
Heim >Java >javaLernprogramm >Was sind die Grundkenntnisse des zugrunde liegenden Java-Betriebssystems und der Parallelität?
Was sind die Grundkenntnisse des zugrunde liegenden Java-Betriebssystems und der Parallelität?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-29 21:25:061103Durchsuche
1. Moderne Computer-Hardwarestruktur
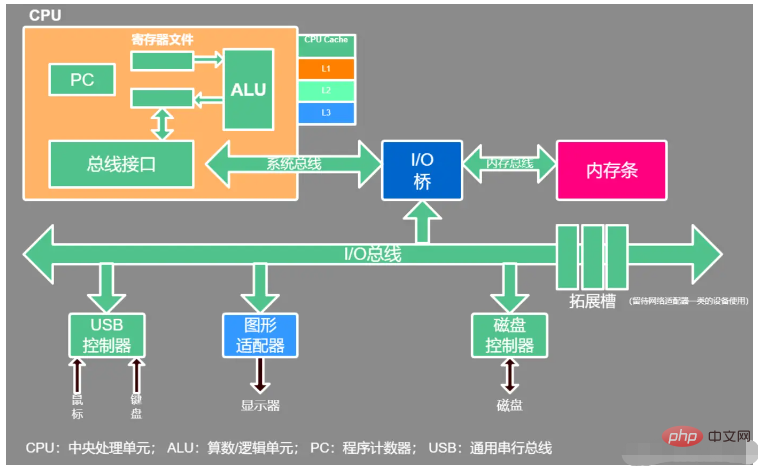
Kernteil: CPU, Speicher
1.CPU-interne Struktur
Steuereinheit: Befehls- und Kontrollzentrum der gesamten CPU
-
Recheneinheit: Rechnerkern, führt arithmetische Operationen und logische Operationen aus. Die Recheneinheit empfängt Anweisungen von der Steuereinheit und führt Aktionen aus 1.1.CPU-Cache-Struktur
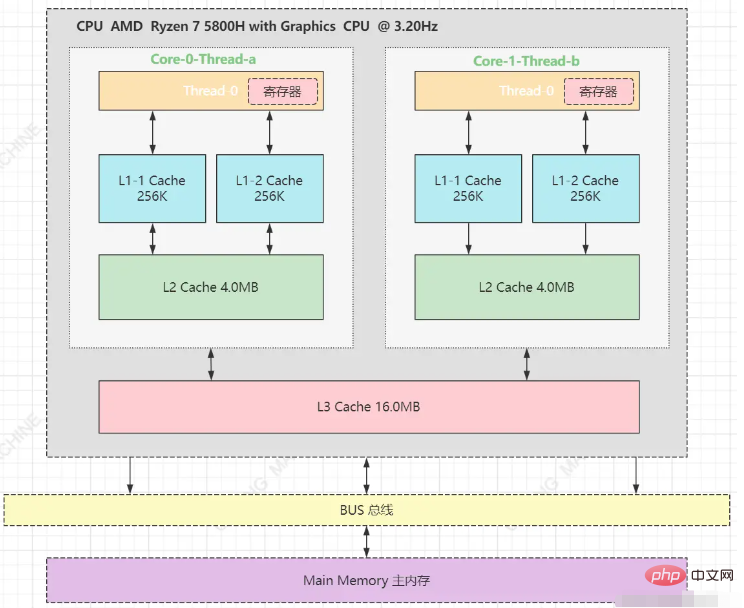
Um die Ausführungseffizienz zu verbessern und die Interaktion zwischen CPU und Speicher zu reduzieren (Interaktion beeinflusst die CPU-Effizienz), integrieren moderne CPUs im Allgemeinen eine mehrstufige Cache-Architektur auf der CPU. Am häufigsten ist die dritte Ebene Cache-Struktur L1-Cache, der in Daten-Cache und Befehlscache unterteilt ist, logischer Kern exklusivL2-Cache, physischer Kern exklusiv, logischer Kern gemeinsam genutzt
L3-Cache, alle physischen Kerne gemeinsam genutzt
- Die dreistufige Cache-Architektur dieser Maschine sieht wie folgt aus: Der L1-Cache ist in zwei Typen unterteilt: Befehlsspeichereinheit (Speicheranweisungen) und logische Speichereinheit (Speicherlogik). Theoretisch kann eine Maschine mehrere CPUs haben, abhängig von den Steckplätzen. Eine CPU kann mehrere Kerne haben und ein Kern kann mehrere logische Prozessoren haben.
- Register
- ist eine interne Komponente der CPU und verfügt über sehr schnelle Lese- und Schreibgeschwindigkeiten.
Die CPU liest nur Daten aus dem Register. Jede CPU verfügt über ein eindeutiges Register, auf das andere CPUs nicht zugreifen können.
Durch die Verwendung von Registern kann die Anzahl der Zugriffe der CPU auf den Speicher reduziert und so die Arbeitsgeschwindigkeit der CPU erhöht werden.
 Je näher an der CPU, desto schneller ist die Lesegeschwindigkeit
Je näher an der CPU, desto schneller ist die Lesegeschwindigkeit
Speicherlesegeschwindigkeit: Register > L2 Cache > > Der Speicher
Cache besteht aus dem kleinsten Speicherblock –
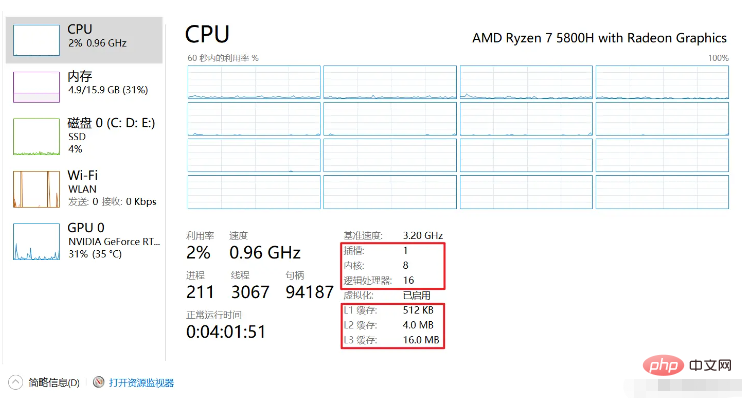
Cache-Zeile (CacheLine). Die Größe der Cache-Zeile beträgt normalerweise 64 Byte. Die Cache-Größe meines Computers L1 beträgt 512 KB und besteht aus 512 * 1024/64 Cache-Zeilen.
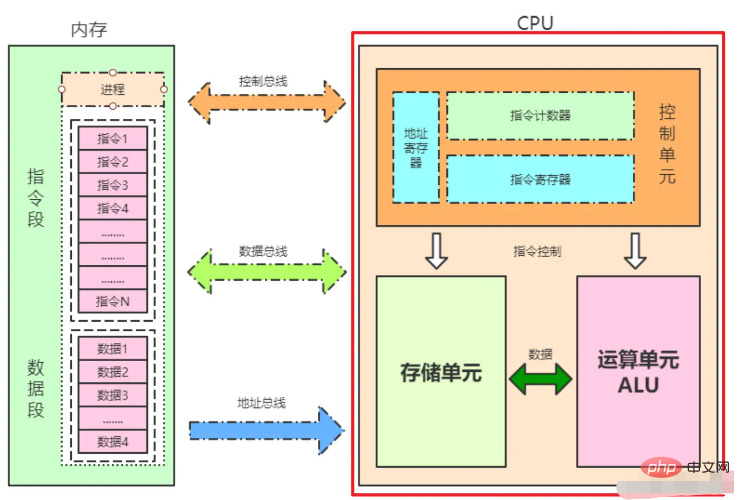
CPU-Lesespeicherdatenprozess:
- CPU kann Daten nur direkt aus Registern abrufen.
Unter der Annahme, dass sich Daten x = 0 im Speicher befinden, ist der Wertprozess wie folgt:
Bestimmen Sie, ob sie im Register vorhanden sind.- Wenn sie nicht vorhanden sind, durchsuchen Sie den L1-Cache, um zu sehen, ob sie vorhanden sind Existiert, durchqueren Sie den L2-Cache. Wenn er nicht im L2-Cache vorhanden ist, durchqueren Sie den L3-Cache. Wenn ein Zwischenprozess vorhanden ist, wird die Cache-Zeile gesperrt und auf die obere Ebene kopiert, bis sie das Register erreicht.
Lokalitätsprinzip: Wenn die CPU auf das Speichergerät zugreift, werden diese in der Regel in einem kontinuierlichen Bereich gesammelt, unabhängig davon, ob sie auf Daten zugreift oder auf Anweisungen zugreift.Wenn es nicht im Cache gefunden wird, wird es im Speicher gesucht. Zuerst wird der Speichercontroller benachrichtigt, die Busbandbreite zu belegen, der Speicher wird gesperrt, eine Speicherleseanforderung wird initiiert, auf die Antwort gewartet Kopieren Sie die Antwortdaten in den L3-Cache. Hinweis: Der gesamte Prozess ist gesperrt, bis die CPU entsperrt wird.
Es gibt zwei Arten von Lokalitätsprinzipien:
Temporale Lokalität:Wenn auf einen Speicherort verwiesen wird, dann werden in Zukunft auch die Orte in seiner Nähe referenziert. Zum Beispiel sequentiell ausgeführter Code, zwei kontinuierlich erstellte Objekte, Arrays usw.Wenn auf ein Informationselement zugegriffen wird, ist es wahrscheinlich, dass in naher Zukunft erneut darauf zugegriffen wird. Zum Beispiel Schleifen, Rekursion, wiederholte Aufrufe von Methoden usw.
Räumliche Lokalität:
Beispiel für räumliche Lokalität:
Bei einem großen zweidimensionalen Array ist das Akkumulieren und Summieren Zeile für Zeile viel schneller als das Akkumulieren Spalte für Spalte. Wenn die CPU Daten im Speicher liest, werden alle angehängten Daten eingelesen.- 1.2. CPU-Betriebssicherheitsstufe
CPU ist in 4 Betriebsstufen unterteilt:
ring0
Kernel-Modus
ring1
ring2
ring3 #🎜 🎜# Benutzermodus
ring0, ring3#🎜 🎜# , Interne Programmanweisungen innerhalb des Betriebssystems werden normalerweise auf der Ring0-Ebene ausgeführt, und Programme von Drittanbietern außerhalb des Betriebssystems werden auf der Ring3-Ebene ausgeführt. Wenn ein Drittanbieterprogramm die interne Funktion des Betriebssystems aufrufen möchte, muss der CPU-Ausführungsstatus vorliegen aufgrund unzureichender Betriebssicherheitsstufe umgeschaltet werden, von Ring3 zu Ring0 wechseln und dann Systemfunktionen ausführen und Threads erstellen, sind schwere Vorgänge, da die CPU den Betriebszustand wechseln muss.
JVM-Thread-Erstellung ist der Prozess der CPU:
Schritt 1: CPU Startet von Ring3, wechselt Ring0 und erstellt einen Thread
. Nehmen Sie als Beispiel den 4G-Speicherplatz eines 32-Bit-Betriebssystems:- Schritt 2: Nach der Erstellung wechselt die CPU von Ring0 zurück zu Ring3
#🎜🎜 #
Schritt 3: Der Thread führt das JVM-Programm aus- Schritt 4: Nachdem der Thread ausgeführt wurde, wird er zerstört und wieder auf ring0 umgeschaltet#🎜🎜 #
- #🎜 🎜#Schritt 5: Der Thread wird zerstört und wieder auf Ring3 umgeschaltet
- Damit das Programm Sicherheitsisolation und Stabilität gewährleistet, verfügt das Betriebssystem über zwei Konzepte
2 Verwaltung
用户空间与内核空间Linux reserviert mehrere Seitenrahmen für Kernelcode und Datenstrukturen Nie auf die Festplatte übertragen (4 GB Speicherplatz, 3 GB für Benutzerprogramme verfügbar). Wie in der Abbildung gezeigt, kann auf die lineare Adresse im grünen Teil durch
verwiesen werden (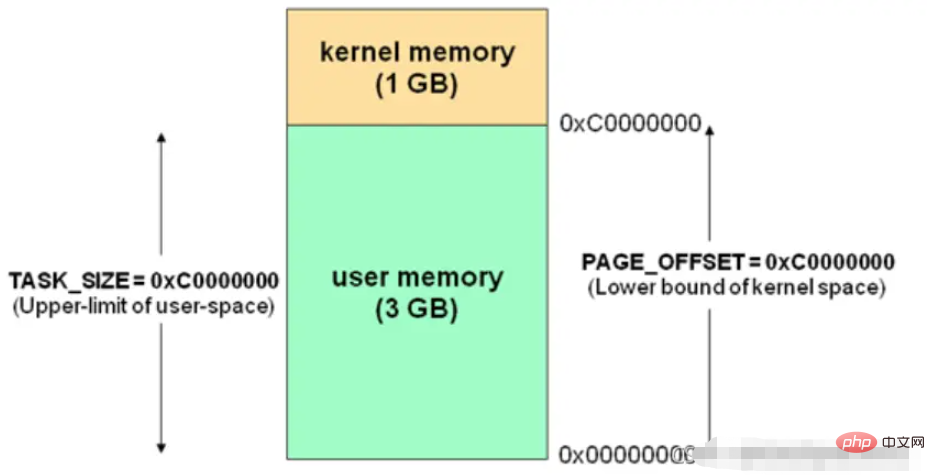 ist Benutzerraum
ist Benutzerraum
im gelben Teil kann nur über den Kernelcode zugegriffen werden ( ist der Kernelraum ). Prozesse und Threads können nur im Benutzermodus oder Kernelmodus
ausgeführt werden. Benutzerprogramme werden im Benutzermodus ausgeführt, während Systemaufrufe im Kernelmodus ausgeführt werden.Verwenden Sie im Benutzermodus einen allgemeinen Stapel (Benutzerraumstapel), im Kernelmodus einen Stapel fester Größe (Kernelraumstapel, im Allgemeinen die Größe einer Speicherseite), dh jeden Prozess und jeden Thread haben tatsächlich zwei Stacks, die jeweils im Benutzermodus und im Kernelmodus
ausgeführt werden.Der Basiseinheiten-Thread der CPU-Planung ist auch unterteilt in:
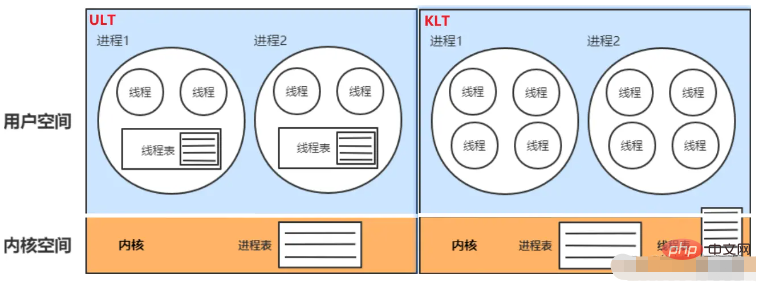
Kernel-Thread Modell (KLT):
Unter Verwendung von Java speichert der Kernel die Status- und Kontextinformationen des Threads, und das Blockieren von Threads führt nicht zu einer Prozessblockierung. Auf Multiprozessorsystemen laufen mehrere Threads parallel auf mehreren Prozessoren. Die Erstellung, Planung und Verwaltung von Threads wird vom Kernel abgeschlossen, und die Effizienz ist langsamer als bei ULT und schneller als bei Prozessvorgängen.-
Benutzer-Thread-Modell (ULT):
Verlässt sich nicht auf den Betriebssystemkern. Die Anwendung bietet Funktionen zum Erstellen, Synchronisieren und Planen und verwalten Sie Threads. Es ist kein Wechsel zwischen Benutzermodus und Kernelmodus erforderlich und die Geschwindigkeit ist hoch. Der Kernel kennt ULT nicht. Wenn ein Thread blockiert ist, wird der Prozess (einschließlich aller seiner Threads) blockiert. Es gibt zwei Stapel, einen im Benutzerbereich und einen im Kernelbereich. Durch das Blockieren, Erstellen und Beenden von Threads wird der Benutzerbereichsstapel verlassen und in den Kernelbereich übertragen. Nach Abschluss der Ausführung wird er dann in den Benutzerbereich übertragen. - 3. Prozesse und Threads
Prozess:
Die kleinste Einheit der Ressourcenzuweisung des Betriebssystems
Die kleinste Einheit der Betriebssystemplanungs-CPU
. Threads haben ihre eigenen Attribute wie Zähler, Stapel und lokale Variablen und kann auf gemeinsam genutzte Speichervariablen zugreifen. Die CPU wechselt mit hoher Geschwindigkeit zwischen diesen Threads, sodass Benutzer das Gefühl haben, dass diese Threads gleichzeitig ausgeführt werden (Parallelität).
Threads nach oben und unten wechseln: Speichern Sie den Zwischenzustand des vorherigen laufenden Threads und führen Sie den nächsten Thread aus
#🎜 🎜## 🎜🎜#Seriell: Keine zeitliche Überlappung, die vorherige Aufgabe ist nicht abgeschlossen, die nächste Aufgabe kann nur warten
#🎜🎜 #Parallel: Zeitlich überlappend werden zwei Aufgaben gleichzeitig ausgeführt, ohne sich gegenseitig zu stören
 #🎜🎜 ## 🎜🎜#Parallelität:
#🎜🎜 ## 🎜🎜#Parallelität:
Das obige ist der detaillierte Inhalt vonWas sind die Grundkenntnisse des zugrunde liegenden Java-Betriebssystems und der Parallelität?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!