
Heim >Java >javaLernprogramm >Wie konvertiere ich Excel-Daten in eine Baumstruktur in Java?
Wie konvertiere ich Excel-Daten in eine Baumstruktur in Java?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-08 08:49:072380Durchsuche
Vorwort
Ich habe heute eine Importaufgabe erhalten, die das Speichern von Excel-Daten in der Datenbank erfordert. Anders als beim normalen Import handelt es sich bei den importierten Daten um eine Baumstruktur, wie unten gezeigt:
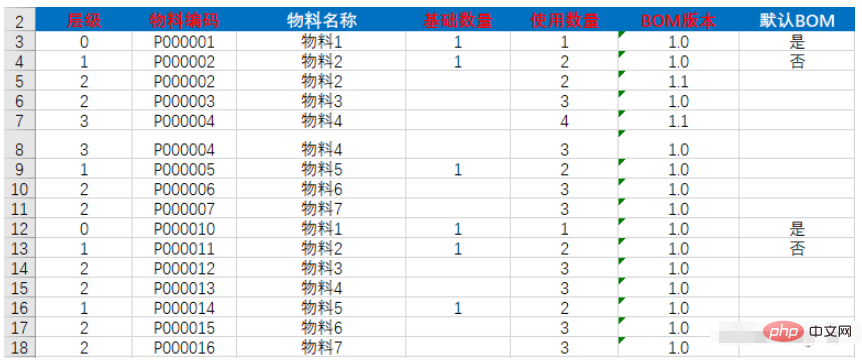
Durch Beobachtung der Daten in der hierarchischen Spalte Wir stellen fest, dass die Tabellendaten aus 2 Bäumen bestehen, nämlich 3, 4, 5, 6, 7, 8, 9, 10, 11 und 12, 13, 14, 15, 16, 17, 18, die aus 0 bestehen Als Wurzelknoten des Baums ist 1 der untergeordnete Knoten von 0 und 2 der untergeordnete Knoten der benachbarten 1. Daraus ergibt sich die Struktur des ersten Baums:
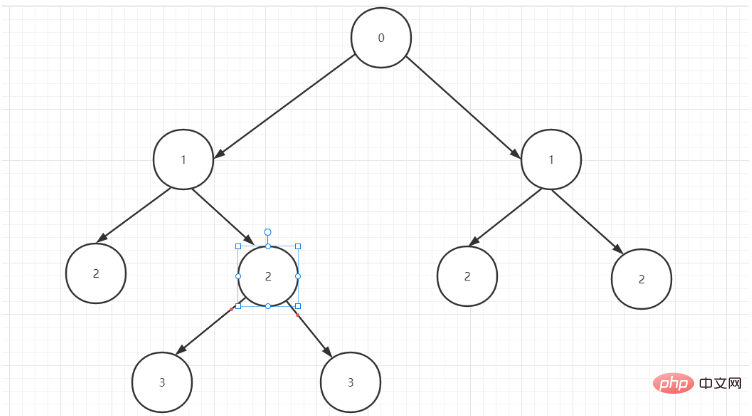
Teilen Sie die Originaldaten auf
1 . Erstellen Sie eine Entitätsklasse
Erstellen Sie vo, um analysierte Daten zu erhalten
@Excel(name = "层级")
private String hierarchy;
@Excel(name = "物料编码")
private String materialCode;
@Excel(name = "物料名称")
private String materialName;
@Excel(name = "基础数量")
private BigDecimal materialNum;
@Excel(name = "使用数量")
private BigDecimal useAmount;
@Excel(name = "BOM版本")
private String version;
@Excel(name = "默认BOM")
private String isDefaults;2 Verarbeiten Sie die Datenquelle in mehrere Baumdatensätze
Der Code lautet wie folgt (Beispiel). :
/**
* 将集合对象按指定元素分割存储
*
* @param materialVos 原始集合
* @param s 分割元素(这里是当集合对象层级为0时则分割,也就是树的根节点为0)
* @return 每棵树的结果集
*/
private List<List<MatMaterialBomImportVo>> subsection(List<MatMaterialBomImportVo> materialVos, String s) {
List<List<MatMaterialBomImportVo>> segmentedData = new ArrayList<>();
if (materialVos != null) {
//获取指定元素的数量,判断出最终将拆分为多少段
List<MatMaterialBomImportVo> collect = materialVos.stream().filter(bom -> s.equals(bom.getHierarchy())).collect(Collectors.toList());
int count = 0;
for (int i = 0; i < collect.size(); i++) {
List<MatMaterialBomImportVo> bomImportVo = new ArrayList<>();
boolean num = false;
//遍历数据源
for (; count < materialVos.size(); count++) {
//第一个必然为树的根节点,直接获取并跳过
if (count == 0) {
bomImportVo.add(materialVos.get(count));
continue;
}
//当数据源第n个等于根节点并且已经成功添加过数据时判断为一段数据的结束,跳出循环,
if (s.equals(materialVos.get(count).getHierarchy()) && num) {
break;
}
bomImportVo.add(materialVos.get(count));
num = true;
}
segmentedData.add(bomImportVo);
}
}
return segmentedData;
}Manuelle Einstellungen Die ID und die übergeordnete ID jedes Knotens jedes Baums
Der Code lautet wie folgt (Beispiel):
for (List<MatMaterialBomImportVo> segmentedDatum : subsection(materialVos, "0")) {
//设置id以及父id
int i = 0;
for (MatMaterialBomImportVo vo : segmentedDatum) {
BeanTrim.beanAttributeValueTrim(vo);
vo.setPrimaryKey(i);
getParentId(vo, segmentedDatum);
i++;
}
}
/**
* 设置父id
*
* @param vo
* @param segmentedDatum
*/
private void getParentId(MatMaterialBomImportVo vo, List<MatMaterialBomImportVo> segmentedDatum) {
for (int j = vo.getPrimaryKey(); j >= 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
break;
}
if (j == 0) {
vo.setForeignKey(-1);
}
}
}Anweisungen: Legen Sie nach der Aufteilung in mehrere Bäume die virtuelle ID jedes Datenelements als seine fest Eigener Index, und die IDs jedes Baums sind voneinander isoliert.
Gemäß den Regeln der Tabellendaten kann daraus geschlossen werden, dass untergeordnete Knoten nur unterhalb ihres eigenen Knotens und oberhalb des nächsten gleichen Knotens existieren können Regel: Legen Sie die übergeordnete ID jedes Knotens fest. Rekursiv in eine Baumstruktur gekapselt. Der Code lautet wie folgt (Beispiel): Aufgrund geschäftlicher Anforderungen wurde dieser Satz rekursiver Methoden nicht zum späteren Zusammenstellen des Baums verwendet. Daher kann der rekursive Code nur als Referenz einige Fehler aufweisen
Das obige ist der detaillierte Inhalt vonWie konvertiere ich Excel-Daten in eine Baumstruktur in Java?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!