
Heim >Backend-Entwicklung >Python-Tutorial >Wie implementiert man Multiprocessing, um die Kommunikation zwischen Prozessen in Python zu implementieren?
Wie implementiert man Multiprocessing, um die Kommunikation zwischen Prozessen in Python zu implementieren?

- 王林nach vorne
- 2023-05-08 21:31:062332Durchsuche
1. Warum müssen wir die Kommunikation zwischen Prozessen beherrschen? Die Multithread-Code-Effizienz von Python wird durch GIL eingeschränkt und kann durch Multi-Core-CPUs nicht beschleunigt werden Nutzen Sie die Vorteile der Multi-CPU-Beschleunigung. Verbessert die Leistung des Programms erheblich
, aber die Kommunikation zwischen Prozessen ist ein Problem, das berücksichtigt werden muss. Ein Prozess unterscheidet sich von einem Thread. Ein Prozess verfügt über einen eigenen unabhängigen Speicherbereich und kann keine globalen Variablen zum Übertragen von Daten zwischen Prozessen verwenden.
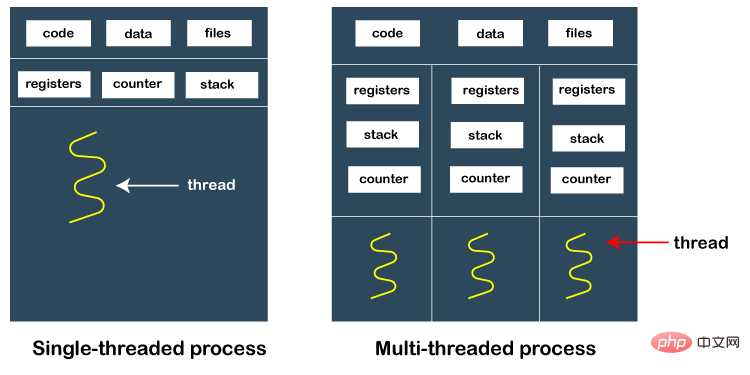 Bei tatsächlichen Projektanforderungen müssen häufig große Datenmengen wie Bilder, große Objekte usw. zwischen Prozessen übertragen werden Durch Dateiserialisierung oder Netzwerkschnittstelle ist es schwierig, die Echtzeitanforderungen zu erfüllen, und es werden die Nachrichtenwarteschlangenpakete von Drittanbietern wie Redis, Kaffka und RabbitMQ verwendet, was das System erneut verkompliziert.
Bei tatsächlichen Projektanforderungen müssen häufig große Datenmengen wie Bilder, große Objekte usw. zwischen Prozessen übertragen werden Durch Dateiserialisierung oder Netzwerkschnittstelle ist es schwierig, die Echtzeitanforderungen zu erfüllen, und es werden die Nachrichtenwarteschlangenpakete von Drittanbietern wie Redis, Kaffka und RabbitMQ verwendet, was das System erneut verkompliziert.
Das Python-Multiprocessing-Modul selbst bietet verschiedene sehr effiziente Kommunikationsmethoden zwischen Prozessen wie Nachrichtenmechanismus, Synchronisierungsmechanismus und gemeinsam genutzten Speicher.
Das Verstehen und Beherrschen der Verwendung verschiedener Methoden der Python-Interprozesskommunikation sowie der Sicherheitsmechanismen kann dazu beitragen, die Leistung der Programmausführung erheblich zu verbessern. 2. Einführung in verschiedene Kommunikationsmethoden zwischen Prozessen
Die wichtigsten Methoden der Kommunikation zwischen Prozessen werden wie folgt zusammengefasst
Über die Speichersicherheit der Kommunikation zwischen Prozessen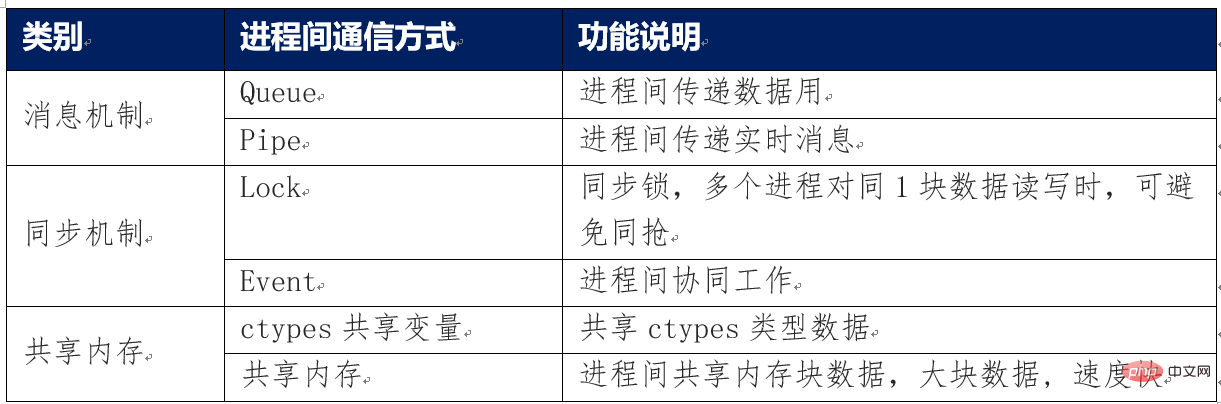
Die vom Multiprocessing-Modul bereitgestellten Warteschlangen-, Pipe-, Sperr- und Ereignisobjekte verfügen alle über implementierte Sicherheitsmechanismen für die Kommunikation zwischen Prozessen. Wenn Sie Shared Memory zur Kommunikation verwenden, müssen Sie diese Shared-Memory-Variablen selbst im Code verfolgen und zerstören, da sie sonst möglicherweise durcheinander geraten oder nicht normal zerstört werden. Verursacht eine Systemanomalie. Sofern sich der Entwickler nicht über die Nutzungsmerkmale des gemeinsam genutzten Speichers im Klaren ist, wird nicht empfohlen, diesen gemeinsam genutzten Speicher direkt zu verwenden, sondern den gemeinsam genutzten Speicher über den Manager-Manager zu verwenden.
Memory Manager Manager
3. Nachrichtenmechanismus-Kommunikation
1) Die Pipe-Kommunikationsmethode
ähnelt dem einfachen Socket-Kanal in 1, beide Enden können Nachrichten senden und empfangen.
Pipe-Objektkonstruktionsmethode:parent_conn, child_conn = Pipe(duplex=True/False)
Parameterbeschreibungduplex=True, die Pipeline ist bidirektionale Kommunikation
duplex=Falsch, die Pipeline ist unidirektionale Kommunikation, nur child_conn kann Nachrichten senden, parent_conn kann nur erhalten. 🔜 implementiert den Sperrsicherheitsmechanismus.
- Das Warteschlangenmodul bietet insgesamt 3 Arten von Warteschlangen.
from multiprocessing import Process, Pipe
def myfunction(conn):
conn.send(['hi!! I am Python'])
conn.close()
if __name__ == '__main__':
parent_conn, child_conn = Pipe()
p = Process(target=myfunction, args=(child_conn,))
p.start()
print (parent_conn.recv() )
p.join()
(2) LIFO-Warteschlange, Last In First Out, eigentlich ein Stapelclass queue.Queue(maxsize=0)(3) Bei der Prioritätswarteschlange wird der Eintragswert mit der niedrigsten Priorität zuerst in die Warteschlange gestellt
class queue.LifoQueue(maxsize=0)
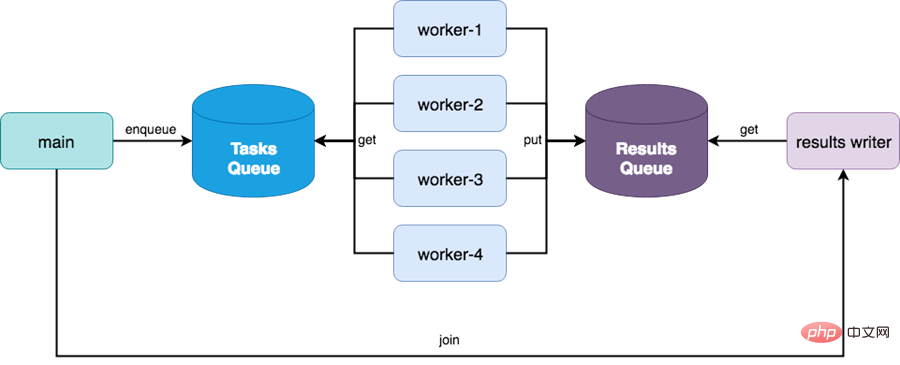 Hauptmethode der Multiprocessing.Queue-Klasse:
Hauptmethode der Multiprocessing.Queue-Klasse: methodDescription
queue.qsize()
| queue.full() | |
|---|---|
| queue.put(item) | Schreiben Sie Daten in die Warteschlange |
| queue .get() | Daten aus der Warteschlange werfen, |
| queue.put_nowait(item), queue.get_nowait() | Keine Wartezeit zum Schreiben oder Werfen |
|
说明:
Queue模块的其它队列类: (2) JoinableQueue子类
producer – consumer 场景,使用Queue的示例 import multiprocessing
def producer(numbers, q):
for x in numbers:
if x % 2 == 0:
if q.full():
print("queue is full")
break
q.put(x)
print(f"put {x} in queue by producer")
return None
def consumer(q):
while not q.empty():
print(f"take data {q.get()} from queue by consumer")
return None
if __name__ == "__main__":
# 设置1个queue对象,最大长度为5
qu = multiprocessing.Queue(maxsize=5,)
# 创建producer子进程,把queue做为其中1个参数传给它,该进程负责写
p5 = multiprocessing.Process(
name="producer-1",
target=producer,
args=([random.randint(1, 100) for i in range(0, 10)], qu)
)
p5.start()
p5.join()
#创建consumer子进程,把queue做为1个参数传给它,该进程中队列中读
p6 = multiprocessing.Process(
name="consumer-1",
target=consumer,
args=(qu,)
)
p6.start()
p6.join()
print(qu.qsize())4、同步机制通信(1) 进程间同步锁 – LockMultiprocessing也提供了与threading 类似的同步锁机制,确保某个时刻只有1个子进程可以访问某个资源或执行某项任务, 以避免同抢。 例如:多个子进程同时访问数据库表时,如果没有同步锁,用户A修改1条数据后,还未提交,此时,用户B也进行了修改,可以预见,用户A提交的将是B个修改的数据。 添加了同步锁,可以确保同时只有1个子进程能够进行写入数据库与提交操作。 如下面的示例,同时只有1个进程可以执行打印操作。 from multiprocessing import Process, Lock
def f(l, i):
l.acquire()
try:
print('hello world', i)
finally:
l.release()
if __name__ == '__main__':
lock = Lock()
for num in range(10):
Process(target=f, args=(lock, num)).start()(2) 子进程间协调机制 – EventEvent 机制的工作原理: 1个event 对象实例管理着1个 flag标记, 可以用set()方法将其置为true, 用clear()方法将其置为false, 使用wait()将阻塞当前子进程,直至flag被置为true. Event object的使用方法: 主要方法:
验证进程间通信 – Event import multiprocessing
import time
import random
def joo_a(q, ev):
print("subprocess joo_a start")
if not ev.is_set():
ev.wait()
q.put(random.randint(1, 100))
print("subprocess joo_a ended")
def joo_b(q, ev):
print("subprocess joo_b start")
ev.clear()
time.sleep(2)
q.put(random.randint(200, 300))
ev.set()
print("subprocess joo_b ended")
def main_event():
qu = multiprocessing.Queue()
ev = multiprocessing.Event()
sub_a = multiprocessing.Process(target=joo_a, args=(qu, ev))
sub_b = multiprocessing.Process(target=joo_b, args=(qu, ev,))
sub_a.start()
sub_b.start()
# ev.set()
sub_a.join()
sub_b.join()
while not qu.empty():
print(qu.get())
if __name__ == "__main__":
main_event()5、共享内存方式通信(1) 共享变量子进程之间共存内存变量,要用 multiprocessing.Value(), Array() 来定义变量。 实际上是ctypes 类型,由multiprocessing.sharedctypes模块提供相关功能 注意 使用 share memory 要考虑同抢等问题,释放等问题,需要手工实现。因此在使用共享变量时,建议使用Manager管程来管理这些共享变量。 def func(num):
num.value=10.78 #子进程改变数值的值,主进程跟着改变
if __name__=="__main__":
num = multiprocessing.Value("d", 10.0)
# d表示数值,主进程与子进程可共享这个变量。
p=multiprocessing.Process(target=func,args=(num,))
p.start()
p.join()
print(num.value)进程之间共享数据(数组型): import multiprocessing
def func(num):
num[2]=9999 #子进程改变数组,主进程跟着改变
if __name__=="__main__":
num=multiprocessing.Array("i",[1,2,3,4,5])
p=multiprocessing.Process(target=func,args=(num,))
p.start()
p.join()
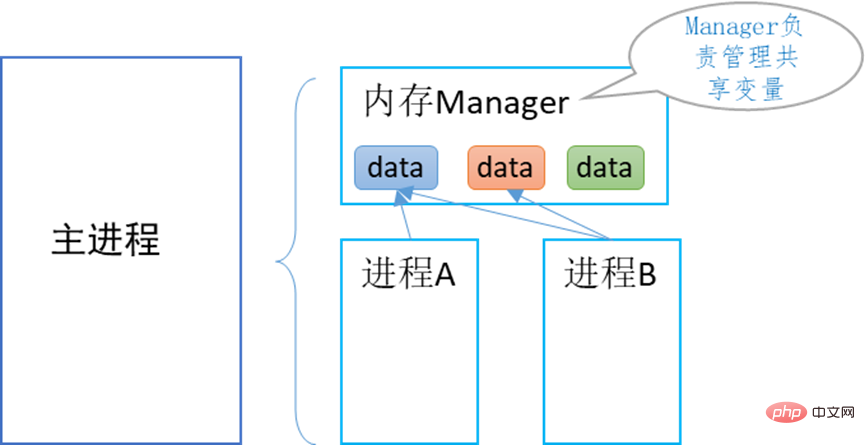
print(num[:])(2) 共享内存 Shared_memory如果进程间需要共享对象数据,或共享内容,数据较大,multiprocessing 提供了SharedMemory类来实现进程间实时通信,不需要通过发消息,读写磁盘文件来实现,速度更快。 创建共享内存区: multiprocessing.shared_memory.SharedMemory(name=none, create=False, size=0) 方法: 示例: >>> from multiprocessing import shared_memory >>> shm_a = shared_memory.SharedMemory(create=True, size=10) >>> type(shm_a.buf) <class 'memoryview'> >>> buffer = shm_a.buf >>> len(buffer) 10 >>> buffer[:4] = bytearray([22, 33, 44, 55]) # Modify multiple at once >>> buffer[4] = 100 # Modify single byte at a time >>> # Attach to an existing shared memory block >>> shm_b = shared_memory.SharedMemory(shm_a.name) >>> import array >>> array.array('b', shm_b.buf[:5]) # Copy the data into a new array.array array('b', [22, 33, 44, 55, 100]) >>> shm_b.buf[:5] = b'howdy' # Modify via shm_b using bytes >>> bytes(shm_a.buf[:5]) # Access via shm_a b'howdy' >>> shm_b.close() # Close each SharedMemory instance >>> shm_a.close() >>> shm_a.unlink() # Call unlink only once to release the shared memory 3) ShareableList 共享列表sharedMemory类还提供了1个共享列表类型,这样就更方便了,进程间可以直接共享python强大的列表 from multiprocessing import shared_memory >>> a = shared_memory.ShareableList(['howdy', b'HoWdY', -273.154, 100, None, True, 42]) >>> [ type(entry) for entry in a ] [<class 'str'>, <class 'bytes'>, <class 'float'>, <class 'int'>, <class 'NoneType'>, <class 'bool'>, <class 'int'>] >>> a[2] -273.154 >>> a[2] = -78.5 >>> a[2] -78.5 >>> a[2] = 'dry ice' # Changing data types is supported as well >>> a[2] 'dry ice' >>> a[2] = 'larger than previously allocated storage space' Traceback (most recent call last): ... ValueError: exceeds available storage for existing str >>> a[2] 'dry ice' >>> len(a) 7 >>> a.index(42) 6 >>> a.count(b'howdy') 0 >>> a.count(b'HoWdY') 1 >>> a.shm.close() >>> a.shm.unlink() >>> del a # Use of a ShareableList after call to unlink() is unsupported b = shared_memory.ShareableList(range(5)) # In a first process >>> c = shared_memory.ShareableList(name=b.shm.name) # In a second process >>> c ShareableList([0, 1, 2, 3, 4], name='...') >>> c[-1] = -999 >>> b[-1] -999 >>> b.shm.close() >>> c.shm.close() >>> c.shm.unlink() 6、共享内存管理器ManagerMultiprocessing 提供了 Manager 内存管理器类,当调用1个Manager实例对象的start()方法时,会创建1个manager进程,其唯一目的就是管理共享内存, 避免出现进程间共享数据不同步,内存泄露等现象。 其原理如下:
Manager管理器相当于提供了1个共享内存的服务,不仅可以被主进程创建的多个子进程使用,还可以被其它进程访问,甚至跨网络访问。本文仅聚焦于由单一主进程创建的各进程之间的通信。 1) Manager的主要数据结构相关类:multiprocessing.Manager
支持共享变量类型:
2) 使用步骤1)创建管理器对象 snm = Manager() snm = SharedMemoryManager() 2)创建共享内存变量 sl = snm.list(), snm.dict() 新建1块bytes共享内存变量,需要指定大小 sx = snm.SharedMemory(size) 新建1个共享列表变量,可用列表来初始化 sl = snm.ShareableList(sequence) 如 sl = smm.ShareableList([‘howdy', b'HoWdY', -273.154, 100, True]) 新建1个queue, 使用multiprocessing 的Queue类型 snm = Manager() q = snm.Queue() 示例 : from multiprocessing import Process, Manager
def f(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.reverse()
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(10))
p = Process(target=f, args=(d, l))
p.start()
p.join()
print(d)
print(l)将打印
3) 销毁共享内存变量方法一: >>> with SharedMemoryManager() as smm: ... sl = smm.ShareableList(range(2000)) ... # Divide the work among two processes, storing partial results in sl ... p1 = Process(target=do_work, args=(sl, 0, 1000)) ... p2 = Process(target=do_work, args=(sl, 1000, 2000)) ... p1.start() ... p2.start() # A multiprocessing.Pool might be more efficient ... p1.join() ... p2.join() # Wait for all work to complete in both processes ... total_result = sum(sl) # Consolidate the partial results now in sl 4) 向管理器注册自定义类型managers的子类BaseManager提供register()方法,支持注册自定义数据类型。如下例,注册1个自定义MathsClass类,并生成实例。 from multiprocessing.managers import BaseManager
class MathsClass:
def add(self, x, y):
return x + y
def mul(self, x, y):
return x * y
class MyManager(BaseManager):
pass
MyManager.register('Maths', MathsClass)
if __name__ == '__main__':
with MyManager() as manager:
maths = manager.Maths()
print(maths.add(4, 3)) # prints 7
print(maths.mul(7, 8)) |
Das obige ist der detaillierte Inhalt vonWie implementiert man Multiprocessing, um die Kommunikation zwischen Prozessen in Python zu implementieren?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!