
Heim >Backend-Entwicklung >Python-Tutorial >Wie verarbeitet Python Excel-Dateien?
Wie verarbeitet Python Excel-Dateien?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-08 17:58:152001Durchsuche
『Problembeschreibung』
Das zu verarbeitende Excel hat dieses Mal zwei Blätter, und der Wert des anderen Blattes muss basierend auf den Daten eines Blattes berechnet werden. Das Problem besteht darin, dass das zu berechnende Blatt nicht nur Zahlenwerte, sondern auch Formeln enthält. Werfen wir einen Blick darauf:
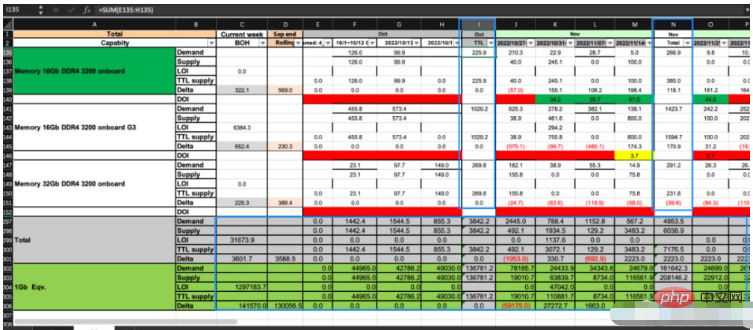
Wie im Bild oben gezeigt, hat dieses Excel insgesamt zwei Blätter: CP und DS. Wir müssen bestimmte Geschäfte befolgen Regeln berechnen die Daten der entsprechenden Zelle in DS basierend auf den Daten in CP. Die blauen Kästchen im Bild enthalten Formeln, während andere Bereiche numerische Werte enthalten.
Mal sehen, ob wir der zuvor erwähnten Verarbeitungslogik folgen, Excel stapelweise auf einmal in den Datenrahmen einlesen und es dann stapelweise auf einmal zurückschreiben. Dieser Teil des Codes lautet wie folgt:
import pandas as pd
import xlwings as xw
#要处理的文件路径
fpath = "data/DS_format.xlsm"
#把CP和DS两个sheet的数据分别读入pandas的dataframe
cp_df = pd.read_excel(fpath,sheet_name="CP",header=[0])
ds_df = pd.read_excel(fpath,sheet_name="DS",header=[0,1])
#计算过程省略......
#保存结果到excel
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()Das Problem mit dem obigen Code besteht darin, dass die Formeln dies tun, wenn die Methode pd.read_excel() Daten aus Excel in den Datenrahmen liest direkt lesen Das berechnete Ergebnis (wenn es kein Ergebnis gibt, wird Nan zurückgegeben), und wenn wir in Excel schreiben, schreiben wir den Datenrahmen direkt in Stapeln auf einmal zurück, sodass die Zellen mit der Formel zuvor mit dem berechneten Wert zurückgeschrieben werden oder Nan. Und die Formel verloren.
Okay, es ist ein Problem aufgetreten, wie sollen wir es lösen? Hier fallen mir zwei Ideen ein:
Wenn der Datenrahmen nach Excel zurückgeschrieben wird, schreiben Sie ihn nicht stapelweise auf einmal zurück, sondern schreiben Sie nur die Berechnung durch Iteration zurück Zeilen und Spalten Die Daten, Zellen mit Formeln werden nicht verschoben;
Gibt es beim Lesen von Excel eine Möglichkeit, Formeln für Zellen mit Formeln ohne zu lesen? Es ist nicht das Ergebnis Ich habe die beiden oben genannten Ideen einzeln ausprobiert.
「Option 1」
Der folgende Code versucht, den Datenrahmen zu durchlaufen und den entsprechenden Wert pro Zelle zu schreiben.
#根据ds_df来写excel,只写该写的单元格
for row_idx,row in ds_df.iterrows():
total_capabity_val = row[('Total','Capabity')].strip()
total_capabity1_val = row[('Total','Capabity.1')].strip()
#Total和1Gb Eqv.所在的行不写
if total_capabity_val!= 'Total' and total_capabity_val != '1Gb Eqv.':
#给Delta和LOI赋值
if total_capabity1_val == 'LOI' or total_capabity1_val == 'Delta':
ds_worksheet.range((row_idx + 3 ,3)).value = row[('Current week','BOH')]
print(f"ds_sheet的第{row_idx + 3}行第3列被设置为{row[('Current week','BOH')]}")
#给Demand和Supply赋值
if total_capabity1_val == 'Demand' or total_capabity1_val == 'Supply':
cp_datetime_columns = cp_df.columns[53:]
for col_idx in range(4,len(ds_df.columns)):
ds_datetime = ds_df.columns.get_level_values(1)[col_idx]
ds_month = ds_df.columns.get_level_values(0)[col_idx]
if type(ds_datetime) == str and ds_datetime != 'TTL' and ds_datetime != 'Total' and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',f'{ds_datetime}')]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',f'{ds_datetime}')]}")
elif type(ds_datetime) == datetime.datetime and (ds_datetime in cp_datetime_columns):
ds_worksheet.range((row_idx + 3,col_idx + 1)).value = row[(f'{ds_month}',ds_datetime)]
print(f"ds_sheet的第{row_idx + 3}行第{col_idx + 1}列被设置为{row[(f'{ds_month}',ds_datetime)]}")#🎜 🎜 #Der obige Code löst das Problem, das heißt, die Formeln von Zellen mit Formeln bleiben erhalten. Gemäß den am Anfang unseres Artikels erwähnten Hinweisen zur Python-Verarbeitung weist dieser Code jedoch schwerwiegende Leistungsprobleme auf, da er häufig Excel-Zellen über die API ausführt, was dazu führt, dass das Schreiben auf meinem alten Mac sehr langsam ist 40 Minuten, was einfach inakzeptabel war, sodass der Plan aufgegeben werden musste. 「Option 2」Diese Lösung hofft, den Formelwert beim Lesen von Zellen mit Formelwerten in Excel beizubehalten. Dies kann nur über die API jeder Python-Excel-Bibliothek gefunden werden, um zu sehen, ob es eine entsprechende Methode gibt. Ich habe mir die read_excel()-Methode von Pandas genau angesehen und festgestellt, dass es keine entsprechende Parameterunterstützung gibt. Ich habe eine API gefunden, die Openpyxl unterstützen kann, wie folgt: import openpyxl ds_format_workbook = openpyxl.load_workbook(fpath,data_only=False) ds_wooksheet = ds_format_workbook['DS'] ds_df = pd.DataFrame(ds_wooksheet.values)Der Schlüssel ist hier der data_only-Parameter. Wenn er „True“ ist, werden die Daten zurückgegeben. Wenn er „False“ ist, kann der Formelwert sein beibehalten
#🎜🎜 #Ich dachte, ich hätte die entsprechende Lösung gefunden und war begeistert, aber als ich sah, wie die Datenstruktur im Datenrahmen über openpyxl gelesen wurde, war ich schockiert. Da der Header meiner Excel-Tabelle ein relativ komplexer zweistufiger Header ist und es Situationen gibt, in denen Zellen im Header zusammengeführt und geteilt werden, folgt ein solcher Header nicht dem mehrstufigen, nachdem er von openpyxl in den Datenrahmen eingelesen wurde Header von Pandas. Der Index wird verarbeitet, aber einfach in einen numerischen Index 0123 verarbeitet...
Aber meine Berechnung des Datenrahmens basiert auf mehrstufigen Indizes, daher ist diese Verarbeitungsmethode von openpyxl geeignet Meine nachfolgenden Berechnungen sind unmöglich.
openpyxl funktioniert nicht, was ist mit xlwings? Nachdem ich die xlwings-API-Dokumentation durchgesehen hatte, habe ich sie tatsächlich gefunden, wie unten gezeigt:
Die Range-Klasse stellt eine Eigenschaft namens Formel bereit, die Get und abrufen kann Formel festlegen. Als ich das sah, hatte ich das Gefühl, einen Schatz gefunden zu haben, und begann schnell, den Code zu üben. Vielleicht aus Trägheit, oder vielleicht hatte ich Angst vor der Effizienz, Excel in der Vergangenheit zeilen-, spalten- und zellenweise zu bedienen, war die erste Lösung, die mir in den Sinn kam, dies stapelweise auf einmal zu tun, also alle Formeln zu lesen in Excel auf einmal und schreibe sie dann alle auf einmal, also war mein ursprünglicher Code so:#使用xlwings来读取formula app = xw.App(visible=False,add_book=False) ds_format_workbook = app.books.open(fpath) ds_worksheet = ds_format_workbook.sheets["DS"] #先把所有公式一次性读取并保存下来 formulas = ds_worksheet.used_range.formula #中间计算过程省略... #一次性把所有公式写回去 ds_worksheet.used_range.formula = formulas
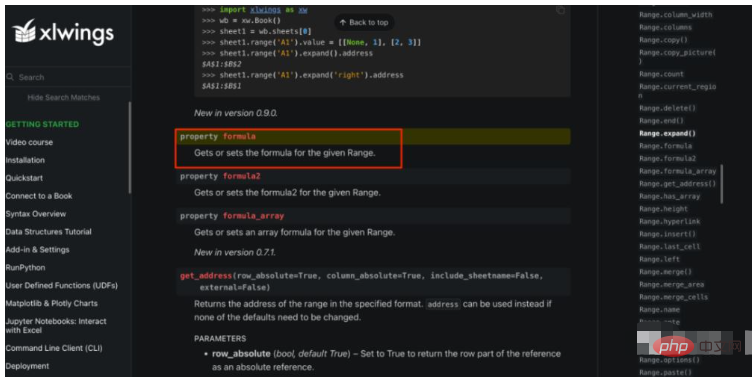 Aber ich habe falsch gedacht, dass die Formel falsch ist In Excel werden nur Zellen mit Formeln zurückgegeben. Tatsächlich werden alle Zellen zurückgegeben, die Formeln werden jedoch nur für Zellen mit Formeln beibehalten. Wenn ich die Formel zurückschreibe, werden daher die anderen Werte überschrieben, die ich über den Datenrahmen berechnet und in Excel geschrieben habe.
Aber ich habe falsch gedacht, dass die Formel falsch ist In Excel werden nur Zellen mit Formeln zurückgegeben. Tatsächlich werden alle Zellen zurückgegeben, die Formeln werden jedoch nur für Zellen mit Formeln beibehalten. Wenn ich die Formel zurückschreibe, werden daher die anderen Werte überschrieben, die ich über den Datenrahmen berechnet und in Excel geschrieben habe.
In diesem Fall kann ich die Zellen mit Formeln nur einzeln und nicht alle auf einmal verarbeiten, daher muss der Code so geschrieben werden:
#使用xlwings来读取formula
app = xw.App(visible=False,add_book=False)
ds_format_workbook = app.books.open(fpath)
ds_worksheet = ds_format_workbook.sheets["DS"]
#保留excel中的formula
#找到DS中Total所在的行,Total之后的行都是formula
row = ds_df.loc[ds_df[('Total','Capabity')]=='Total ']
total_row_index = row.index.values[0]
#获取对应excel的行号(dataframe把两层表头当做索引,从数据行开始计数,而且从0开始计数。excel从表头就开始计数,而且从1开始计数)
excel_total_row_idx = int(total_row_index+2)
#获取excel最后一行的索引
excel_last_row_idx = ds_worksheet.used_range.rows.count
#保留按日期计算的各列的formula
I_col_formula = ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula
N_col_formula = ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula
T_col_formula = ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula
U_col_formula = ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula
Z_col_formula = ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula
AE_col_formula = ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula
AK_col_formula = ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula
AL_col_formula = ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula
#保留Total行开始一直到末尾所有行的formula
total_to_last_formula = ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula
#中间计算过程省略...
#保存结果到excel
#直接把ds_df完整赋值给excel,会导致excel原有的公式被值覆盖
ds_worksheet.range("A1").expand().options(index=False).value = ds_df
#用之前保留的formulas,重置公式
ds_worksheet.range(f'I3:I{excel_total_row_idx}').formula = I_col_formula
ds_worksheet.range(f'N3:N{excel_total_row_idx}').formula = N_col_formula
ds_worksheet.range(f'T3:T{excel_total_row_idx}').formula = T_col_formula
ds_worksheet.range(f'U3:U{excel_total_row_idx}').formula = U_col_formula
ds_worksheet.range(f'Z3:Z{excel_total_row_idx}').formula = Z_col_formula
ds_worksheet.range(f'AE3:AE{excel_total_row_idx}').formula = AE_col_formula
ds_worksheet.range(f'AK3:AK{excel_total_row_idx}').formula = AK_col_formula
ds_worksheet.range(f'AL3:AL{excel_total_row_idx}').formula = AL_col_formula
ds_worksheet.range(f'A{excel_total_row_idx+1}:AL{excel_last_row_idx}').formula = total_to_last_formula
ds_format_workbook.save()
ds_format_workbook.close()
app.quit()Nach dem Testen ist es ist wie oben. Der Code entspricht perfekt meinen Anforderungen und hat keine Probleme mit der Leistung.
Das obige ist der detaillierte Inhalt vonWie verarbeitet Python Excel-Dateien?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!