
Heim >Java >javaLernprogramm >Wie die Java-Architektur auf verschiedene Produkte angewendet wird
Wie die Java-Architektur auf verschiedene Produkte angewendet wird

- 王林nach vorne
- 2023-05-04 23:01:131136Durchsuche
Wenn wir ein System einrichten, müssen wir normalerweise überlegen, wie wir mit anderen Systemen interagieren. Daher müssen wir zunächst wissen, wie verschiedene Systeme miteinander interagieren und welche Technologie zur Implementierung verwendet wird.
1. Interaktion zwischen verschiedenen Systemen und verschiedenen Sprachen
Heutzutage verwenden unsere gemeinsamen Interaktionen zwischen verschiedenen Systemen und verschiedenen Sprachen WebService- und HTTP-Anfragen. WebService, also „Webdienst“, abgekürzt als WS. Im wörtlichen Sinne handelt es sich tatsächlich um einen „webbasierten Dienst“. Aber Dienstleistungen sind für beide Seiten da. Wenn es einen Dienstleistungsnachfrager gibt, wird es auch einen Dienstleistungsanbieter geben. Der Dienstanbieter veröffentlicht Dienste nach außen, und der Dienstnachfrager ruft die vom Dienstanbieter veröffentlichten Dienste auf. Um es professioneller auszudrücken: WS ist eigentlich ein Tool, das auf dem HTTP-Protokoll basiert, um eine heterogene Systemkommunikation zu erreichen. Das ist richtig! Um es ganz klar auszudrücken: WS basiert auf dem HTTP-Protokoll, das heißt, die Daten werden über HTTP übertragen. Zuerst haben wir CXF verwendet, um SOAP-Dienste zur Implementierung von WS zu entwickeln, und später haben wir REST-Dienste zur Implementierung von WS verwendet (dies wird derzeit häufiger verwendet, und es ist auch das, was ich am häufigsten verwende). REST-Dienste können auch auf Basis von CXF entwickelt werden, wir verwenden jedoch im Allgemeinen springMVC oder andere MVC-Frameworks direkt, um REST-Dienste zu implementieren.
Aber in den Köpfen vieler Menschen beziehen sich Webdienste im Allgemeinen auf verschiedene XML-basierte interaktive Technologien, die vor mehr als zehn Jahren von IBM eingeführt wurden. Mit Ausnahme einiger Unternehmen nutzen sie heutzutage nur noch wenige. Im weitesten Sinne ist Webservice ein Webdienst, und alles ist ein Dienst.
2. Interaktion zwischen verschiedenen Systemen mit derselben Sprache
Gemeinsame Interaktionen zwischen verschiedenen Systemen mit derselben Sprache werden mithilfe von RPC (Remote Procedure Call) oder RMI (Remote Method Invocation) implementiert, natürlich ohne Bereitstellung externer Dienste Das oben genannte kann auch für die Interaktion zwischen denselben Sprachen verwendet werden, ich verwende jedoch normalerweise RPC.
Architektur verschiedener Produkte
3. Architekturentwicklung eines einzelnen Produkts
Im Allgemeinen verwenden wir den Entwicklungsprozess der Architektur, wenn wir nur ein Produkt für die Außenwelt bereitstellen müssen Service, um dies zu erreichen.
Der folgende Inhalt stammt von Zhihu
1) Entwicklung der verteilten Architektur Systemarchitekturentwicklung – Architektur im Anfangsstadium
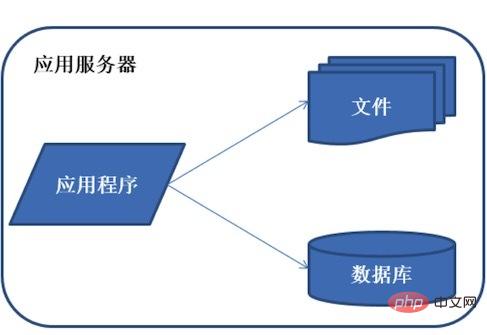
Alle Ressourcen wie kleine Systemanwendungen, Datenbanken, Dateien usw. im Anfangsstadium Alles auf einem Server, allgemein bekannt als LAMP
Funktionen: Alle Ressourcen wie Anwendungen, Datenbanken, Dateien usw. befinden sich auf einem Server.
Beschreibung: Normalerweise verwendet das Server-Betriebssystem Linux, die Anwendung wird mit PHP entwickelt und dann auf Apache bereitgestellt, die Datenbank verwendet MySQL und eine Vielzahl kostenloser Open-Source-Software und ein günstiger Server können mit der Entwicklung des Systems beginnen.
2) Entwicklung der Systemarchitektur – Trennung von Anwendungsdiensten und Datendiensten
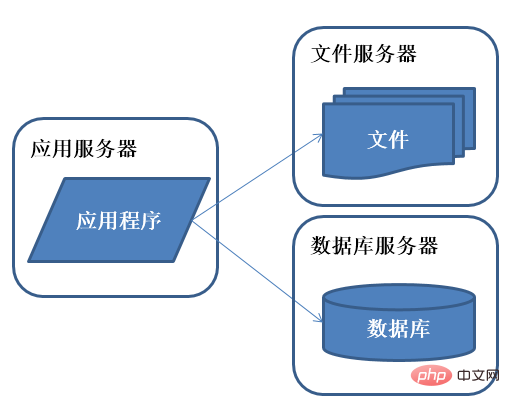
Die guten Zeiten hielten nicht lange an. Es zeigte sich, dass der Druck auf die Webserver-Maschine wieder zunimmt wird in Spitzenzeiten ein relativ hohes Niveau erreichen. Es ist an der Zeit, über das Hinzufügen eines Webservers nachzudenken.
Funktionen: Anwendungen, Datenbanken und Dateien werden auf unabhängigen Ressourcen bereitgestellt.
Beschreibung: Die Datenmenge nimmt zu, die Leistung und der Speicherplatz eines einzelnen Servers reichen nicht aus und Anwendungen und Daten müssen getrennt werden. Die gleichzeitige Verarbeitungsfähigkeit und der Datenspeicherplatz wurden erheblich verbessert.
3) Evolution der Systemarchitektur – Verwendung von Cache zur Verbesserung der Leistung
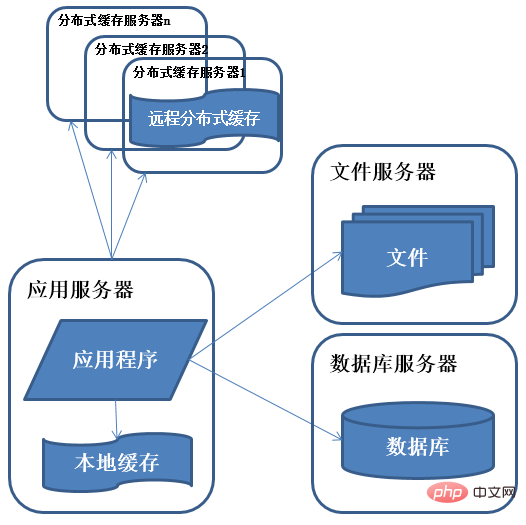
Funktionen: Ein kleiner Teil der Daten, auf die in der Datenbank intensiver zugegriffen wird, wird im Cache-Server gespeichert, wodurch die Anzahl der Datenbankzugriffe reduziert wird und Reduzierung des Zugriffsdrucks auf die Datenbank.
Beschreibung: Die Systemzugriffseigenschaften folgen der 80/20-Regel, d. h. 80 % des Geschäftszugriffs konzentrieren sich auf 20 % der Daten. Der Cache ist in lokalen Cache und entfernten verteilten Cache unterteilt. Der lokale Cache hat eine schnellere Zugriffsgeschwindigkeit, aber die Menge der zwischengespeicherten Daten ist begrenzt. Gleichzeitig kann er mit der Anwendung um Speicher konkurrieren.
4) Entwicklung der Systemarchitektur – Verwendung eines Anwendungsserverclusters
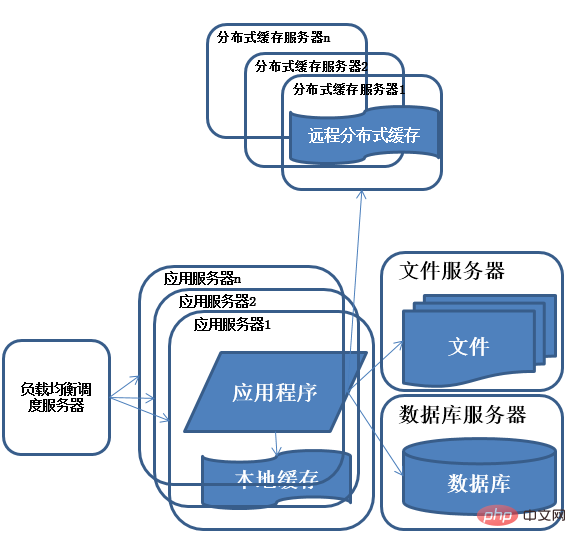
Nach Abschluss der Arbeiten an Unterdatenbank und Tabelle ist der Druck auf die Datenbank auf ein relativ niedriges Niveau gesunken, und ich habe begonnen, zuzusehen Der Zugriff jeden Tag erneut. Eines Tages stellte ich plötzlich fest, dass der Zugriff auf das System wieder langsamer wurde. Zu diesem Zeitpunkt überprüfte ich zuerst die Datenbank und stellte fest, dass der Druck normal war. Dann überprüfte ich, dass Apache blockiert war Es gibt viele Anfragen und der Anwendungsserver ist auch für jede Anfrage relativ schnell. Es scheint, dass die Anzahl der Anfragen zu hoch ist, was dazu führt, dass man in der Schlange stehen muss und die Antwortgeschwindigkeit langsam ist Durch Lastausgleich wird gleichzeitig die Verarbeitungsleistung und der Speicherplatz eines einzelnen Servers gelöst.
Beschreibung: Die Verwendung von Clustern ist eine gängige Methode für Systeme, um Probleme mit hoher Parallelität und massiven Daten zu lösen. Durch das Hinzufügen von Ressourcen zum Cluster werden die gleichzeitigen Verarbeitungsfähigkeiten des Systems verbessert, sodass der Lastdruck des Servers nicht mehr zum Engpass des gesamten Systems wird.
5) Entwicklung der Systemarchitektur – Datenbank-Lese- und Schreibtrennung
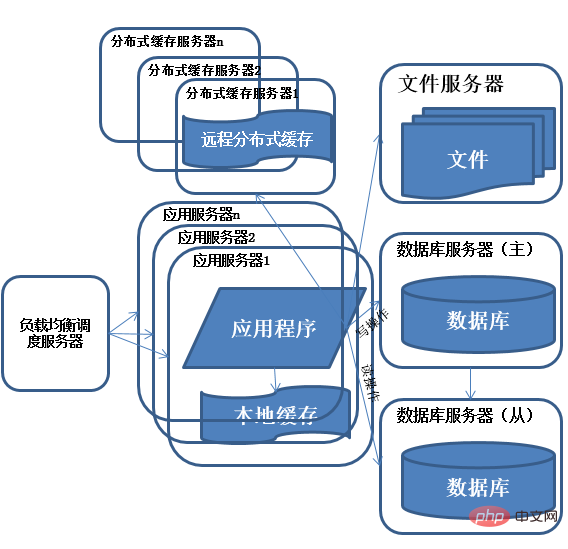
Nachdem ich eine Zeit lang das schnelle Wachstum der Systembesuche genossen hatte, stellte ich fest, dass das System wieder langsamer wurde Zeit? Nach dem Suchen und Finden von Datenbank-Schreib- und Aktualisierungsvorgängen ist der Wettbewerb um Datenbankverbindungsressourcen sehr groß, was zu einer Verlangsamung des Systems führt. Funktionen: Durch Lastausgleich stellen mehrere Server gleichzeitig Dienste nach außen bereit der Rechenleistung und des Speichers eines einzelnen Servers. Das Problem der Platzbeschränkung.
Beschreibung: Die Verwendung von Clustern ist eine gängige Methode für Systeme, um Probleme mit hoher Parallelität und massiven Daten zu lösen. Durch das Hinzufügen von Ressourcen zum Cluster wird der Lastdruck des Servers nicht mehr zum Engpass des gesamten Systems.
6) Weiterentwicklung der Systemarchitektur – Reverse-Proxy und CDN-Beschleunigung
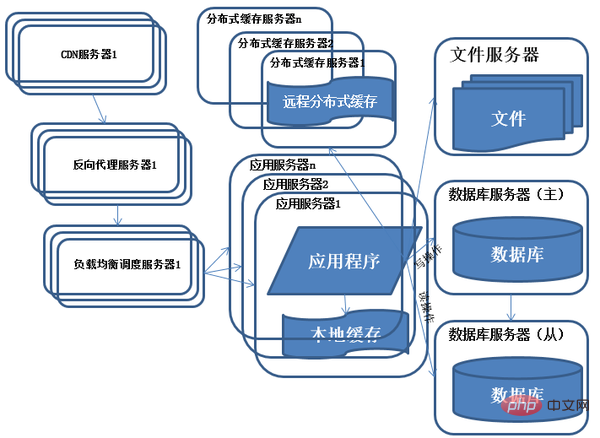 Funktionen: Verwenden Sie CDN und Reverse-Proxy, um den Systemzugriff zu beschleunigen.
Funktionen: Verwenden Sie CDN und Reverse-Proxy, um den Systemzugriff zu beschleunigen.
Beschreibung: Um die komplexe Netzwerkumgebung und den Zugriff von Benutzern in verschiedenen Regionen zu bewältigen, werden CDN und Reverse-Proxy verwendet, um den Benutzerzugriff zu beschleunigen und gleichzeitig den Lastdruck auf dem Back-End-Server zu verringern. Die Grundprinzipien von CDN und Reverse Proxy sind Caching.
7) Entwicklung der Systemarchitektur – verteiltes Dateisystem und verteilte Datenbank
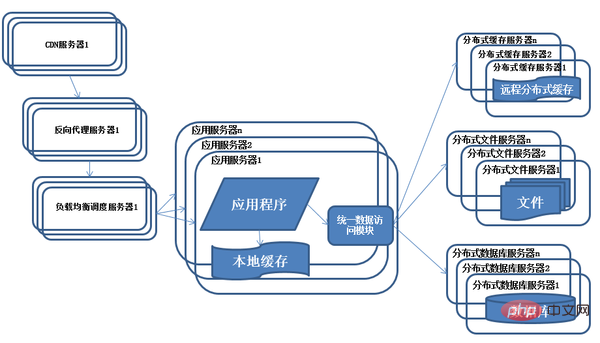 Während das System weiterläuft, beginnt die Datenmenge erheblich zuzunehmen. Zu diesem Zeitpunkt wird festgestellt, dass die Abfrage nach dem Die Aufteilung der Datenbank ist immer noch etwas langsam. Entsprechend der Idee der Unterdatenbank haben wir mit der Arbeit an der Tabellenteilung begonnen.
Während das System weiterläuft, beginnt die Datenmenge erheblich zuzunehmen. Zu diesem Zeitpunkt wird festgestellt, dass die Abfrage nach dem Die Aufteilung der Datenbank ist immer noch etwas langsam. Entsprechend der Idee der Unterdatenbank haben wir mit der Arbeit an der Tabellenteilung begonnen.
Beschreibung: Kein leistungsstarker einzelner Server kann die ständig wachsenden Geschäftsanforderungen großer Systeme erfüllen. Die Trennung von Datenbanklesen und -schreiben wird mit der Entwicklung des Unternehmens nicht mehr möglich sein zur Unterstützung genutzt werden. Die verteilte Datenbank ist die einzige Methode zur Systemdatenbankaufteilung. Sie wird nur verwendet, wenn der Umfang der einzelnen Tabellendaten sehr groß ist. Die am häufigsten verwendete Methode zur Datenbankaufteilung ist die Geschäftsunterdatenbank, bei der verschiedene Geschäftsdatenbanken auf verschiedenen physischen Servern bereitgestellt werden. Vorgesetzter.
8) Entwicklung der Systemarchitektur – Verwendung von NoSQL und Suchmaschinen
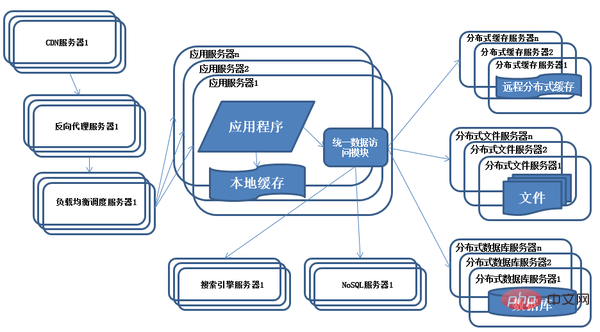
Beschreibung: Da das Geschäft immer komplexer wird, werden die Anforderungen an die Datenspeicherung und den Datenabruf immer komplexer. Das System muss einige nicht relationale Datenbanken wie NoSQL und Subdatenbank-Abfragetechnologien wie Suchmaschinen verwenden. Der Anwendungsserver greift über ein einheitliches Datenzugriffsmodul auf verschiedene Daten zu, wodurch die Probleme bei der Verwaltung vieler Datenquellen durch Anwendungen verringert werden.
9) Entwicklung der Systemarchitektur – Geschäftsaufteilung
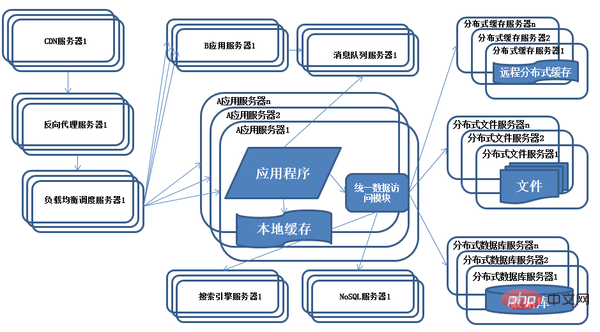 Funktionen: Das System wird je nach Geschäft aufgeteilt und transformiert, und Anwendungsserver werden entsprechend der Geschäftsdifferenzierung separat bereitgestellt.
Funktionen: Das System wird je nach Geschäft aufgeteilt und transformiert, und Anwendungsserver werden entsprechend der Geschäftsdifferenzierung separat bereitgestellt.
Beschreibung: Um immer komplexere Geschäftsszenarien zu bewältigen, werden üblicherweise Divide-and-Conquer-Methoden verwendet, um das gesamte Systemgeschäft in verschiedene Produktlinien aufzuteilen. Beziehungen werden zwischen Anwendungen über Hyperlinks hergestellt, und Daten können auch über Nachrichtenwarteschlangen verteilt werden. Natürlich gibt es noch mehr. Ein verbundenes Gesamtsystem entsteht durch den Zugriff auf dasselbe Datenspeichersystem. Vertikale Aufteilung: Teilen Sie eine große Anwendung in mehrere kleine Anwendungen auf. Wenn das neue Unternehmen relativ unabhängig ist, ist es relativ einfach, es als unabhängiges Webanwendungssystem zu entwerfen und bereitzustellen veräußert werden. Horizontale Aufteilung: Teilen Sie wiederverwendbare Unternehmen auf und stellen Sie sie unabhängig als verteilte Dienste bereit. Bei der horizontalen Aufteilung müssen wiederverwendbare Unternehmen identifiziert, Dienstschnittstellen entworfen und Dienstabhängigkeiten standardisiert werden.
10) Entwicklung der Systemarchitektur – Verteilte Dienste
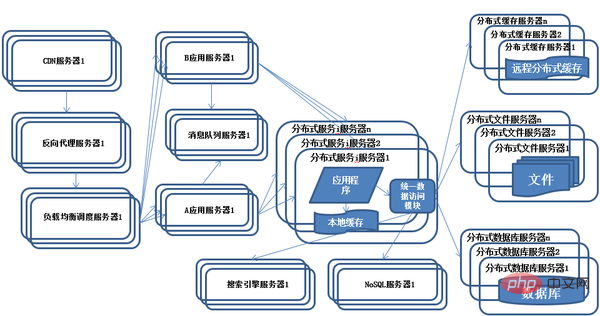
(1) Wenn es immer mehr Dienste gibt, wird die Verwaltung der Dienst-URL-Konfiguration sehr schwierig und der Einzelpunktdruck auf den F5-Hardware-Lastausgleicher nimmt ebenfalls zu.
(2) Mit der Weiterentwicklung werden die Abhängigkeiten zwischen Diensten so komplex, dass sogar unklar ist, welche Anwendung vor welcher Anwendung gestartet werden soll und der Architekt die architektonische Beziehung der Anwendung nicht vollständig beschreiben kann.
(3) Dann wird das Anrufvolumen des Dienstes immer größer und das Kapazitätsproblem des Dienstes wird offengelegt. Wie viele Maschinen werden benötigt, um diesen Dienst zu unterstützen? Wann sollte ich eine Maschine hinzufügen?
(4) Mit zunehmender Anzahl an Diensten steigen die Kommunikationskosten. An wen kann ich mich wenden, wenn die Anpassung eines bestimmten Dienstes fehlschlägt? Welche Konventionen gelten für Serviceparameter?
(5) Ein Dienst hat mehrere Geschäftskunden. Wie kann die Servicequalität sichergestellt werden?
(6) Bei der kontinuierlichen Aktualisierung von Diensten passieren immer einige unerwartete Dinge. Beispielsweise wird der Cache falsch geschrieben, was zu einem Speicherüberlauf führt. Jedes Mal, wenn ein Kerndienst ausfällt, wirkt sich dies auf einen großen Bereich aus bringt Menschen in Panik, wie kann man die Auswirkungen des Fehlers kontrollieren? Können Dienste funktional herabgestuft werden? Oder Ressourcendegradation?
Dies scheint der Beginn der Grundprinzipien und der Fallanalyse der technischen Architektur großer Websites zu sein, aber der Autor hat es gut zusammengefasst, daher werde ich es noch einmal drucken.
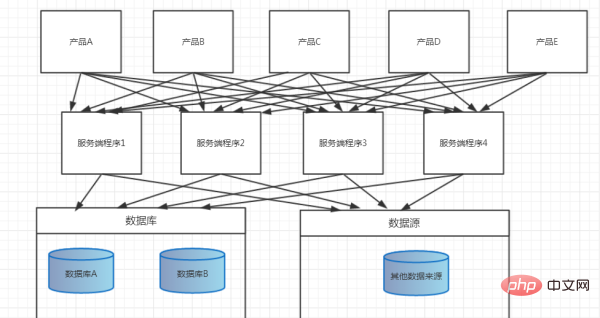
4. Produktlinienstruktur
Eine weitere Möglichkeit ist die oben erwähnte Geschäftsaufteilung. Jetzt müssen wir nur noch eine Datenschicht, eine allgemeine Geschäftslogikschicht und verschiedene Anwendungs- und Schnittstellenschichten aufbauen Früher haben wir uns normalerweise für die Verwendung von EJB zum Erstellen verteilter Anwendungen entschieden. Jetzt können wir RPC-Frameworks wie Dobbo, Thrift, Avro und Hessian verwenden, um verteilte Anwendungen zu erstellen und die Interaktion zwischen verschiedenen Anwendungen und Datenquellen zu erreichen. Wenn wir im Rahmen dieses Strukturmodells Dienste für andere Unternehmen bereitstellen müssen, können wir eine dedizierte Anwendung schreiben, um externe Systeme mit Restdiensten zu versorgen. Im Allgemeinen müssen die meisten Internetdienste auf ein Dutzend oder sogar Hunderte interne Dienste zugreifen, und die Kommunikationsmethode zwischen ihnen ist im Allgemeinen RPC: Genau wie beim Zugriff auf eine Remote-Methode geben Sie Parameter ein und warten auf die Rückgabe des Ergebnisses. Dies ist der am einfachsten zu verstehende Weg, komplexe Systeme aufzubauen.
Das im Bild unten gezeigte Modell, Dateisystem und Cache werden nicht angezeigt, sodass sie jeder verstehen kann.
Das obige ist der detaillierte Inhalt vonWie die Java-Architektur auf verschiedene Produkte angewendet wird. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!