
Heim >Backend-Entwicklung >Python-Tutorial >Wie verarbeite ich Excel-Daten mit der Pandas-Bibliothek von Python?
Wie verarbeite ich Excel-Daten mit der Pandas-Bibliothek von Python?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-08 21:49:183658Durchsuche
1. XLSX-Tabelle lesen: pd.read_excel()
Der ursprüngliche Inhalt ist wie folgt:
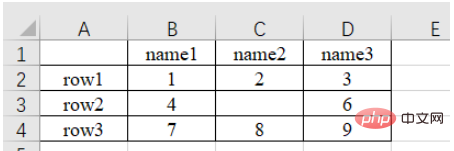
#🎜 🎜#a) Lesen Sie die Daten des n-ten Blattes (Unterblatt, Sie können Unterblätter in der unteren linken Ecke anzeigen, hinzufügen oder löschen)
import pandas as pd # 每次都需要修改的路径 path = "test.xlsx" # sheet_name默认为0,即读取第一个sheet的数据 sheet = pd.read_excel(path, sheet_name=0) print(sheet) """ Unnamed: 0 name1 name2 name3 0 row1 1 2.0 3 1 row2 4 NaN 6 2 row3 7 8.0 9 """Sie können es bemerken Wenn die obere linke Ecke des Originalformulars nicht mit Inhalt ausgefüllt ist, lautet das Leseergebnis „
Unbenannt: 0“. Dies liegt daran, dass die read_excel-Funktion standardmäßig die erste Zeile des Formulars verwendet Tabelle als Spaltenindexname . Darüber hinaus beginnt die Nummerierung für Zeilenindexnamen standardmäßig bei der zweiten Zeile (da die erste Standardzeile der Spaltenindexname ist und es sich bei der ersten Standardzeile also nicht um Daten handelt, beginnt die Nummerierung automatisch bei 0). folgt.
sheet = pd.read_excel(path) # 查看列索引名,返回列表形式 print(sheet.columns.values) # 查看行索引名,默认从第二行开始编号,如果不特意指定,则自动从0开始编号,返回列表形式 print(sheet.index.values) """ ['Unnamed: 0' 'name1' 'name2' 'name3'] [0 1 2] """
b) Der Spaltenindexname kann auch wie folgt angepasst werden:
sheet = pd.read_excel(path, names=['col1', 'col2', 'col3', 'col4']) print(sheet) # 查看列索引名,返回列表形式 print(sheet.columns.values) """ col1 col2 col3 col4 0 row1 1 2.0 3 1 row2 4 NaN 6 2 row3 7 8.0 9 ['col1' 'col2' 'col3' 'col4'] """
c) Die n-te Spalte kann auch angegeben werden Der Zeilenindexname ist , wie folgt:
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
"""
d) Überspringen Sie die Daten der n-ten Zeile beim Lesen von
# 跳过第2行的数据(第一行索引为0) sheet = pd.read_excel(path, skiprows=[1]) print(sheet) """ Unnamed: 0 name1 name2 name3 0 row2 4 NaN 6 1 row3 7 8.0 9 """# 🎜🎜#2 , Ermitteln Sie die Datengröße der Tabelle: shape
path = "test.xlsx"
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
print('==========================')
print('shape of sheet:', sheet.shape)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
==========================
shape of sheet: (3, 3)
"""3. Indexdatenmethode: [ ] / loc[] / iloc[]
#🎜🎜 #1. Fügen Sie den Index in eckigen Klammern direkt hinzu Verwenden Sie eckige Klammern, um die Indexnummer
[index] hinzuzufügen, um den Wert der spezifischen Position dieser Spalte zu indizieren. Hier wird die Spalte namens name1 indiziert und dann werden die Daten in Zeile 1 der Spalte (Index ist 1) gedruckt: 4, wie folgt: sheet = pd.read_excel(path)
# 读取列名为 name1 的列数据
col = sheet['name1']
print(col)
# 打印该列第二个数据
print(col[1]) # 4
"""
0 1
1 4
2 7
Name: name1, dtype: int64
4
"""
verwendet sheet.iloc[ ] Index Die eckigen Klammern sind die ganzzahligen Positionsnummern der Zeilen und Spalten (mit Ausnahme der Spalte). als Zeilenindex und Spaltenindex. Nach welcher Zeile beginnt die Nummerierung bei 0).
a) sheet.iloc[1, 2]: Extrahieren Sie Zeile 2, Spalte 3
Daten. Der erste ist der Zeilenindex, der zweite ist der Spaltenindexb) sheet.iloc[0: 2]
: Extrahieren Sie die ersten beiden Zeilen von #🎜 🎜#datac) sheet.iloc[0:2, 0:2]
durch Sharding#🎜 🎜 # Die ersten beiden Spalten von Daten# 指定第一列数据为行索引
sheet = pd.read_excel(path, index_col=0)
# 读取第2行(row2)的第3列(6)数据
# 第一个是行索引,第二个是列索引
data = sheet.iloc[1, 2]
print(data) # 6
print('================================')
# 通过分片的方式提取 前两行 数据
data_slice = sheet.iloc[0:2]
print(data_slice)
print('================================')
# 通过分片的方式提取 前两行 的 前两列 数据
data_slice = sheet.iloc[0:2, 0:2]
print(data_slice)
"""
6
================================
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
================================
name1 name2
row1 1 2.0
row2 4 NaN
"""
#🎜 🎜#Verwenden Sie # 🎜🎜#sheet.loc[ ] Index, die eckigen Klammern sind die Namenszeichenfolge der Zeile . Die spezifische Verwendung ist die gleiche wie bei iloc , außer dass der ganzzahlige Index von iloc durch den Namensindex der Zeile und Spalte ersetzt wird. Diese Indizierungsmethode ist intuitiver zu verwenden.
Hinweis :
iloc[1: 2] enthält nicht 2, sondern loc['row1': ' row2 '] enthält 'row2'. # 指定第一列数据为行索引
sheet = pd.read_excel(path, index_col=0)
# 读取第2行(row2)的第3列(6)数据
# 第一个是行索引,第二个是列索引
data = sheet.loc['row2', 'name3']
print(data) # 1
print('================================')
# 通过分片的方式提取 前两行 数据
data_slice = sheet.loc['row1': 'row2']
print(data_slice)
print('================================')
# 通过分片的方式提取 前两行 的 前两列 数据
data_slice1 = sheet.loc['row1': 'row2', 'name1': 'name2']
print(data_slice1)
"""
6
================================
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
================================
name1 name2
row1 1 2.0
row2 4 NaN
"""4. Bestimmen Sie, ob die Daten leer sind: np.isnan() / pd.isnull()1. Verwenden Sie isnan()#🎜 von
Die Methode isnull() der Pandas-Bibliothek bestimmt, ob sie gleich nan ist.
sheet = pd.read_excel(path) # 读取列名为 name1 的列数据 col = sheet['name2'] print(np.isnan(col[1])) # True print(pd.isnull(col[1])) # True """ True True """2. Verwenden Sie str(), um in einen String zu konvertieren und festzustellen, ob er gleich 'nan' ist.
sheet = pd.read_excel(path)
# 读取列名为 name1 的列数据
col = sheet['name2']
print(col)
# 打印该列第二个数据
if str(col[1]) == 'nan':
print('col[1] is nan')
"""
0 2.0
1 NaN
2 8.0
Name: name2, dtype: float64
col[1] is nan
"""
5. Finden Sie Daten, die die Bedingungen erfüllen Lassen Sie uns den folgenden Code verstehen
# 提取name1 == 1 的行
mask = (sheet['name1'] == 1)
x = sheet.loc[mask]
print(x)
"""
name1 name2 name3
row1 1 2.0 3
"""6. Ändern Sie den Elementwert: replace()# 🎜 🎜#sheet['name2'].replace(2, 100, inplace=True) : Element 2 von Spalte name2 in Element 100 ändern und an Ort und Stelle operieren. sheet['name2'].replace(2, 100, inplace=True)
print(sheet)
"""
name1 name2 name3
row1 1 100.0 3
row2 4 NaN 6
row3 7 8.0 9
"""sheet['name2'].replace(np.nan, 100, inplace=True) : Ändern Sie das leere Element (nan) der Spalte „name2“ in das Element 100, in situ arbeiten.
import numpy as np
sheet['name2'].replace(np.nan, 100, inplace=True)
print(sheet)
print(type(sheet.loc['row2', 'name2']))
"""
name1 name2 name3
row1 1 2.0 3
row2 4 100.0 6
row3 7 8.0 9
"""7. Daten hinzufügen: [ ]
Fügen Sie eine Spalte direkt in eckigen Klammern hinzu [Name zum Hinzufügen].sheet['name_add'] = [55, 66, 77]: Fügen Sie eine Spalte namens name_add mit einem Wert von [55, 66, 77 hinzu ]
path = "test.xlsx"
# 指定第一列为行索引
sheet = pd.read_excel(path, index_col=0)
print(sheet)
print('====================================')
# 添加名为 name_add 的列,值为[55, 66, 77]
sheet['name_add'] = [55, 66, 77]
print(sheet)
"""
name1 name2 name3
row1 1 2.0 3
row2 4 NaN 6
row3 7 8.0 9
====================================
name1 name2 name3 name_add
row1 1 2.0 3 55
row2 4 NaN 6 66
row3 7 8.0 9 77
"""8. Daten löschen: del() / drop()
a) del(sheet['name3']): Verwenden Sie die Del-Methode, um zu löschen Zeile: Wenn Sie eine Spalte löschen, ist die entsprechende Achse = 1.
Wenn der Inplace-Parameter „True“ ist, wird der Parameter nicht zurückgegeben und direkt in den Originaldaten gelöscht. Wenn der Inplace-Parameter „False“ (Standard) ist, das Original Daten werden nicht geändert, sondern geben die geänderten Daten zurück
sheet = pd.read_excel(path, index_col=0)
# 使用 del 方法删除 'name3' 的列
del(sheet['name3'])
print(sheet)
"""
name1 name2
row1 1 2.0
row2 4 NaN
row3 7 8.0
"""c)sheet.drop(labels=['name1', 'name2'], axis=1)
#🎜 🎜#Verwenden Sie den Parameter label=[ ], um mehrere Zeilen oder Spalten zu löschensheet.drop('row1', axis=0, inplace=True)
print(sheet)
"""
name1 name2 name3
row2 4 NaN 6
row3 7 8.0 9
"""
9. In Excel-Datei speichern: to_excel()#🎜🎜 #1. Pandas einfügen Die formatierten Daten werden als .xlsx-Datei gespeichert Datei als .xlsx-Datei.
Nachdem Sie beispielsweise nan in der Originaltabelle auf 100 geändert haben, speichern Sie die Datei: # 删除多列,默认 inplace 参数位 False,即会返回结果
print(sheet.drop(labels=['name1', 'name2'], axis=1))
"""
name3
row1 3
row2 6
row3 9
"""Öffnen Sie test2.xlsx und das Ergebnis ist wie folgt: # 🎜🎜#
Das obige ist der detaillierte Inhalt vonWie verarbeite ich Excel-Daten mit der Pandas-Bibliothek von Python?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!