischen Text kontinuierlich geschrieben wird, müssen wir eine bestimmte Methode verwenden, um jedes Wort darin zu erhalten. Diese Methode wird als Wortsegmentierung bezeichnet. Jieba ist eine hervorragende Drittanbieterbibliothek für die Segmentierung chinesischer Wörter im Python-Computing-Ökosystem. Sie müssen sie installieren, um sie verwenden zu können. Die
jieba-Bibliothek bietet drei Wortsegmentierungsmodi. Um jedoch den Wortsegmentierungseffekt zu erzielen, reicht es aus, nur eine Funktion zu beherrschen, was sehr einfach und effektiv ist.
Um Bibliotheken von Drittanbietern zu installieren, müssen Sie das Pip-Tool verwenden und den Installationsbefehl in der Befehlszeile (nicht im Leerlauf) ausführen. Hinweis: Sie müssen das Python-Verzeichnis und das Scripts-Verzeichnis darunter zu den Umgebungsvariablen hinzufügen.
Verwenden Sie den Befehl pip install jieba, um die Bibliothek eines Drittanbieters zu installieren. Nach der Installation wird die Meldung „Erfolgreich installiert“ angezeigt, um Sie darüber zu informieren, ob die Installation erfolgreich war.
Prinzip der Wortsegmentierung: Einfach ausgedrückt identifiziert die Jieba-Bibliothek die Wortsegmentierung anhand der chinesischen Vokabularbibliothek. Es verwendet zunächst ein chinesisches Lexikon, um die Assoziationswahrscheinlichkeiten zwischen chinesischen Schriftzeichen zu berechnen, die Wörter über das Lexikon bilden. Daher kann durch Berechnen der Wahrscheinlichkeiten zwischen chinesischen Schriftzeichen das Ergebnis der Wortsegmentierung gebildet werden. Natürlich können Benutzer zusätzlich zu Jiebas eigener chinesischer Vokabularbibliothek auch benutzerdefinierte Phrasen hinzufügen und so die Wortsegmentierung von Jieba näher an die Verwendung in bestimmten spezifischen Bereichen anpassen.
jieba ist eine chinesische Wortsegmentierungsbibliothek für Python. Hier erfahren Sie, wie Sie sie verwenden.
Installieren Sie die
方式1: pip install jieba 方式2: 先下载 http://pypi.python.org/pypi/jieba/ 然后解压,运行 python setup.py install
-Funktion
Wortsegmentierung
Die drei häufig verwendeten Modi von Jieba:
Exakter Modus, der versucht, den Satz möglichst genau zu schneiden, geeignet für die Textanalyse;
Vollständiger Modus, der alles schneidet Sätze im Satz Alle Wörter, die zu Wörtern geformt werden können, werden gescannt, was sehr schnell geht, aber Mehrdeutigkeiten nicht auflösen kann.
Der Suchmaschinenmodus segmentiert basierend auf dem präzisen Modus lange Wörter neu, um die Erinnerungsrate zu verbessern. geeignet für Suchmaschinen Partizip.
Sie können die Methoden jieba.cut und jieba.cut_for_search für die Wortsegmentierung verwenden. Die von beiden zurückgegebene Struktur ist ein iterierbarer Generator um jedes nach der Wortsegmentierung erhaltene Wort (Unicode) abzurufen oder direkt jieba.lcut und jieba.lcut_for_search zu verwenden, um die Liste zurückzugeben. jieba.cut 和 jieba.cut_for_search 方法进行分词,两者所返回的结构都是一个可迭代的 generator,可使用 for 循环来获得分词后得到的每一个词语(unicode),或者直接使用 jieba.lcut 以及 jieba.lcut_for_search 返回 list。
jieba.Tokenizer(dictionary=DEFAULT_DICT) :使用该方法可以自定义分词器,可以同时使用不同的词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
jieba.cut 和 jieba.lcut 可接受的参数如下:
需要分词的字符串(unicode 或 UTF-8 字符串、GBK 字符串)
cut_all:是否使用全模式,默认值为
FalseHMM:用来控制是否使用 HMM 模型,默认值为
True
jieba.cut_for_search 和 jieba.lcut_for_search 接受 2 个参数:
需要分词的字符串(unicode 或 UTF-8 字符串、GBK 字符串)
-
HMM:用来控制是否使用 HMM 模型,默认值为
Truejieba.Tokenizer(dictionary=DEFAULT_DICT): Verwenden Sie diese Methode, um den Tokenizer anzupassen und verschiedene Wörterbücher gleichzeitig zu verwenden.jieba.dtist der Standard-Wortsegmentierer, und alle globalen Wortsegmentierungsfunktionen sind Zuordnungen dieses Wortsegmentierers.
jieba.cut und jieba.lcut akzeptieren Parameter wie folgt:
String, der eine Wortsegmentierung erfordert (Unicode- oder UTF-8-String, GBK-String)
cut_all: Ob der Vollmodus verwendet werden soll, der Standardwert ist False
HMM: Wird verwendet, um zu steuern, ob das HMM-Modell verwendet werden soll, der Standardwert ist True
jieba.cut_for_search und jieba.lcut_for_search akzeptieren 2 Parameter:
String, der eine Wortsegmentierung erfordert (Unicode- oder UTF-8-String, GBK-String)HMM: Wird verwendet, um zu steuern, ob das HMM-Modell verwendet werden soll. Der Standardwert ist
True
Es ist zu beachten, dass Sie keine GBK-Zeichenfolgen verwenden sollten, da diese unvorhersehbar und falsch dekodiert werden können in UTF-8. Vergleich von drei Wortsegmentierungsmodi: # 全匹配
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=True)
print(list(seg_list)) # ['今天', '哪里', '都', '没去', '', '', '在家', '家里', '睡', '了', '一天']
# 精确匹配 默认模式
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=False)
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
# 精确匹配
seg_list = jieba.cut_for_search("今天哪里都没去,在家里睡了一天")
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
Benutzerdefiniertes WörterbuchEntwickler können ihr eigenes benutzerdefiniertes Wörterbuch angeben, um Wörter einzubeziehen, die nicht im Jieba-Wörterbuch enthalten sind. Verwendung: jieba.load_userdict(dict_path)
dict_path: ist der Pfad zur benutzerdefinierten Wörterbuchdatei
- Das Wörterbuchformat ist wie folgt:
Ein Wort belegt eine Zeile; jede Zeile ist in drei Teile unterteilt: Wort, Worthäufigkeit (kann weggelassen werden), Wortart (kann weggelassen werden) weggelassen), durch Leerzeichen getrennt und die Reihenfolge kann nicht umgekehrt werden.
Im Folgenden wird ein Beispiel zur Veranschaulichung verwendet: Benutzerdefiniertes Wörterbuch user_dict.txt:
- Universitätskurs
Deep Learning
- Im Folgenden werden die Unterschiede zwischen exakter Übereinstimmung, vollständiger Übereinstimmung und der Verwendung eines benutzerdefinierten Wörterbuchs verglichen:
import jieba test_sent = """ 数学是一门基础性的大学课程,深度学习是基于数学的,尤其是线性代数课程 """ words = jieba.cut(test_sent) print(list(words)) # ['\n', '数学', '是', '一门', '基础性', '的', '大学', '课程', ',', '深度', # '学习', '是', '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n'] words = jieba.cut(test_sent, cut_all=True) print(list(words)) # ['\n', '数学', '是', '一门', '基础', '基础性', '的', '大学', '课程', '', '', '深度', # '学习', '是', '基于', '数学', '的', '', '', '尤其', '是', '线性', '线性代数', '代数', '课程', '\n'] jieba.load_userdict("userdict.txt") words = jieba.cut(test_sent) print(list(words)) # ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是', # '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n'] jieba.add_word("尤其是") jieba.add_word("线性代数课程") words = jieba.cut(test_sent) print(list(words)) # ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是', # '基于', '数学', '的', ',', '尤其是', '线性代数课程', '\n']Von oben Wie im Beispiel zu sehen ist, besteht der Unterschied zwischen der Verwendung eines benutzerdefinierten Wörterbuchs und der Verwendung des Standardwörterbuchs. - jieba.add_word(): Wörter zum benutzerdefinierten Wörterbuch hinzufügen Schlüsselwortextraktion🎜🎜 Die Schlüsselwortextraktion kann auf dem TF-IDF-Algorithmus oder dem TextRank-Algorithmus basieren. Der TF-IDF-Algorithmus ist derselbe Algorithmus, der in Elasticsearch verwendet wird. 🎜🎜Verwenden Sie die Funktion jieba.analyse.extract_tags() zur Schlüsselwortextraktion. Die Parameter lauten wie folgt: 🎜🎜jieba.analyse.extract_tags(sentence, topK=20, withWeight=False,allowPOS=())🎜🎜🎜🎜sentence is sein Der extrahierte Text 🎜🎜🎜🎜topK soll mehrere TF/IDF-Schlüsselwörter mit der größten Gewichtung zurückgeben, der Standardwert ist 20🎜🎜🎜🎜mitWeight gibt an, ob der Schlüsselwortgewichtswert zusammen zurückgegeben werden soll, der Standardwert ist False🎜🎜 🎜🎜allowPOS only Einschließlich Wörter mit einem bestimmten Teil der Sprache, der Standardwert ist leer, d
也可以使用 jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件。
基于 TF-IDF 算法和TextRank算法的关键词抽取:
import jieba.analyse file = "sanguo.txt" topK = 12 content = open(file, 'rb').read() # 使用tf-idf算法提取关键词 tags = jieba.analyse.extract_tags(content, topK=topK) print(tags) # ['玄德', '程远志', '张角', '云长', '张飞', '黄巾', '封谞', '刘焉', '邓茂', '邹靖', '姓名', '招军'] # 使用textrank算法提取关键词 tags2 = jieba.analyse.textrank(content, topK=topK) # withWeight=True:将权重值一起返回 tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=True) print(tags) # [('玄德', 0.1038549799467099), ('程远志', 0.07787459004363208), ('张角', 0.0722532891360849), # ('云长', 0.07048801593691037), ('张飞', 0.060972692853113214), ('黄巾', 0.058227157790330185), # ('封谞', 0.0563904127495283), ('刘焉', 0.05470798376886792), ('邓茂', 0.04917692565566038), # ('邹靖', 0.04427258239705188), ('姓名', 0.04219704283997642), ('招军', 0.04182041076757075)]
上面的代码是读取文件,提取出现频率最高的前12个词。
词性标注
词性标注主要是标记文本分词后每个词的词性,使用例子如下:
import jieba
import jieba.posseg as pseg
# 默认模式
seg_list = pseg.cut("今天哪里都没去,在家里睡了一天")
for word, flag in seg_list:
print(word + " " + flag)
"""
使用 jieba 默认模式的输出结果是:
我 r
Prefix dict has been built successfully.
今天 t
吃 v
早饭 n
了 ul
"""
# paddle 模式
words = pseg.cut("我今天吃早饭了",use_paddle=True)
"""
使用 paddle 模式的输出结果是:
我 r
今天 TIME
吃 v
早饭 n
了 xc
"""paddle模式的词性对照表如下:
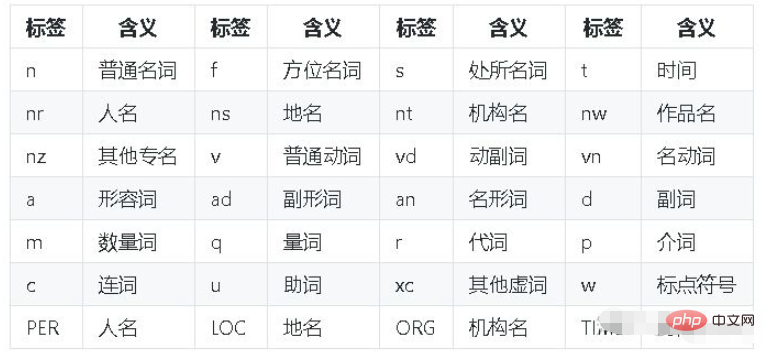
补充:Python中文分词库——jieba的用法
.使用说明
jieba分词有三种模式:精确模式、全模式和搜索引擎模式。
简单说,精确模式就是把一段文本精确的切分成若干个中文单词,若干个中文单词之间经过组合就精确的还原为之前的文本,其中不存在冗余单词。精确模式是最常用的分词模式。
进一步jieba又提供了全模式,全模式是把一段中文文本中所有可能的词语都扫描出来,可能有一段文本它可以切分成不同的模式或者有不同的角度来切分变成不同的词语,那么jieba在全模式下把这样的不同的组合都挖掘出来,所以如果用全模式来进行分词,分词的信息组合起来并不是精确的原有文本,会有很多的冗余。
而搜索引擎模式更加智能,它是在精确模式的基础上对长词进行再次切分,将长的词语变成更短的词语,进而适合搜索引擎对短词语的索引和搜索,在一些特定场合用的比较多。
jieba库提供的常用函数:
jieba.lcut(s)
精确模式,能够对一个字符串精确地返回分词结果,而分词的结果使用列表形式来组织。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家")
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 2.489 seconds.
Prefix dict has been built successfully.
['中国', '是', '一个', '伟大', '的', '国家']jieba.lcut(s,cut_all=True)
全模式,能够返回一个列表类型的分词结果,但结果存在冗余。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家",cut_all=True)
['中国', '国是', '一个', '伟大', '的', '国家']jieba.lcut_for_search(s)
搜索引擎模式,能够返回一个列表类型的分词结果,也存在冗余。例如:
>>> import jieba
>>> jieba.lcut_for_search("中华人民共和国是伟大的")
['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的']jieba.add_word(w)
向分词词库添加新词w
最重要的就是jieba.lcut(s)函数,完成精确的中文分词。
Das obige ist der detaillierte Inhalt vonWie verwende ich die Jieba-Bibliothek in Python?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!