
Heim >Java >javaLernprogramm >So lösen Sie das Multithread-Parallelitätsproblem von Javas HashMap
So lösen Sie das Multithread-Parallelitätsproblem von Javas HashMap

- PHPznach vorne
- 2023-05-09 14:28:171658Durchsuche
Symptome von Parallelitätsproblemen
Multithread-Put kann zu einer Endlosschleife von get führen
In der Vergangenheit verwendete unser Java-Code aus bestimmten Gründen HashMap, aber das damalige Programm war Single-Threaded und alles war in Ordnung. Später hatte unser Programm Leistungsprobleme, sodass wir auf Multithreading umsteigen mussten. Nachdem wir Multithreading betrieben hatten, stellten wir fest, dass das Programm häufig 100 % der CPU belegte Alle Programme hängen in HashMap. Die Methode .get() wurde installiert und das Problem verschwand nach dem Neustart des Programms. Aber es wird nach einer Weile wieder kommen. Darüber hinaus kann es schwierig sein, dieses Problem in einer Testumgebung zu reproduzieren.
Wenn wir uns einfach unseren eigenen Code ansehen, wissen wir, dass HashMap von mehreren Threads betrieben wird. In der Java-Dokumentation heißt es, dass HashMap nicht threadsicher ist und ConcurrentHashMap verwendet werden sollte. Aber hier können wir die Gründe untersuchen. Der einfache Code lautet wie folgt:
package com.king.hashmap;
import java.util.HashMap;
public class TestLock {
private HashMap map = new HashMap();
public TestLock() {
Thread t1 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t1 over" );
}
};
Thread t2 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t2 over" );
}
};
Thread t3 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t3 over" );
}
};
Thread t4 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t4 over" );
}
};
Thread t5 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.put( new Integer(i), i);
}
System.out.println( "t5 over" );
}
};
Thread t6 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t6 over" );
}
};
Thread t7 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t7 over" );
}
};
Thread t8 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t8 over" );
}
};
Thread t9 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t9 over" );
}
};
Thread t10 = new Thread() {
public void run() {
for ( int i = 0 ; i < 50000 ; i++) {
map.get( new Integer(i));
}
System.out.println( "t10 over" );
}
};
t1.start();
t2.start();
t3.start();
t4.start();
t5.start();
t6.start();
t7.start();
t8.start();
t9.start();
t10.start();
}
public static void main(String[] args) {
new TestLock();
}
}soll 10 Threads starten und kontinuierlich Inhalte in eine nicht-threadsichere HashMap einfügen. Der Schlüssel und der Wert sind beide Ganzzahlen, die von 0 ansteigen (Dieser Satz Der Inhalt war nicht sehr gut, was mich später daran hinderte, das Problem zu analysieren.) Beim Ausführen gleichzeitiger Schreibvorgänge auf HashMap dachte ich, dass nur fehlerhafte Daten erzeugt würden. Wenn ich dieses Programm jedoch wiederholt ausführe, bleiben die Threads t1 und t2 hängen. In den meisten Fällen bleibt ein Thread hängen und der andere wird erfolgreich beendet. , gelegentlich hängen alle 10 Threads auf.
Die Ursache dieser Endlosschleife liegt in der Operation einer ungeschützten gemeinsam genutzten Variablen – einer „HashMap“-Datenstruktur. Nach dem Hinzufügen von „synchronisiert“ zu allen Betriebsmethoden normalisierte sich alles wieder. Ist das ein JVM-Fehler? Nein, dieses Phänomen wurde schon vor langer Zeit gemeldet. Sun-Ingenieure glauben nicht, dass dies ein Fehler ist, schlagen jedoch vor, in einem solchen Szenario „ConcurrentHashMap“ zu verwenden. Eine übermäßige CPU-Auslastung ist im Allgemeinen auf eine Endlosschleife zurückzuführen, die dazu führt, dass einige Threads weiter ausgeführt werden und CPU-Zeit beanspruchen. Die Ursache des Problems liegt darin, dass HashMap nicht threadsicher ist. Wenn mehrere Threads eingegeben werden, führt dies zu einer Endlosschleife einer bestimmten Schlüsselwertliste, und das Problem tritt auf.
Wenn ein anderer Thread den Schlüssel dieser Endlosschleife der Eintragsliste erhält, wird dieser Abruf immer ausgeführt. Das Endergebnis sind immer mehr Threads in einer Endlosschleife, was schließlich zum Absturz des Servers führt. Wir gehen im Allgemeinen davon aus, dass eine HashMap den vorherigen Wert überschreibt, wenn sie wiederholt einen bestimmten Wert einfügt. Beim Multithread-Zugriff kann jedoch aufgrund des internen Implementierungsmechanismus (in einer Multithread-Umgebung und ohne Synchronisierung) ein Put-Vorgang auf derselben HashMap dazu führen, dass zwei oder mehr Threads gleichzeitig einen Rehash-Vorgang ausführen, was dazu führen kann Wenn die Tabelle mit den zirkulären Schlüsseln angezeigt wird, kann es zu Sicherheitsproblemen kommen, sobald der Thread nicht beendet werden kann und weiterhin die CPU belegt, was zu einer hohen CPU-Auslastung führt.
Verwenden Sie das jstack-Tool, um die Stack-Informationen des Servers mit dem Problem zu sichern. Wenn es eine Endlosschleife gibt, suchen Sie zuerst nach dem Thread von RUNNABLE und finden Sie den Problemcode wie folgt:
java.lang.Thread.State:RUNNABLEat java.util.HashMap.get(HashMap.java:303)Hinweisat com.sohu.twap .service.logic.TransformTweeter.doTransformTweetT5(TransformTweeter.java:183)
Insgesamt 23 Mal aufgetaucht.
java.lang.Thread.State:RUNNABLE
bei java.util.HashMap.put(HashMap.java:374)
bei com.sohu.twap.service.logic.TransformTweeter.transformT5(TransformTweeter.java:816)
Total 3 Mal aufgetaucht.
: Eine unsachgemäße Verwendung von HashMap führt eher zu einer Endlosschleife als zu einem Deadlock. Multithread-Put kann zum Verlust von Elementen führen
Das Hauptproblem liegt im neuen Eintrag (Hash, Schlüssel, Wert, e) der addEntry-Methode. Wenn beide Threads e gleichzeitig erhalten, wird ihr nächstes Element erhalten sein e , dann ist beim Zuweisen von Werten zu Tabellenelementen eines erfolgreich und das andere geht verloren.
Nach dem Einfügen des Nicht-Null-Elements ist das erhaltene Ergebnis null
Der Code in der Übertragungsmethode lautet wie folgt:
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for ( int j = 0 ; j < src.length; j++) {
Entry e = src[j];
if (e != null ) {
src[j] = null ;
do {
Entry next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );
}
}
}In dieser Methode weisen Sie src das alte Array zu, durchlaufen src und wenn das Element von src nicht null ist, wird das Element in src auf null gesetzt, was bedeutet, dass das Element im alten Array auf null gesetzt ist. Dies ist dieser Satz:
if (e != null ) {
src[j] = null ;Wenn es zu diesem Zeitpunkt eine Get-Methode gibt, um auf diesen Schlüssel zuzugreifen , erhält es weiterhin das alte Array, kann aber natürlich nicht den entsprechenden Wert abrufen.
Zusammenfassung: Wenn HashMap nicht synchronisiert ist, treten in gleichzeitigen Programmen viele subtile Probleme auf, und es ist schwierig, die Ursache an der Oberfläche zu finden. Wenn bei der Verwendung von HashMap ein kontraintuitives Phänomen auftritt, kann dies daher auf Parallelität zurückzuführen sein.HashMap-Datenstruktur
Ich muss kurz auf die klassische Datenstruktur HashMap eingehen.
HashMap verwendet normalerweise ein Zeiger-Array (angenommen, es handelt sich um Tabelle []), um alle Schlüssel zu verteilen. Wenn ein Schlüssel hinzugefügt wird, wird der Index i des Arrays über den Schlüssel durch den Hash-Algorithmus berechnet und dann in In eingefügt Tabelle [i]: Wenn zwei verschiedene Schlüssel für dasselbe i gezählt werden, spricht man von einem Konflikt, auch Kollision genannt. Dadurch wird eine verknüpfte Liste in Tabelle [i] gebildet.
Wir wissen, dass es sehr häufig zu Kollisionen kommt, wenn die Größe von table[] sehr klein ist, z. B. nur 2, und wenn 10 Schlüssel eingegeben werden sollen, sodass ein O(1)-Suchalgorithmus zu einer Durchquerung einer verknüpften Liste wird . Die Leistung wird zu O(n), was ein Fehler der Hash-Tabelle ist.
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的元素都需要被重算一遍。这叫rehash,这个成本相当的大。
HashMap的rehash源代码
下面,我们来看一下Java的HashMap的源代码。Put一个Key,Value对到Hash表中:
public V put(K key, V value)
{
......
//算Hash值
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//如果该key已被插入,则替换掉旧的value (链接操作)
for (Entry<K,V> e = table[i]; e != null ; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess( this );
return oldValue;
}
}
modCount++;
//该key不存在,需要增加一个结点
addEntry(hash, key, value, i);
return null ;
}检查容量是否超标:
void addEntry( int hash, K key, V value, int bucketIndex)
{
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//查看当前的size是否超过了我们设定的阈值threshold,如果超过,需要resize
if (size++ >= threshold)
resize( 2 * table.length);
}新建一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
void resize( int newCapacity)
{
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
......
//创建一个新的Hash Table
Entry[] newTable = new Entry[newCapacity];
//将Old Hash Table上的数据迁移到New Hash Table上
transfer(newTable);
table = newTable;
threshold = ( int )(newCapacity * loadFactor);
}迁移的源代码,注意高亮处:
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for ( int j = 0 ; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null ) {
src[j] = null ;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );
}
}
}好了,这个代码算是比较正常的。而且没有什么问题。
正常的ReHash过程
画了个图做了个演示。
我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table1这里了。
接下来的三个步骤是Hash表 resize成4,然后所有的 重新rehash的过程。
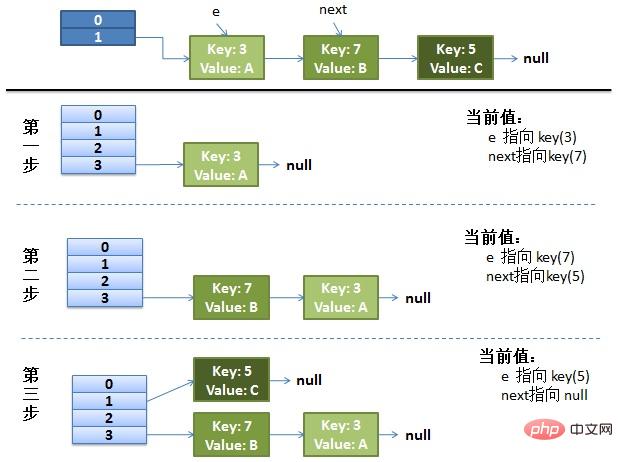
并发的Rehash过程
(1)假设我们有两个线程。我用红色和浅蓝色标注了一下。我们再回头看一下我们的 transfer代码中的这个细节:
do {
Entry<K,V> next = e.next; // <--假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null );而我们的线程二执行完成了。于是我们有下面的这个样子。
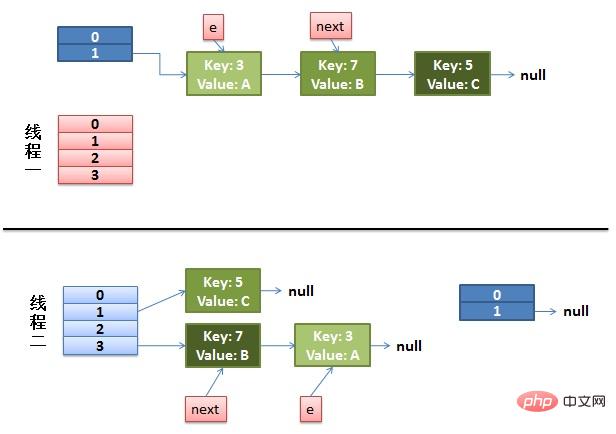
注意:因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
(2)线程一被调度回来执行。
先是执行 newTalbe[i] = e。
然后是e = next,导致了e指向了key(7)。
而下一次循环的next = e.next导致了next指向了key(3)。
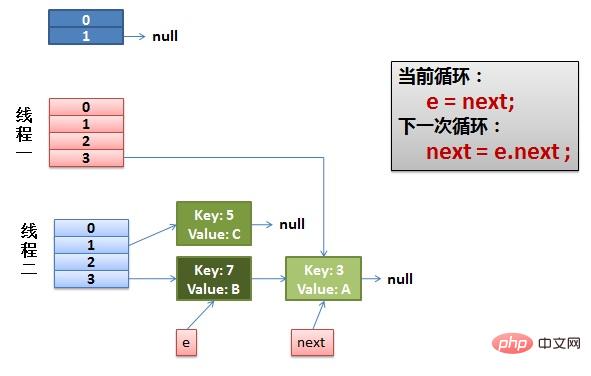
(3)一切安好。 线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
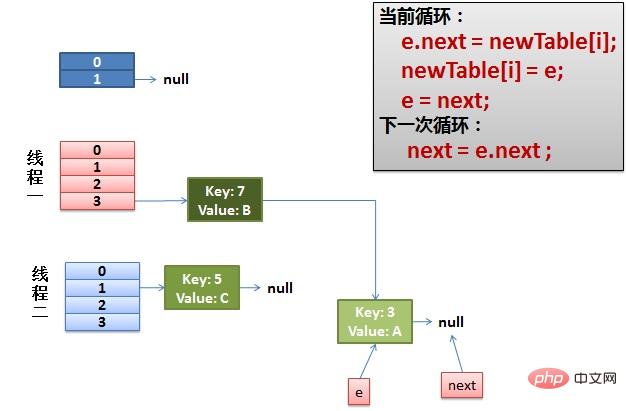
(4)环形链接出现。 e.next = newTable[i] 导致 key(3).next 指向了 key(7)。注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
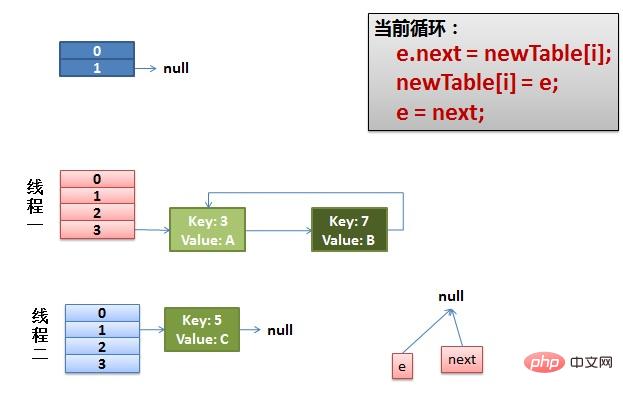
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
三种解决方案
Hashtable替换HashMap
Hashtable 是同步的,但由迭代器返回的 Iterator 和由所有 Hashtable 的“collection 视图方法”返回的 Collection 的 listIterator 方法都是快速失败的:在创建 Iterator 之后,如果从结构上对 Hashtable 进行修改,除非通过 Iterator 自身的移除或添加方法,否则在任何时间以任何方式对其进行修改,Iterator 都将抛出 ConcurrentModificationException。因此,面对并发的修改,Iterator 很快就会完全失败,而不冒在将来某个不确定的时间发生任意不确定行为的风险。由 Hashtable 的键和值方法返回的 Enumeration 不是快速失败的。
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败迭代器会尽最大努力抛出 ConcurrentModificationException。因此,为提高这类迭代器的正确性而编写一个依赖于此异常的程序是错误做法:迭代器的快速失败行为应该仅用于检测程序错误。
Collections.synchronizedMap将HashMap包装起来
返回由指定映射支持的同步(线程安全的)映射。为了保证按顺序访问,必须通过返回的映射完成对底层映射的所有访问。在返回的映射或其任意 collection 视图上进行迭代时,强制用户手工在返回的映射上进行同步:
Map m = Collections.synchronizedMap( new HashMap());
...
Set s = m.keySet(); // Needn't be in synchronized block
...
synchronized (m) { // Synchronizing on m, not s!
Iterator i = s.iterator(); // Must be in synchronized block
while (i.hasNext())
foo(i.next());
}不遵从此建议将导致无法确定的行为。如果指定映射是可序列化的,则返回的映射也将是可序列化的。
ConcurrentHashMap ersetzt HashMap
Eine Hash-Tabelle, die vollständige Parallelität beim Abruf und die gewünschte einstellbare Parallelität bei Aktualisierungen unterstützt. Diese Klasse folgt der gleichen Funktionsspezifikation wie Hashtable und enthält Methodenversionen, die jeder Methode von Hashtable entsprechen. Obwohl jedoch alle Vorgänge threadsicher sind, müssen Abrufvorgänge nicht gesperrt werden, und das Sperren der gesamten Tabelle auf eine Weise, die jeglichen Zugriff verhindert, wird nicht unterstützt. Diese Klasse kann abhängig von ihrer Thread-Sicherheit und unabhängig von ihren Synchronisierungsdetails vollständig programmgesteuert mit einer Hashtable interoperabel sein. Abrufvorgänge (einschließlich Get) blockieren im Allgemeinen nicht und können sich daher mit Aktualisierungsvorgängen (einschließlich Put und Remove) überschneiden. Der Abruf wirkt sich auf die Ergebnisse des zuletzt abgeschlossenen Aktualisierungsvorgangs aus. Bei einigen Aggregatoperationen wie putAll und clear wirkt sich der gleichzeitige Abruf möglicherweise nur auf das Einfügen und Entfernen bestimmter Elemente aus. Ebenso geben Iteratoren und Aufzählungen Elemente zurück, die den Zustand der Hash-Tabelle zu einem bestimmten Zeitpunkt beeinflusst haben, entweder zum Zeitpunkt der Erstellung des Iterators/der Aufzählung oder seitdem. Sie lösen keine ConcurrentModificationException aus. Iteratoren sind jedoch so konzipiert, dass sie jeweils nur von einem Thread verwendet werden können.
Das obige ist der detaillierte Inhalt vonSo lösen Sie das Multithread-Parallelitätsproblem von Javas HashMap. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!