
Heim >Java >javaLernprogramm >So stellen Sie die Cache-Konsistenz in Java sicher
So stellen Sie die Cache-Konsistenz in Java sicher

- 王林nach vorne
- 2023-05-02 13:13:161277Durchsuche
Option 1: Cache aktualisieren, Datenbank aktualisieren
Diese Methode kann leicht eliminiert werden, denn wenn der Cache zuerst erfolgreich aktualisiert wird, die Datenbankaktualisierung jedoch fehlschlägt, führt dies definitiv zu Dateninkonsistenzen.
Option 2: Datenbank aktualisieren und Cache aktualisieren
Diese Cache-Aktualisierungsstrategie wird allgemein als Double-Write bezeichnet. Das Problem ist: Im Szenario gleichzeitiger Datenbankaktualisierungen werden fehlerhafte Daten in den Cache geleert
updateDB(); updateRedis();
Für Beispiel: Wenn zwischen zwei Vorgängen die Datenbank und der Cache durch nachfolgende Anforderungen geändert werden, werden beim Aktualisieren des Caches bereits abgelaufene Daten angezeigt.

Option 3: Cache löschen und Datenbank aktualisieren
Problem: Vor dem Aktualisieren der Datenbank werden bei einer Abfrageanforderung fehlerhafte Daten in den Cache geleert
deleteRedis(); updateDB();
Beispiel: Wenn zwischen zwei Vorgängen Bei einer Datenabfrage werden alte Daten im Cache abgelegt.

Diese Lösung führt zu inkonsistenten Anforderungsdaten
Wenn es eine Anforderung A für den Aktualisierungsvorgang und eine andere Anforderung B für den Abfragevorgang gibt. Dann tritt die folgende Situation auf:
Fordern Sie A auf, einen Schreibvorgang durchzuführen und den Cache zu löschen.
Fordern Sie B auf, eine Abfrage durchzuführen und festzustellen, dass der Cache nicht vorhanden ist.
Fordern Sie B auf, die Datenbank abzufragen, um sie abzurufen der alte Wert
Anforderung B, den alten Wert zu ändern Cache schreiben
Anforderung A, neue Werte in die Datenbank zu schreiben
Die obige Situation führt zu Inkonsistenzen. Wenn Sie außerdem keine Ablaufzeitstrategie für den Cache festlegen, handelt es sich bei den Daten immer um fehlerhafte Daten.
Option 4: Datenbank aktualisieren und Cache löschen
Es liegt ein Problem vor: Vor dem Aktualisieren der Datenbank liegt eine Abfrageanforderung vor und der Cache ist ungültig. Die Datenbank wird abgefragt und dann wird der Cache aktualisiert . Wenn zwischen der Abfrage der Datenbank und der Aktualisierung des Caches ein Datenbankaktualisierungsvorgang durchgeführt wird, werden die fehlerhaften Daten in den Cache geleert in den Cache und löschen Sie den Cache, dann werden alte Daten in den Cache gestellt.
Angenommen, es gibt zwei Anforderungen, eine fordert A auf, einen Abfragevorgang auszuführen, und die andere fordert B auf, einen Aktualisierungsvorgang auszuführen. Dann tritt die folgende Situation auf: Der Cache läuft gerade ab. Anforderung Wenn A die Datenbank abfragt, wird ein alter Wert angezeigt. Der Wert
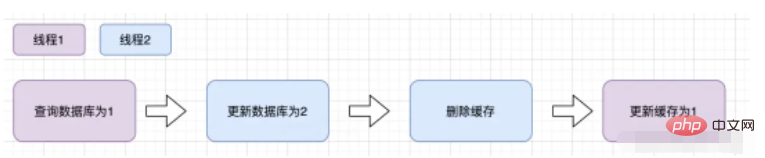
fordert B auf, den neuen Wert in die Datenbank zu schreiben Cache
Wenn die obige Situation auftritt, werden die Daten tatsächlich verschmutzt. Es gibt jedoch eine angeborene Bedingung für das Eintreten der oben genannten Situation, nämlich dass das Schreiben einer Datenbankoperation weniger Zeit in Anspruch nimmt als das Lesen einer Datenbankoperation. Allerdings ist die Geschwindigkeit von Datenbankleseoperationen viel schneller als die von Schreiboperationen, weshalb diese Situation vorliegt ist schwer möglich.
Vergleich der Pläne- Gemeinsame Mängel von Plan 1 und Plan 2:
Im Szenario der gleichzeitigen Aktualisierung der Datenbank werden fehlerhafte Daten in den Cache geleert, aber im Allgemeinen ist die Wahrscheinlichkeit des gleichzeitigen Schreibens relativ gering ;
Thread-Sicherheitsperspektive erzeugt schmutzige Daten, wie zum Beispiel: - Thread A hat die Datenbank aktualisiert
- Thread B hat die Datenbank aktualisiert
Thread B hat den Cache aktualisiert
Thread A hat die aktualisiert Cache
Schema Gemeinsame Mängel der Optionen 3 und 4:
Unabhängig davon, welche Reihenfolge übernommen wird, gibt es bei beiden Methoden einige Probleme:
- Master-Slave-Verzögerungsproblem: Ob es zuerst gelöscht oder gelöscht wird Später kann die Master-Slave-Verzögerung der Datenbank zur Erzeugung schmutziger Daten führen.
- Fehler beim Löschen des Caches: Wenn das Löschen des Caches fehlschlägt, werden fehlerhafte Daten generiert.
- Ideen zur Problemlösung: Doppeltes Löschen verzögern und einen Wiederholungsmechanismus hinzufügen, der unten vorgestellt wird!
- Cache aktualisieren oder Cache löschen?
- 1. Das Aktualisieren des Caches erfordert einen gewissen Wartungsaufwand und es treten Probleme bei gleichzeitigen Aktualisierungen auf.
2. Wenn viele Schreibvorgänge und wenige Lesevorgänge vorliegen, ist die Leseanforderung noch nicht eingegangen wurde viele Male aktualisiert und spielt keine Rolle beim Caching. 3. Der im Cache abgelegte Wert kann komplex berechnet werden
- Vorteile des Cache-Löschens:
- Einfach, kostengünstig, leicht zu entwickeln; Nachteile: Es führt zu einem Cache-Fehler. Wenn die Kosten für die Aktualisierung des Caches gering sind und es mehr Lesevorgänge und weniger Schreibvorgänge gibt Da es grundsätzlich keine Schreibparallelität gibt, können Sie den Cache aktualisieren. Andernfalls besteht die übliche Vorgehensweise darin, den Cache zu löschen.
总结
| 方案 | 问题 | 问题出现概率 | 推荐程度 |
|---|---|---|---|
| 更新缓存 -> 更新数据库 | 为了保证数据准确性,数据必须以数据库更新结果为准,所以该方案绝不可行 | 大 | 不推荐 |
| 更新数据库 -> 更新缓存 | 并发更新数据库场景下,会将脏数据刷到缓存 | 并发写场景,概率一般 | 写请求较多时会出现不一致问题,不推荐使用。 |
| 删除缓存 -> 更新数据库 | 更新数据库之前,若有查询请求,会将脏数据刷到缓存 | 并发读场景,概率较大 | 读请求较多时会出现不一致问题,不推荐使用 |
| 更新数据库 -> 删除缓存 | 在更新数据库之前有查询请求,并且缓存失效了,会查询数据库,然后更新缓存。如果在查询数据库和更新缓存之间进行了数据库更新的操作,那么就会把脏数据刷到缓存 | 并发读场景&读操作慢于写操作,概率最小 | 读操作比写操作更慢的情况较少,相比于其他方式出错的概率小一些。勉强推荐。 |
推荐方案
延迟双删
采用更新前后双删除缓存策略
public void write(String key,Object data){
redis.del(key);
db.update(data);
Thread.sleep(1000);
redis.del(key);
}先淘汰缓存
再写数据库
休眠1秒,再次淘汰缓存
大家应该评估自己的项目的读数据业务逻辑的耗时。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上即可。
这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
问题及解法:
1、同步删除,吞吐量降低如何处理
将第二次删除作为异步的,提交一个延迟的执行任务
2、解决删除失败的方式:
添加重试机制,例如:将删除失败的key,写入消息队列;但对业务耦合有些严重;
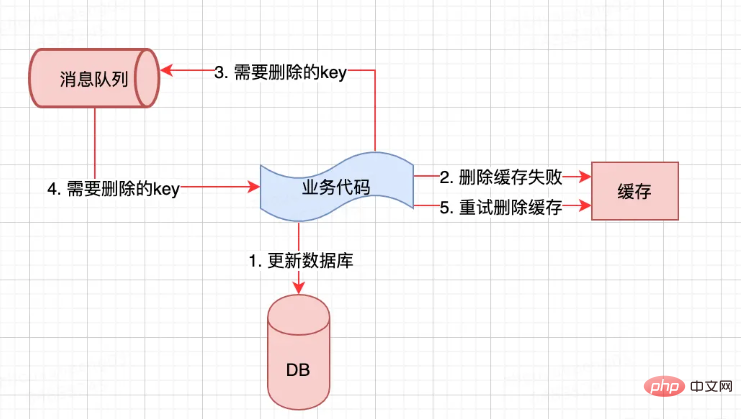
延时工具可以选择:
最普通的阻塞Thread.currentThread().sleep(1000);
Jdk调度线程池,quartz定时任务,利用jdk自带的delayQueue,netty的HashWheelTimer,Rabbitmq的延时队列,等等
实际场景
我们有个商品中心的场景,是读多写少的服务,并且写数据会发送MQ通知下游拿数据,这样就需要严格保证缓存和数据库的一致性,需要提供高可靠的系统服务能力。
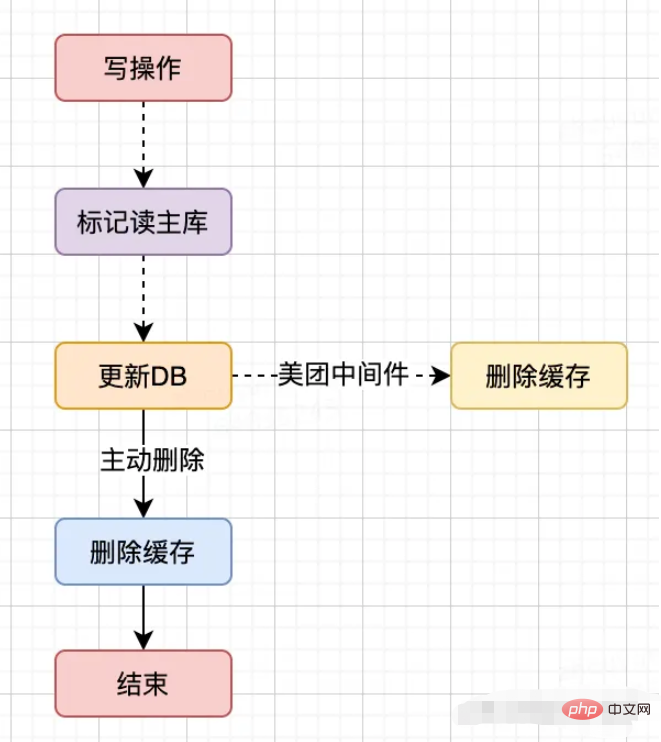
写缓存策略
缓存key设置失效时间
先DB操作,再缓存失效
写操作都标记key(美团中间件)强制走主库
接入美团中间件监听binlog(美团中间件)变化的数据在进行兜底,再删除缓存
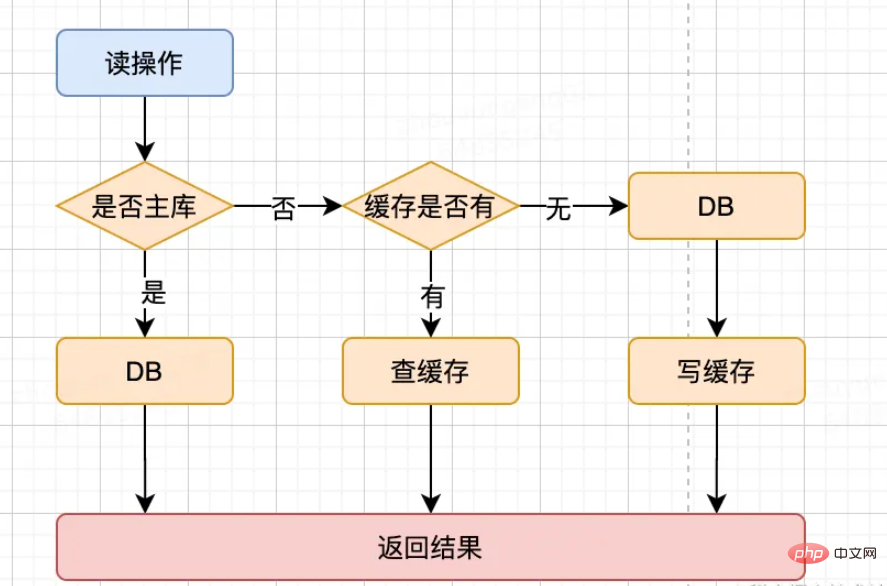
读缓存策略
先判断是否走主库
如果走主库,则使用标记(美团中间件)查主库
如果不是,则查看缓存中是否有数据
缓存中有数据,则使用缓存数据作为结果
如果没有,则查DB数据,再写数据到缓存
注意
关于缓存过期时间的问题
如果缓存设置了过期时间,那么上述的所有不一致情况都只是暂时的。
但是如果没有设置过期时间,那么不一致问题就只能等到下次更新数据时解决。
所以一定要设置缓存过期时间。
Das obige ist der detaillierte Inhalt vonSo stellen Sie die Cache-Konsistenz in Java sicher. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!