
Heim >Backend-Entwicklung >Python-Tutorial >Wie erstelle ich einen mehrstufigen Index (MultiIndex) mit der Pandas-Bibliothek von Python?
Wie erstelle ich einen mehrstufigen Index (MultiIndex) mit der Pandas-Bibliothek von Python?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-05-07 14:55:082948Durchsuche
Einführung
pd.MultiIndex, ein Index mit mehreren Ebenen. Durch mehrstufige Indizes können wir die Daten der gesamten Indexgruppe verwalten. In diesem Artikel werden hauptsächlich 6 Möglichkeiten zum Erstellen mehrstufiger Indizes in Pandas vorgestellt:
pd.MultiIndex.from_arrays(): Mehrdimensionale Arrays werden als Parameter verwendet, hohe Dimensionalität gibt Indizes auf hoher Ebene an und niedrige Dimensionalität spezifiziert Low-Level-Indizes.
pd.MultiIndex.from_tuples(): Liste von Tupeln als Argument, wobei jedes Tupel jeden Index angibt (hoch- und niedrigdimensionaler Index).
pd.MultiIndex.from_product(): Eine Liste iterierbarer Objekte wird als Parameter verwendet und der Index wird basierend auf dem kartesischen Produkt (paarweise Kombination von Elementen) mehrerer iterierbarer Objektelemente erstellt.
pd.MultiIndex.from_frame: Direkt generiert basierend auf dem vorhandenen Datenrahmen
groupby(): Erhalten durch Datengruppierungsstatistiken
pivot_table(): Erhalten durch Generieren einer Pivot-Tabelle
pd .MultiIndex.from_arrays()
In [1]:
import pandas as pd import numpy as np
wird durch ein Array generiert, das normalerweise die Elemente in der Liste angibt:
In [2]:
# 列表元素是字符串和数字
array1 = [["xiaoming","guanyu","zhangfei"],
[22,25,27]
]
m1 = pd.MultiIndex.from_arrays(array1)
m1Out[2]:
MultiIndex([('xiaoming', 22), ( 'guanyu', 25), ('zhangfei', 27)],
)In [ 3]:
type(m1) # 查看数据类型
Sehen Sie sich den Datentyp über die Typfunktion an und stellen Sie fest, dass es sich tatsächlich um: MultiIndex
Out[3]:
pandas.core.indexes.multi.MultiIndex
Sie können beim Erstellen den Namen jeder Ebene angeben:
In [4]:
# 列表元素全是字符串
array2 = [["xiaoming","guanyu","zhangfei"],
["male","male","female"]
]
m2 = pd.MultiIndex.from_arrays(
array2,
# 指定姓名和性别
names=["name","sex"])
m2Out[4]:
MultiIndex([('xiaoming', 'male'), ( 'guanyu', 'male'), ('zhangfei', 'female')],
names=['name', 'sex'])Das folgende Beispiel generiert drei Ebenen von Indizes und gibt Namen an:
In [5]:
array3 = [["xiaoming","guanyu","zhangfei"],
["male","male","female"],
[22,25,27]
]
m3 = pd.MultiIndex.from_arrays(
array3,
names=["姓名","性别","年龄"])
m3Out[5]:
MultiIndex([('xiaoming', 'male', 22), ( 'guanyu', 'male', 25), ('zhangfei', 'female', 27)],
names=['姓名', '性别', '年龄'])pd.MultiIndex.from_tuples ()
Generieren Sie mehrstufige Indizes in Form von Tupeln:
In [6]:
# 元组的形式
array4 = (("xiaoming","guanyu","zhangfei"),
(22,25,27)
)
m4 = pd.MultiIndex.from_arrays(array4)
m4Out[6]:
MultiIndex([('xiaoming', 22), ( 'guanyu', 25), ('zhangfei', 27)],
)In [7]:
# 元组构成的3层索引
array5 = (("xiaoming","guanyu","zhangfei"),
("male","male","female"),
(22,25,27))
m5 = pd.MultiIndex.from_arrays(array5)
m5Out[7]:
MultiIndex([('xiaoming', 'male', 22), ( 'guanyu', 'male', 25), ('zhangfei', 'female', 27)],
)Liste und Tupel können sein gemischt
Die äußerste Ebene ist eine Liste Liste iterierbarer Objekte als Parameter und erstellt einen Index basierend auf dem kartesischen Produkt (paarweise Kombination von Elementen) mehrerer iterierbarer Objektelemente.
In Python verwenden wir die Funktion - , um zu bestimmen, ob ein Python-Objekt iterierbar ist:
array6 = [("xiaoming","guanyu","zhangfei"), ("male","male","female"), (18,35,27) ] # 指定名字 m6 = pd.MultiIndex.from_arrays(array6,names=["姓名","性别","年龄"]) m6
MultiIndex([('xiaoming', 'male', 18), ( 'guanyu', 'male', 35), ('zhangfei', 'female', 27)],
names=['姓名', '性别', '年龄'] # 指定名字
)isinstance()Out[18]:# 导入 collections 模块的 Iterable 对比对象 from collections import Iterable
In [19]:
names = ["xiaoming","guanyu","zhangfei"]
numbers = [22,25]
m7 = pd.MultiIndex.from_product(
[names, numbers],
names=["name","number"]) # 指定名字
m7Out[19]:MultiIndex([('xiaoming', 22), ('xiaoming', 25), ( 'guanyu', 22), ( 'guanyu', 25), ('zhangfei', 22), ('zhangfei', 25)],
names=['name', 'number']) In [20]:
In [20]: # 需要展开成列表形式
strings = list("abc")
lists = [1,2]
m8 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m8 Out[20]:
MultiIndex([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('c', 1), ('c', 2)],
names=['alpha', 'number'])In [21]:
# 使用元组形式
strings = ("a","b","c")
lists = [1,2]
m9 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m9Out[21]:
MultiIndex([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('c', 1), ('c', 2)],
names=['alpha', 'number'])In [22]:
# 使用range函数
strings = ("a","b","c") # 3个元素
lists = range(3) # 0,1,2 3个元素
m10 = pd.MultiIndex.from_product(
[strings, lists],
names=["alpha","number"])
m10Die Gesamtzahl ist „332=18“:
Out[ 22 ]:
MultiIndex([('a', 0), ('a', 1), ('a', 2), ('b', 0), ('b', 1), ('b', 2), ('c', 0), ('c', 1), ('c', 2)],
names=['alpha', 'number'])pd.MultiIndex.from_frame()
Erzeugen Sie direkt einen mehrstufigen Index über den vorhandenen DataFrame:
# 使用range函数
strings = ("a","b","c")
list1 = range(3) # 0,1,2
list2 = ["x","y"]
m11 = pd.MultiIndex.from_product(
[strings, list1, list2],
names=["name","l1","l2"]
)
m11 # 总个数 3*3*2=18
Der mehrstufige Index wird direkt generiert und der Name ist das Spaltenfeld von der vorhandene Datenrahmen:In [24]:
MultiIndex([('a', 0, 'x'), ('a', 0, 'y'), ('a', 1, 'x'), ('a', 1, 'y'), ('a', 2, 'x'), ('a', 2, 'y'), ('b', 0, 'x'), ('b', 0, 'y'), ('b', 1, 'x'), ('b', 1, 'y'), ('b', 2, 'x'), ('b', 2, 'y'), ('c', 0, 'x'), ('c', 0, 'y'), ('c', 1, 'x'), ('c', 1, 'y'), ('c', 2, 'x'), ('c', 2, 'y')],
names=['name', 'l1', 'l2'])Out[24]:df = pd.DataFrame({"name":["xiaoming","guanyu","zhaoyun"],
"age":[23,39,34],
"sex":["male","male","female"]})
dfGeben Sie den Namen über den Namensparameter an: In [25]:pd.MultiIndex.from_frame(df)Out[25]:
MultiIndex([('xiaoming', 23, 'male'), ( 'guanyu', 39, 'male'), ( 'zhaoyun', 34, 'female')],
names=['name', 'age', 'sex'])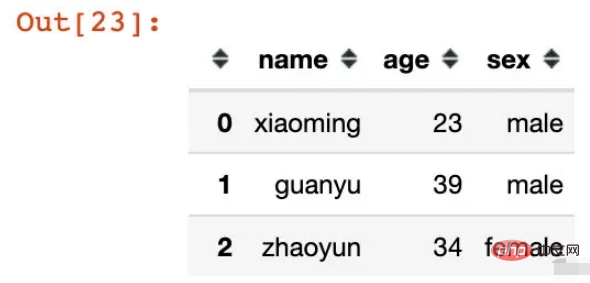 groupby ()
groupby ()
durch die Groupby-Funktion Die Gruppierungsfunktion wird wie folgt berechnet:
In [26]:
# 可以自定义名字 pd.MultiIndex.from_frame(df,names=["col1","col2","col3"])
Out[26]:
MultiIndex([('xiaoming', 23, 'male'), ( 'guanyu', 39, 'male'), ( 'zhaoyun', 34, 'female')],
names=['col1', 'col2', 'col3'])
Index der Daten anzeigen:
In [ 28]:
df1 = pd.DataFrame({"col1":list("ababbc"),
"col2":list("xxyyzz"),
"number1":range(90,96),
"number2":range(100,106)})
df1Out[28]:
df2 = df1.groupby(["col1","col2"]).agg({"number1":sum,
"number2":np.mean})
df2pivot_table()
wird über die Pivot-Funktion erhalten: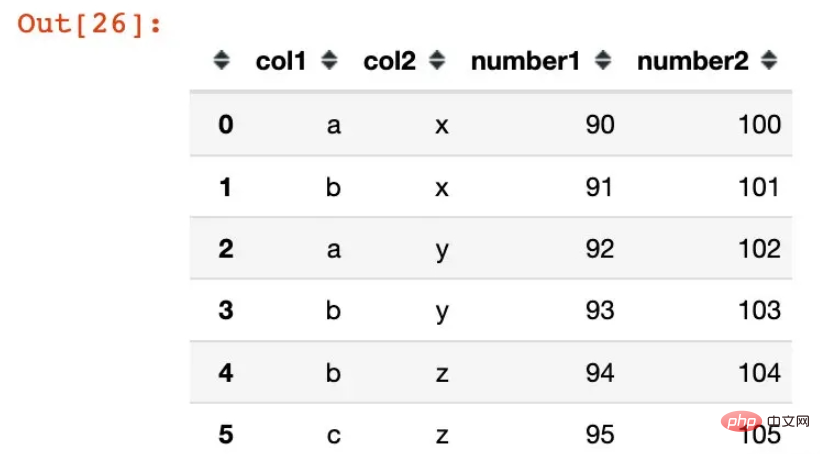
df2.index
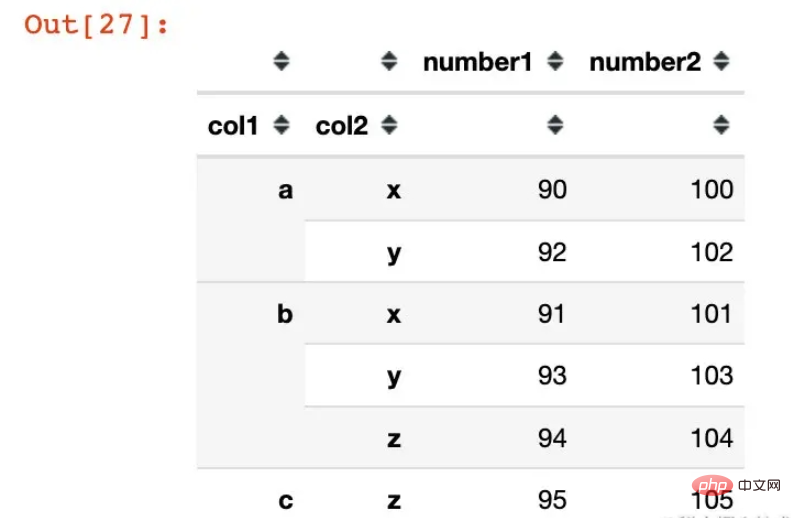 In [30]:
In [30]:MultiIndex([('a', 'x'), ('a', 'y'), ('b', 'x'), ('b', 'y'), ('b', 'z'), ('c', 'z')],
names=['col1', 'col2'])Out[30 ]:df3 = df1.pivot_table(values=["col1","col2"],index=["col1","col2"]) df3
Das obige ist der detaillierte Inhalt vonWie erstelle ich einen mehrstufigen Index (MultiIndex) mit der Pandas-Bibliothek von Python?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!