
Heim >Backend-Entwicklung >Python-Tutorial >So lösen Sie das Thread-Pool-Problem von Pythons ThreadPoolExecutor
So lösen Sie das Thread-Pool-Problem von Pythons ThreadPoolExecutor

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-28 22:40:201926Durchsuche
Concept
Python verfügt bereits über das threading-Modul. Warum benötigen Sie einen Thread-Pool? Python中已经有了threading模块,为什么还需要线程池呢,线程池又是什么东西呢?
以爬虫为例,需要控制同时爬取的线程数,例子中创建了20个线程,而同时只允许3个线程在运行,但是20个线程都需要创建和销毁,线程的创建是需要消耗系统资源的,有没有更好的方案呢?
其实只需要三个线程就行了,每个线程各分配一个任务,剩下的任务排队等待,当某个线程完成了任务的时候,排队任务就可以安排给这个线程继续执行。
这就是线程池的思想(当然没这么简单),但是自己编写线程池很难写的比较完美,还需要考虑复杂情况下的线程同步,很容易发生死锁。
从Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对threading和multiprocessing的进一步抽象(这里主要关注线程池),不仅可以帮我们自动调度线程,还可以做到:
主线程可以获取某一个线程(或者任务的)的状态,以及返回值。
当一个线程完成的时候,主线程能够立即知道。
让多线程和多进程的编码接口一致。
实例
简单使用
from concurrent.futures import ThreadPoolExecutor
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
# 通过submit函数提交执行的函数到线程池中,submit函数立即返回,不阻塞
task1 = executor.submit(get_html, (3))
task2 = executor.submit(get_html, (2))
# done方法用于判定某个任务是否完成
print(task1.done())
# cancel方法用于取消某个任务,该任务没有放入线程池中才能取消成功
print(task2.cancel())
time.sleep(4)
print(task1.done())
# result方法可以获取task的执行结果
print(task1.result())
# 执行结果
# False # 表明task1未执行完成
# False # 表明task2取消失败,因为已经放入了线程池中
# get page 2s finished
# get page 3s finished
# True # 由于在get page 3s finished之后才打印,所以此时task1必然完成了
# 3 # 得到task1的任务返回值ThreadPoolExecutor构造实例的时候,传入max_workers参数来设置线程池中最多能同时运行的线程数目。
使用submit函数来提交线程需要执行的任务(函数名和参数)到线程池中,并返回该任务的句柄(类似于文件、画图),注意submit()不是阻塞的,而是立即返回。
通过submit函数返回的任务句柄,能够使用done()方法判断该任务是否结束。上面的例子可以看出,由于任务有2s的延时,在task1提交后立刻判断,task1还未完成,而在延时4s之后判断,task1就完成了。
使用cancel()方法可以取消提交的任务,如果任务已经在线程池中运行了,就取消不了。这个例子中,线程池的大小设置为2,任务已经在运行了,所以取消失败。如果改变线程池的大小为1,那么先提交的是task1,task2还在排队等候,这是时候就可以成功取消。
使用result()方法可以获取任务的返回值。查看内部代码,发现这个方法是阻塞的。
as_completed
上面虽然提供了判断任务是否结束的方法,但是不能在主线程中一直判断啊。
有时候我们是得知某个任务结束了,就去获取结果,而不是一直判断每个任务有没有结束。
这是就可以使用as_completed方法一次取出所有任务的结果。
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
all_task = [executor.submit(get_html, (url)) for url in urls]
for future in as_completed(all_task):
data = future.result()
print("in main: get page {}s success".format(data))
# 执行结果
# get page 2s finished
# in main: get page 2s success
# get page 3s finished
# in main: get page 3s success
# get page 4s finished
# in main: get page 4s successas_completed()方法是一个生成器,在没有任务完成的时候,会阻塞,在有某个任务完成的时候,会yield这个任务,就能执行for循环下面的语句,然后继续阻塞住,循环到所有的任务结束。
从结果也可以看出,先完成的任务会先通知主线程。
map
除了上面的as_completed方法,还可以使用executor.map方法,但是有一点不同。
from concurrent.futures import ThreadPoolExecutor
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
for data in executor.map(get_html, urls):
print("in main: get page {}s success".format(data))
# 执行结果
# get page 2s finished
# get page 3s finished
# in main: get page 3s success
# in main: get page 2s success
# get page 4s finished
# in main: get page 4s success使用map方法,无需提前使用submit方法,map方法与python标准库中的map含义相同,都是将序列中的每个元素都执行同一个函数。
上面的代码就是对urls的每个元素都执行get_html函数,并分配各线程池。可以看到执行结果与上面的as_completed方法的结果不同,输出顺序和urls列表的顺序相同,就算2s的任务先执行完成,也会先打印出3s的任务先完成,再打印2s的任务完成。
wait
wait方法可以让主线程阻塞,直到满足设定的要求。
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED, FIRST_COMPLETED
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
all_task = [executor.submit(get_html, (url)) for url in urls]
wait(all_task, return_when=ALL_COMPLETED)
print("main")
# 执行结果
# get page 2s finished
# get page 3s finished
# get page 4s finished
# mainwait方法接收3个参数,等待的任务序列、超时时间以及等待条件。
等待条件return_when默认为ALL_COMPLETED,表明要等待所有的任务都结束。
可以看到运行结果中,确实是所有任务都完成了,主线程才打印出main。
等待条件还可以设置为FIRST_COMPLETED,表示第一个任务完成就停止等待。
源码分析
cocurrent.future模块中的futureNehmen Sie einen Crawler. Sie müssen die Anzahl der gleichzeitig gecrawlten Threads steuern. Im Beispiel werden jedoch nur 3 Threads gleichzeitig ausgeführt Gibt es eine bessere Lösung, um Threads zu erstellen und zu zerstören?
Python3.2 stellt uns die Standardbibliothek das Modul concurrent.futures zur Verfügung, das ThreadPoolExecutor und ProcessPoolExecutorZwei Klassen implementieren eine weitere Abstraktion von <code>threading und multiprocessing (der Schwerpunkt liegt hier auf Thread-Pools). Sie können uns nicht nur dabei helfen, Threads automatisch zu planen, sondern auch: 🎜- 🎜Der Hauptthread kann den Status eines bestimmten Threads (oder einer bestimmten Aufgabe) und den Rückgabewert abrufen. 🎜
- 🎜Wenn ein Thread abgeschlossen ist, kann der Hauptthread dies sofort erfahren. 🎜
- 🎜Machen Sie die Codierungsschnittstelle von Multithread und Multiprozess konsistent. 🎜 🎜🎜Instance🎜
Einfach zu verwenden
rrreee🎜ThreadPoolExecutor Übergeben Sie beim Erstellen einer Instanz den Parameter max_workers, um die maximale Anzahl von Threads festzulegen, die gleichzeitig im Thread-Pool ausgeführt werden können. 🎜🎜Verwenden Sie die Submit-Funktion, um die Aufgabe (Funktionsname und Parameter), die der Thread ausführen muss, an den Thread-Pool zu senden und das Handle der Aufgabe zurückzugeben (ähnlich wie bei Dateien und Zeichnungen). , kehrt aber sofort zurück. 🎜🎜Anhand des von der Submit-Funktion zurückgegebenen Task-Handles können Sie mit der Methode done() feststellen, ob die Aufgabe beendet wurde. Wie aus dem obigen Beispiel ersichtlich ist, wird unmittelbar nach der Übermittlung von Aufgabe 1 beurteilt, dass Aufgabe 1 nicht abgeschlossen wurde, da die Aufgabe eine Verzögerung von 2 Sekunden aufweist. Nach einer Verzögerung von 4 Sekunden wird jedoch beurteilt, dass Aufgabe 1 abgeschlossen ist. 🎜🎜Verwenden Sie die Methode cancel(), um die übermittelte Aufgabe abzubrechen. Wenn die Aufgabe bereits im Thread-Pool ausgeführt wird, kann sie nicht abgebrochen werden. In diesem Beispiel ist die Thread-Pool-Größe auf 2 eingestellt und die Aufgabe wird bereits ausgeführt, sodass der Abbruch fehlschlägt. Wenn Sie die Größe des Thread-Pools auf 1 ändern, wird Aufgabe 1 zuerst übermittelt und Aufgabe 2 wartet noch in der Warteschlange. Zu diesem Zeitpunkt kann sie erfolgreich abgebrochen werden. 🎜🎜Verwenden Sie die Methode result(), um den Rückgabewert der Aufgabe abzurufen. Bei der Betrachtung des internen Codes haben wir festgestellt, dass diese Methode blockiert. 🎜🎜as_completed🎜🎜Obwohl die obige Methode eine Möglichkeit bietet, festzustellen, ob die Aufgabe abgeschlossen ist, kann dies nicht immer im Hauptthread festgestellt werden. 🎜🎜Manchmal, wenn wir wissen, dass eine bestimmte Aufgabe erledigt ist, erhalten wir das Ergebnis, anstatt immer zu beurteilen, ob jede Aufgabe erledigt ist. 🎜🎜Dies ist das Ergebnis der Verwendung der Methodeas_completed zum gleichzeitigen Abrufen aller Aufgaben. 🎜rrreee🎜Die as_completed()-Methode ist ein Generator. Wenn keine Aufgabe abgeschlossen ist, wird sie ausgegeben kann die Anweisungen unterhalb der for-Schleife ausführen und dann weiter blockieren, bis alle Aufgaben abgeschlossen sind. 🎜🎜Aus den Ergebnissen ist auch ersichtlich, dass 🎜die zuerst erledigte Aufgabe zuerst dem Hauptthread mitgeteilt wird🎜. 🎜map
🎜Zusätzlich zur oben genannten Methodeas_completed können Sie auch die Methode executor.map verwenden, es gibt jedoch einen kleinen Unterschied. 🎜rrreee🎜Verwenden Sie die Methode map, ohne zuvor die Methode submit zu verwenden. Die Methode map ist dieselbe wie die Methode pythoncode> Standardbibliothek. code>map hat die gleiche Bedeutung, sie führt die gleiche Funktion für jedes Element in der Sequenz aus. 🎜🎜Der obige Code besteht darin, die Funktion get_html für jedes Element von urls auszuführen und jeden Thread-Pool zuzuweisen. Sie können sehen, dass sich das Ausführungsergebnis vom Ergebnis der obigen Methode as_completed unterscheidet. Die Ausgabereihenfolge ist dieselbe wie die Reihenfolge der 🎜urls🎜list Die 2er-Aufgabe wird zuerst abgeschlossen. Zuerst wird die 3er-Aufgabe gedruckt und dann wird die 2er-Aufgabe gedruckt. 🎜wait
🎜wait-Methode kann den Hauptthread blockieren, bis die festgelegten Anforderungen erfüllt sind. 🎜rrreee🎜Die wait-Methode empfängt 3 Parameter, die Warte-Task-Sequenz, die Timeout-Zeit und die Wartebedingungen. 🎜🎜Die Wartebedingung return_when ist standardmäßig ALL_COMPLETED und zeigt an, dass Sie warten möchten, bis alle Aufgaben beendet sind. 🎜🎜Sie können in den laufenden Ergebnissen sehen, dass alle Aufgaben tatsächlich abgeschlossen sind und der Hauptthread main ausgibt. 🎜🎜Die Wartebedingung kann auch auf FIRST_COMPLETED gesetzt werden, was bedeutet, dass das Warten endet, wenn die erste Aufgabe abgeschlossen ist. 🎜🎜Quellcode-Analyse🎜🎜future im Modul cocurrent.future bedeutet zukünftiges Objekt, das als 🎜eine in der Zukunft abgeschlossene Operation🎜 verstanden werden kann, bei der es sich um asynchrone Grundlagen handelt der Programmierung. 🎜Nach dem Thread-Pool submit() wird das future-Objekt zurückgegeben. Die Aufgabe ist bei der Rückgabe nicht abgeschlossen, wird aber in Zukunft abgeschlossen. submit()之后,返回的就是这个future对象,返回的时候任务并没有完成,但会在将来完成。
也可以称之为task的返回容器,这个里面会存储task的结果和状态。
那ThreadPoolExecutor内部是如何操作这个对象的呢?
下面简单介绍ThreadPoolExecutor的部分代码:
1.init方法
init方法中主要重要的就是任务队列和线程集合,在其他方法中需要使用到。

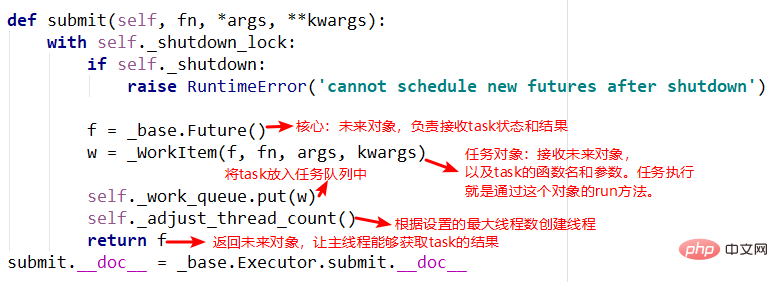
2.submit方法
submit中有两个重要的对象,_base.Future()和_WorkItem()对象,_WorkItem()对象负责运行任务和对future对象进行设置,最后会将future对象返回,可以看到整个过程是立即返回的,没有阻塞。
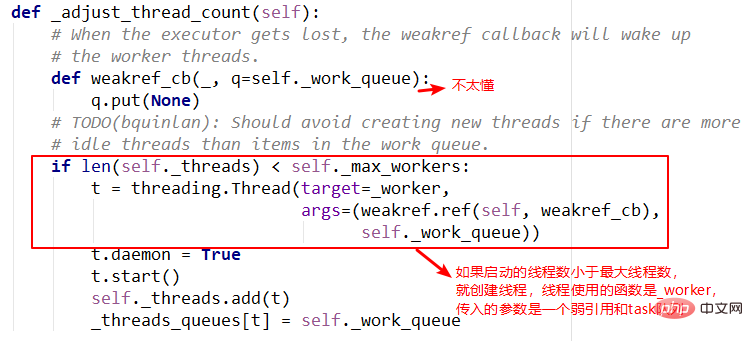
3.adjust_thread_count方法
这个方法的含义很好理解,主要是创建指定的线程数。但是实现上有点难以理解,比如线程执行函数中的weakref.ref,涉及到了弱引用等概念,留待以后理解。
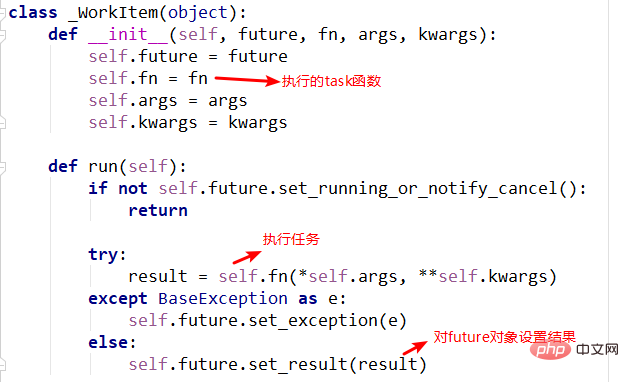
4._WorkItem对象
_WorkItem对象的职责就是执行任务和设置结果。这里面主要复杂的还是self.future.set_result(result) kann auch als Rückgabecontainer der Aufgabe bezeichnet werden, in dem die Ergebnisse und der Status von Aufgabe
 Wie betreibt
Wie betreibt ThreadPoolExecutor dieses Objekt intern?
Das Folgende ist eine kurze Einführung in einen Teil des Codes von ThreadPoolExecutor:
1.init-Methode Das Wichtigste in der init-Methode ist die Aufgabenwarteschlange und Thread-Sammlung, die in anderen Methoden benötigt werden.
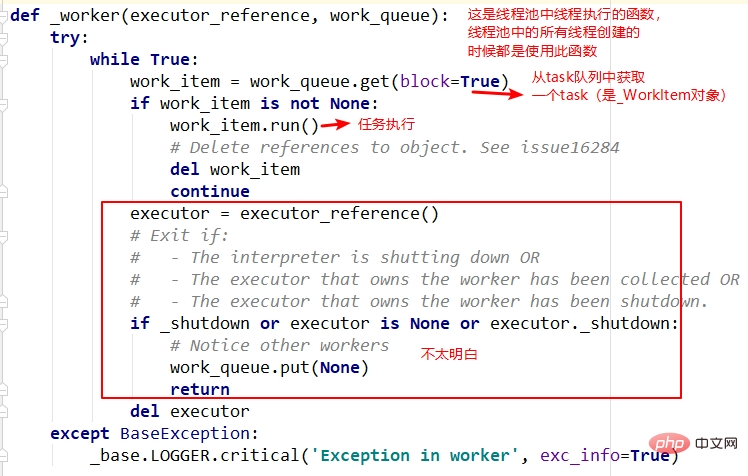
submit, _base.Future() und _WorkItem() Objekte, _WorkItem () Das -Objekt ist für die Ausführung von Aufgaben und das Festlegen des future-Objekts verantwortlich. Schließlich wird das future-Objekt zurückgegeben. Sie können sehen, dass der gesamte Prozess zurückgegeben wird sofort ohne Blockierung. 🎜🎜🎜🎜3 .adjust_thread_count Methode 🎜🎜Die Bedeutung dieser Methode ist leicht zu verstehen, sie erstellt hauptsächlich die angegebene Anzahl von Threads. Die Implementierung ist jedoch etwas schwer zu verstehen. Beispielsweise beinhaltet die Funktion „weakref.ref“ in der Thread-Ausführung Konzepte wie schwache Referenzen, die später verstanden werden müssen. 🎜🎜🎜🎜4 ._WorkItem Die Aufgabe des Objekts 🎜🎜_WorkItem besteht darin, Aufgaben auszuführen und Ergebnisse festzulegen. Die Hauptkomplexität hier ist self.future.set_result(result)🎜. 🎜🎜🎜🎜🎜🎜5. Thread-Ausführungsfunktion – _worker🎜🎜Dies ist der Funktionseintrag, der angegeben wird, wenn der Thread-Pool einen Thread erstellt und ihn ausführt, aber der erste Parameter des Funktion ist noch nicht ganz klar. Heben Sie sich das für später auf. 🎜🎜🎜🎜Das obige ist der detaillierte Inhalt vonSo lösen Sie das Thread-Pool-Problem von Pythons ThreadPoolExecutor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!