
Heim >Backend-Entwicklung >Python-Tutorial >So verwenden Sie zwei Zeilen Python-Code, um PDF in Word zu konvertieren
So verwenden Sie zwei Zeilen Python-Code, um PDF in Word zu konvertieren

- 王林nach vorne
- 2023-04-28 18:25:062494Durchsuche
一、安装依赖包
pip install --index https://pypi.mirrors.ustc.edu.cn/simple/ python-office
二、pdf转word
2.1
[1/4] Eröffnungsdokument...
[INFO] [2/ 4] Dokument wird analysiert...[WARNUNG] Der Zeitstempel „erstellt“ scheint sehr niedrig zu sein. als Unix-Zeitstempel betrachten[WARNUNG] Der „geänderte“ Zeitstempel scheint sehr niedrig zu sein; als Unix-Zeitstempel betrachten
[WARNUNG] Der 'erstellte' Zeitstempel scheint sehr niedrig zu sein; als Unix-Zeitstempel betrachten
[WARNUNG] Der „geänderte“ Zeitstempel scheint sehr niedrig zu sein; betrachtet als Unix-Zeitstempel
[INFO] [3/4] Parsing-Seiten...
[INFO] (1/9) Seite 1
[INFO] (2/9) Seite 2
[INFO] (3/9) Seite 3
[INFO] (4/9) Seite 4
[INFO] (5/9) Seite 5
[INFO] (6/9) Seite 6
[INFO] (7/9) Seite 7
[INFO] ( 8/9) Seite 8
[INFO] (9/9) Seite 9
[INFO] [4/4] Seiten erstellen...
[INFO] (1/9) Seite 1
[INFO] (2/9 ) Seite 2
[INFO] (3/9) Seite 3
[INFO] (4/9) Seite 4
[INFO] (5/9) Seite 5
[INFO] (6/9) Seite 6
[INFO ] (7/9) Seite 7
[INFO] (8/9) Seite 8
[INFO] (9/9) Seite 9
[INFO] In 1,30 Sekunden beendet.
Prozess beendet mit Exit-Code 0
2.2 pdf内容
2.3 转换后的word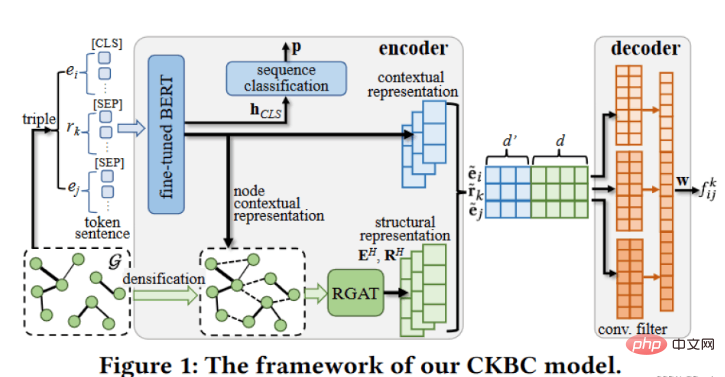
由上可见,效果还不错。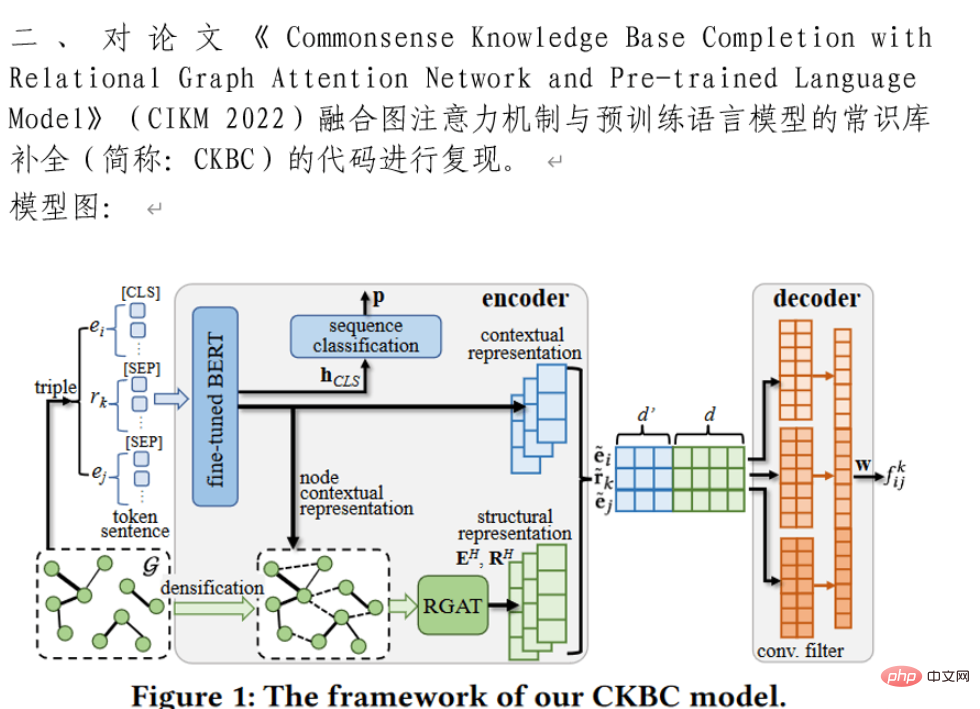
import office office.pdf.pdf2docx(file_path = 'test.pdf')方法二:加密过的PDF转word
import os
from configparser import ConfigParser
from io import StringIO
from io import open
from concurrent.futures import ProcessPoolExecutor
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import process_pdf
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from docx import Document
def read_from_pdf(file_path):
with open(file_path, 'rb') as file:
resource_manager = PDFResourceManager()
return_str = StringIO()
lap_params = LAParams()
device = TextConverter(
resource_manager, return_str, laparams=lap_params)
process_pdf(resource_manager, device, file)
device.close()
content = return_str.getvalue()
return_str.close()
return content
def save_text_to_word(content, file_path):
doc = Document()
for line in content.split('\n'):
paragraph = doc.add_paragraph()
paragraph.add_run(remove_control_characters(line))
doc.save(file_path)
def remove_control_characters(content):
mpa = dict.fromkeys(range(32))
return content.translate(mpa)
def pdf_to_word(pdf_file_path, word_file_path):
content = read_from_pdf(pdf_file_path)
save_text_to_word(content, word_file_path)
def main():
config_parser = ConfigParser()
config_parser.read('config.cfg')
config = config_parser['default']
tasks = []
with ProcessPoolExecutor(max_workers=int(config['max_worker'])) as executor:
for file in os.listdir(config['pdf_folder']):
extension_name = os.path.splitext(file)[1]
if extension_name != '.pdf':
continue
file_name = os.path.splitext(file)[0]
pdf_file = config['pdf_folder'] + '/' + file
word_file = config['word_folder'] + '/' + file_name + '.docx'
print('正在处理: ', file)
result = executor.submit(pdf_to_word, pdf_file, word_file)
tasks.append(result)
while True:
exit_flag = True
for task in tasks:
if not task.done():
exit_flag = False
if exit_flag:
print('完成')
exit(0)
if __name__ == '__main__':
main()Das obige ist der detaillierte Inhalt vonSo verwenden Sie zwei Zeilen Python-Code, um PDF in Word zu konvertieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!