
Heim >Java >javaLernprogramm >Was ist der Grund, warum Java keine Nicht-Text-Binärdateien mithilfe von Zeichenströmen lesen kann?
Was ist der Grund, warum Java keine Nicht-Text-Binärdateien mithilfe von Zeichenströmen lesen kann?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-30 15:34:14883Durchsuche
Dateien lesen
Als ich zum ersten Mal den IO-Stream-Teil von Java lernte, stand im Buch, dass nur Byte-Streams zum Lesen von Nicht-Text-Binärdateien wie Bildern und Videos sowie Zeichen verwendet werden können Streams können nicht verwendet werden. Andernfalls wird die Datei beschädigt. Ich habe mich also immer daran erinnert, aber warum es nicht verwendet werden kann, war für mich immer ein Zweifel. Heute habe ich noch einmal über dieses Problem nachgedacht, also könnte ich es genauso gut auf einmal lösen.
Sehen wir uns zunächst ein Codebeispiel zum Kopieren von Bildern an: Hinweis: Mein Computer hat den Pfad D:/DB. Wenn Sie keinen DB-Ordner haben, müssen Sie einen erstellen. .
package dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.nio.file.Path;
import java.nio.file.Paths;
public class ReadImage {
public static void main(String[] args) throws IOException {
String imgPath = "D:/DB/husky/kkk.jpeg";
String byteImgCopyPath = "D:/DB/husky/byteCopykkk.jpeg";
String charImgCopyPath = "D:/DB/husky/charCopykkk.jpeg";
Path srcPath = Paths.get(imgPath);
Path desPath2 = Paths.get(byteImgCopyPath);
Path desPath3 = Paths.get(charImgCopyPath);
byteRead(srcPath.toFile(), desPath2.toFile());
System.out.println("字节复制执行成功!");
characterRead(srcPath.toFile(), desPath3.toFile());
System.out.println("字符复制执行成功!");
}
static void byteRead(File src, File des) throws IOException {
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream(src));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(des))) {
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
bos.write(b, 0, hasRead);
}
}
}
static void characterRead(File src, File des) throws IOException {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(src), "UTF-8"));
BufferedWriter writer = new BufferedWriter(new FileWriter(des))) {
int hasRead = 0;
char[] c = new char[1024];
while ((hasRead = reader.read(c)) != -1) {
writer.write(c, 0, hasRead);
}
}
}
}Laufende Ergebnisse: Es ist ersichtlich, dass Binärdateien wie Bilder nicht mit Zeichenströmen gelesen werden können, Byteströme jedoch müssen gebraucht.

Bildgröße ändert sich: Es ist zu erkennen, dass sich die Bildgröße geändert hat Nach der Verwendung von Zeichenströmen ist die Verwendung von Byteströmen nicht mehr möglich.

Warum ist das so?
Anhand des obigen Beispiels können wir sehen, dass es tatsächlich unmöglich ist, Dateien mithilfe von Zeichenströmen zu kopieren. Nach der Verwendung von Zeichenströmen zum Kopieren von Dateien ändert sich auch die Größe der Dateien, was dazu führt Titel, den wir heute besprechen werden.
Überlegen wir uns zunächst, warum beim Öffnen einer Textdatei Text angezeigt werden kann? Wir alle wissen, dass die von Computern verarbeiteten Dateien, egal ob Text- oder Nicht-Textdateien, letztendlich in binärer Form im Computer gespeichert werden.
Öffnen Sie eine Textdatei im Hexadezimalmodus des Texteditors:
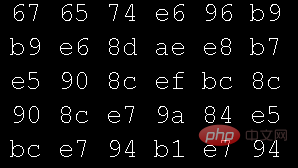
# 🎜🎜#Verwenden Sie den Hexadezimalmodus des Editors, um die vom oben genannten Programm verwendete Bilddatei zu öffnen:
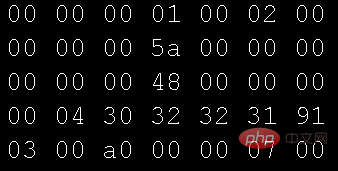
Character Encoding Table. Ich habe zum ersten Mal die Sprache C gelernt und die erste Codierungstabelle, mit der ich in Kontakt kam, war ASCII (American Standard Code for Information Interchange). Später, als ich Java lernte, kam ich mit Unicode (Universal Code) in Kontakt sein Ursprung. Die derzeit am häufigsten verwendete ist UTF-8, eine Zeichenkodierung mit variabler Länge für Unicode UTF-8 ist außerdem in BOM ( Byte Order Mark (Byte Order Mark) und Nr. zwei Formen unterteilt, und das Mischen dieser beiden Formen führt zu Fehlern. Wenn Sie interessiert sind, können Sie sich darüber informieren.
Die Rolle der Zeichenkodierungstabelle spiegelt sich in der Kodierung wider und zitiert eine Passage aus der Enzyklopädie: #🎜 🎜##🎜 🎜#Die Texte, Bilder und anderen Informationen, die wir auf dem Monitor sehen, sind nicht wirklich das, was wir im Computer sehen. Selbst wenn Sie wissen, dass alle Informationen auf der Festplatte gespeichert sind, können Sie darin nichts sehen Wenn man es auseinandernimmt, sind nur noch ein paar Scheiben übrig. Angenommen, Sie verwenden ein Mikroskop, um die Scheibe zu vergrößern, und Sie werden sehen, dass die Oberfläche der Scheibe uneben ist. Die konvexen Stellen sind magnetisiert, die konvexen Stellen stellen die Zahl 1 dar, und die konkaven Stellen stellen die Zahl 1 dar die Zahl 0. Die Festplatte kann nur 0 und 1 verwenden, um alle Texte, Bilder und anderen Informationen darzustellen. Wie wird also der Buchstabe „A“ auf der Festplatte gespeichert? Möglicherweise speichert Xiao Zhangs Computer den Buchstaben „A“ als 1100001, während Xiao Wangs Computer den Buchstaben „A“ als 11000010 speichert. Auf diese Weise werden die beiden Parteien beim Informationsaustausch missverstanden. Zum Beispiel hat Xiao Zhang 1100001 an Xiao Wang gesendet. Xiao Wang glaubte nicht, dass 1100001 der Buchstabe „A“ sei, sondern dachte wahrscheinlich, dass es sich um den Buchstaben „X“ handelte, als Xiao Wang Notepad verwendete, um auf die auf der Festplatte gespeicherte 1100001 zuzugreifen , erscheint eine Fehlermeldung auf dem Bildschirm. Es wird der Buchstabe „X“ angezeigt. Mit anderen Worten: Xiao Zhang und Xiao Wang verwendeten unterschiedliche Codierungstabellen.
 Die
Die
, zum Beispiel steht 65 (Zahl) für A, also Der folgende Code gibt A auf dem Bildschirm aus.
char c = 65; System.out.println(c);
Wir verwenden eine Schleife, um es zu testen: char c = 0;
for (int i = 9999; i < 10009; i++) {
c = (char) i;
System.out.print(c+" ");
}Testergebnis: (Natürlich hängt dies von Ihrer aktuellen Zeichenkodierungstabelle ab. Wenn Sie ASCII verwenden, wird es geschätzt das Interessant. )
这样就解释了前面那个问题(为什么文本文件打开可以显示文字?),我们之所以可以看见文本文件的字符是因为计算机按照我们文件的编码(ASCII、UTF-8或者GBK等),从字符编码表中找出来对应的字符。 所以,当我们使用记事本打开二进制文件会看到乱码,这就是原因。文件的复制过程也是复制的二进制数据,而不是真实的文字。
因此可以这样理解文件复制的过程:
字符流:二进制数据 --编码-> 字符编码表 --解码-> 二进制数据
字节流:二进制数据 —> 二进制数据
所以问题就是出现在编码和解码的过程中,既然是字符的编码表,那它就是包含所有的字符,但是字符的数量是有限的,这就意味着它不能表示一些超过编码表的字符,因为根本不存在表中。所以,JVM 会使用一些字符进行替换,基本上都是乱码(所以大小会发生变化),而且如果有一个数据恰好是-1,那么读取就会中断,引起数据丢失。
例如如下代码使用字符流读取就会错误:
String filename = "D:/DB/fos.txt"; //文件名
byte[] b = new byte[] {-1, -1}; //两个字节,127的二进制就是 1111 1111
//数据写入文件
try (FileOutputStream fos = new FileOutputStream(filename)) {
fos.write(b, 0, b.length); //将两个127连续写入,就是 1111 1111 1111 1111
}
File file = new File(filename);
//输出文件的大小
System.out.println("file length: " + file.length());
char[] c = new char[2];
//使用字符流读取文件
try (FileReader reader = new FileReader(filename)) {
int count = reader.read(c); //Java使用Unicode编码,读取的是从 0-65535 之间的数字。
System.out.println("以文本形式输出:" + new String(c, 0, count)+" "+count);
for (char d : c) {
System.out.println("字符为:" + d);
}
}
System.out.println("表示字符:" + c[0]);
//再写入文件
try (FileWriter writer = new FileWriter(filename)) {
writer.write(c, 0, 2);
}
File f = new File(filename);
System.out.println("file length: " + f.length());结果:

说明: 我将两个1字节的-1写入(字节流)了文本文件(注意是字节:-1,不是字符:-1),然后再读取(字符流),再写入(字符流)就已经出现了问题。读取出的字符显示了一个奇怪的符号,而且它的值为:65533,这个值如果用字节表示的话,一个字节是不够的,所以文件的大小就会变化。在非文本的二进制数据中,出现这种情况都是正常的,因为本来就不是按照字符编码的。
因为字符都是正数,而非字符编码的话,字节数可能是负数(很可能),但是负数在字符看来就是正数,这也是为什么-1,被读成 65533的原因。可以看出来,读取就已经错误了。
注意: 这里的重点是对于使用字符流读取非文本文件,在读取-写入的过程中的问题。
Das obige ist der detaillierte Inhalt vonWas ist der Grund, warum Java keine Nicht-Text-Binärdateien mithilfe von Zeichenströmen lesen kann?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!