
Heim >Java >javaLernprogramm >Analyse von Nutzungsszenarien für Java-Sperren bei der Arbeit
Analyse von Nutzungsszenarien für Java-Sperren bei der Arbeit

- PHPznach vorne
- 2023-04-28 15:34:141163Durchsuche
1. synchronisiert ist eine wiedereintrittsfähige Sperre. Sie hat ähnliche Funktionen wie die ReentrantLock-Sperre. Die größte Ähnlichkeit zwischen den beiden besteht darin, dass sie wiedereintrittsfähig sind Die folgenden Hauptunterschiede:
- ReentrantLock verfügt über umfassendere Funktionen, z. B. die Bereitstellung einer Bedingung, eine Sperr-API, die unterbrochen werden kann, und kann komplexe Sperr- und Warteschlangenszenarien usw. erfüllen.
ReentrantLock kann in faire und unfaire Sperren unterteilt werden Sperren, während synchronisiert sind, sind beide unfaire Sperren; Das Lösen der Sperre und die Synchronisierung sind bequemer zu verwenden.
synchronized und ReentrantLock haben ähnliche Funktionen, daher nehmen wir synchronisiert als Beispiel.
1.1. Initialisierung gemeinsam genutzter RessourcenIn einem verteilten System sperren wir beim Start des Projekts gerne einige tote Konfigurationsressourcen im JVM-Speicher, sodass diese beim Anfordern dieser gemeinsam genutzten Konfigurationsressourcen direkt aus dem Speicher abgerufen werden können Es muss jedes Mal aus der Datenbank abgerufen werden, was den Zeitaufwand reduziert.
Im Allgemeinen umfassen solche gemeinsam genutzten Ressourcen: tote Geschäftsprozesskonfiguration + tote Geschäftsregelkonfiguration.
Die Schritte zum Initialisieren gemeinsam genutzter Ressourcen sind im Allgemeinen: Starten Sie das Projekt –> Auslösen der Initialisierungsaktion –> Abrufen von Daten aus der Datenbank in einem einzelnen Thread –> Einfügen in die Datenstruktur der JVM-Speicher.
Um zu verhindern, dass gemeinsam genutzte Ressourcen mehrmals geladen werden, fügen wir beim Start des Projekts häufig exklusive Sperren hinzu, sodass nach Abschluss des Ladens der gemeinsam genutzten Ressourcen ein anderer Thread weiter geladen werden kann. Zu diesem Zeitpunkt können wir auswählen die exklusive Sperre synchronisiert oder ReentrantLock, wir haben synchronisiert als Beispiel genommen und den Scheincode wie folgt geschrieben:
// 共享资源
private static final Map<String, String> SHARED_MAP = Maps.newConcurrentMap();
// 有无初始化完成的标志位
private static boolean loaded = false;
/**
* 初始化共享资源
*/
@PostConstruct
public void init(){
if(loaded){
return;
}
synchronized (this){
// 再次 check
if(loaded){
return;
}
log.info("SynchronizedDemo init begin");
// 从数据库中捞取数据,组装成 SHARED_MAP 的数据格式
loaded = true;
log.info("SynchronizedDemo init end");
}
}Ich weiß nicht, ob Sie die @PostConstruct-Annotation aus dem obigen Code gefunden haben um die Annotation @PostConstruct auszuführen, wenn der Spring-Container initialisiert wird. Die mit der Annotation markierte Methode bedeutet, dass die im Bild oben gezeigte Init-Methode ausgelöst wird, wenn der Spring-Container gestartet wird.
Sie können den Democode herunterladen, die DemoApplication-Startdatei suchen, mit der rechten Maustaste auf „Ausführen“ in der DemoApplication-Datei klicken, um das gesamte Spring Boot-Projekt zu starten, und einen Haltepunkt für die Init-Methode zum Debuggen setzen.
Wir verwenden im Code synchronisiert, um sicherzustellen, dass nur ein Thread gleichzeitig den Vorgang zum Initialisieren gemeinsam genutzter Ressourcen ausführen kann, und fügen ein Flag für den Abschluss des Ladens gemeinsam genutzter Ressourcen (geladen) hinzu, um festzustellen, ob der Ladevorgang abgeschlossen ist , dann kehren andere Ladethreads direkt zurück.
Wenn Sie synchronisiert durch ReentrantLock ersetzen, ist die Implementierung dieselbe, Sie müssen jedoch explizit die API von ReentrantLock verwenden, um die Sperre zu sperren und freizugeben. Bei der Verwendung von ReentrantLock ist zu beachten, dass wir den try-Methodenblock sperren müssen Geben Sie in „finally“ die Sperre im Methodenblock frei, um sicherzustellen, dass die Sperre in „finally“ ordnungsgemäß aufgehoben werden kann, auch wenn nach dem Sperren in „try“ eine Ausnahme auftritt.
Einige Schüler fragen sich vielleicht: Können wir ConcurrentHashMap nicht direkt verwenden? Es stimmt, dass ConcurrentHashMap Thread-sicher ist, aber es kann die Thread-Sicherheit nur während der Map-internen Datenoperationen gewährleisten. Es kann nicht garantiert werden, dass in Multithread-Situationen die gesamte Aktion der Datenbankabfrage und der Zusammenstellung von Daten nur einmal ausgeführt wird Das Hinzufügen synchronisierter Sperren ist der gesamte Vorgang, wodurch sichergestellt wird, dass der gesamte Vorgang nur einmal ausgeführt wird.
2. CountDownLatch
2.1. Szenario
1: Xiao Ming hat ein Produkt bei Taobao gekauft und das Produkt zurückgegeben (das Produkt wurde noch nicht versendet, nur das Geld wird von uns zurückerstattet). Nennen wir es eine einzelne Produktrückerstattung. Wenn eine einzelne Produktrückerstattung im Hintergrundsystem ausgeführt wird, beträgt der Gesamtzeitverbrauch 30 Millisekunden.
2: Bei Double 11 kaufte Xiao Ming 40 Produkte auf Taobao und generierte dieselbe Bestellung (tatsächlich können mehrere Bestellungen generiert werden, der Einfachheit halber nennen wir sie eine). Am nächsten Tag fand Xiao Ming 30 der Produkte . Es war ein Impulskauf und ich muss alle 30 Artikel zusammen zurückgeben.
2.2. Implementierung
Derzeit hat das Backend nur die Funktion, einzelne Produkte zu erstatten, und nicht die Funktion, Produktchargen zu erstatten (die Rückgabe von 30 Produkten auf einmal wird als Charge bezeichnet). Um diese Funktion zu implementieren, folgte Student A diesem Plan: Die for-Schleife ruft die Rückerstattungsschnittstelle für einzelne Produkte 30 Mal auf. Während des QS-Umgebungstests wurde festgestellt, dass die Rückerstattung von 30 Produkten 30 * 30 = 900 Millisekunden dauern würde. Plus andere Logik, die Rückerstattung würde fast 1 Sekunde dauern, um 30 Produkte auszuwählen, was tatsächlich lange dauert. Damals stellte Klassenkamerad A diese Frage und hoffte, dass jeder dazu beitragen kann, den Zeitverbrauch der gesamten Szene zu optimieren.
同学 B 当时就提出,你可以使用线程池进行执行呀,把任务都提交到线程池里面去,假如机器的 CPU 是 4 核的,最多同时能有 4 个单商品退款可以同时执行,同学 A 觉得很有道理,于是准备修改方案,为了便于理解,我们把两个方案都画出来,对比一下:
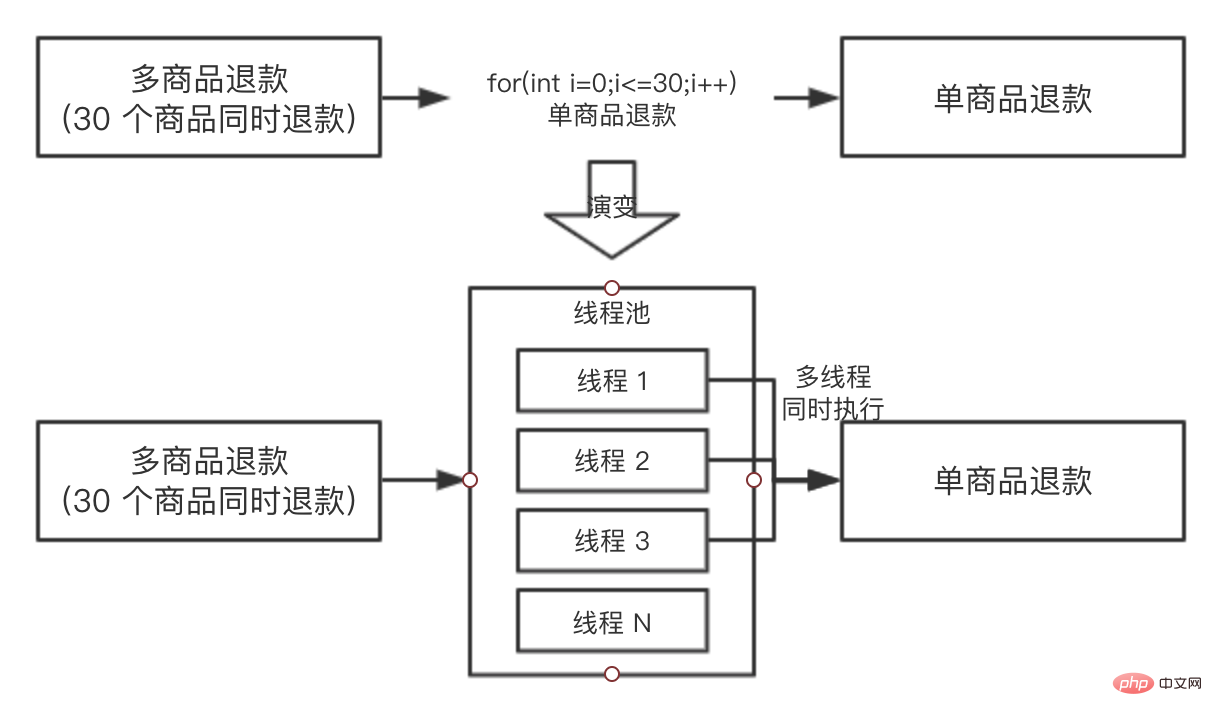
同学 A 于是就按照演变的方案去写代码了,过了一天,抛出了一个问题:向线程池提交了 30 个任务后,主线程如何等待 30 个任务都执行完成呢?因为主线程需要收集 30 个子任务的执行情况,并汇总返回给前端。
大家可以先不往下看,自己先思考一下,我们前几章说的那种锁可以帮助解决这个问题?
CountDownLatch 可以的,CountDownLatch 具有这种功能,让主线程去等待子任务全部执行完成之后才继续执行。
此时还有一个关键,我们需要知道子线程执行的结果,所以我们用 Runnable 作为线程任务就不行了,因为 Runnable 是没有返回值的,我们需要选择 Callable 作为任务。
我们写了一个 demo,首先我们来看一下单个商品退款的代码:
// 单商品退款,耗时 30 毫秒,退款成功返回 true,失败返回 false
@Slf4j
public class RefundDemo {
/**
* 根据商品 ID 进行退款
* @param itemId
* @return
*/
public boolean refundByItem(Long itemId) {
try {
// 线程沉睡 30 毫秒,模拟单个商品退款过程
Thread.sleep(30);
log.info("refund success,itemId is {}", itemId);
return true;
} catch (Exception e) {
log.error("refundByItemError,itemId is {}", itemId);
return false;
}
}
}接着我们看下 30 个商品的批量退款,代码如下:
@Slf4j
public class BatchRefundDemo {
// 定义线程池
public static final ExecutorService EXECUTOR_SERVICE =
new ThreadPoolExecutor(10, 10, 0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(20));
@Test
public void batchRefund() throws InterruptedException {
// state 初始化为 30
CountDownLatch countDownLatch = new CountDownLatch(30);
RefundDemo refundDemo = new RefundDemo();
// 准备 30 个商品
List<Long> items = Lists.newArrayListWithCapacity(30);
for (int i = 0; i < 30; i++) {
items.add(Long.valueOf(i+""));
}
// 准备开始批量退款
List<Future> futures = Lists.newArrayListWithCapacity(30);
for (Long item : items) {
// 使用 Callable,因为我们需要等到返回值
Future<Boolean> future = EXECUTOR_SERVICE.submit(new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
boolean result = refundDemo.refundByItem(item);
// 每个子线程都会执行 countDown,使 state -1 ,但只有最后一个才能真的唤醒主线程
countDownLatch.countDown();
return result;
}
});
// 收集批量退款的结果
futures.add(future);
}
log.info("30 个商品已经在退款中");
// 使主线程阻塞,一直等待 30 个商品都退款完成,才能继续执行
countDownLatch.await();
log.info("30 个商品已经退款完成");
// 拿到所有结果进行分析
List<Boolean> result = futures.stream().map(fu-> {
try {
// get 的超时时间设置的是 1 毫秒,是为了说明此时所有的子线程都已经执行完成了
return (Boolean) fu.get(1,TimeUnit.MILLISECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
return false;
}).collect(Collectors.toList());
// 打印结果统计
long success = result.stream().filter(r->r.equals(true)).count();
log.info("执行结果成功{},失败{}",success,result.size()-success);
}
}上述代码只是大概的底层思路,真实的项目会在此思路之上加上请求分组,超时打断等等优化措施。
我们来看一下执行的结果:
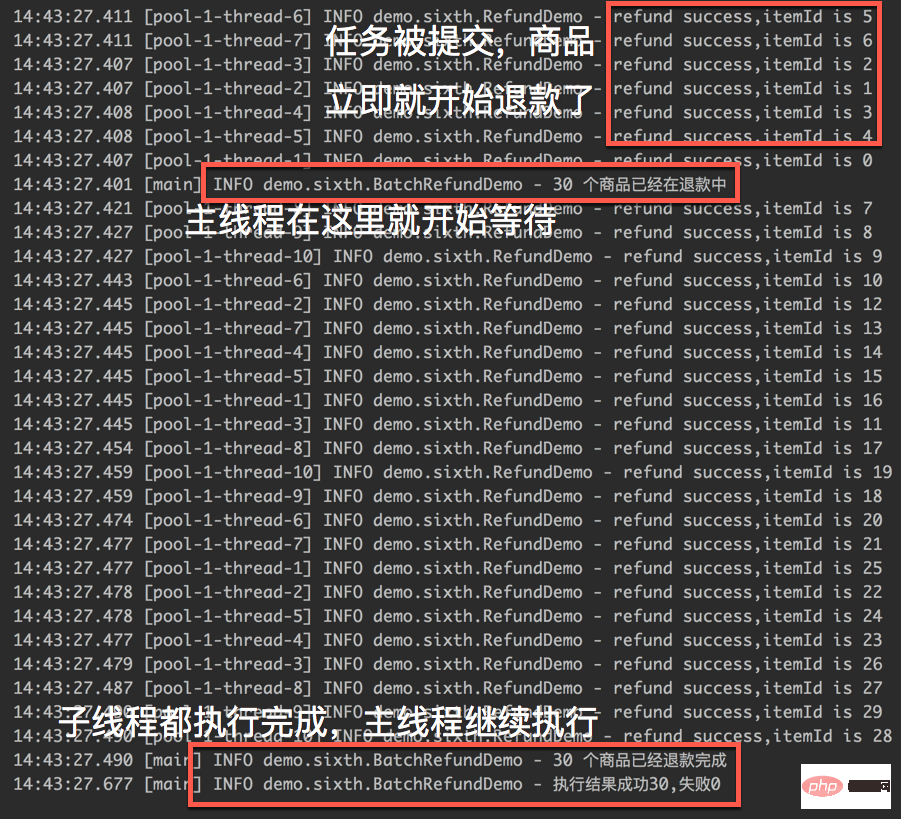
从执行的截图中,我们可以明显的看到 CountDownLatch 已经发挥出了作用,主线程会一直等到 30 个商品的退款结果之后才会继续执行。
接着我们做了一个不严谨的实验(把以上代码执行很多次,求耗时平均值),通过以上代码,30 个商品退款完成之后,整体耗时大概在 200 毫秒左右。
而通过 for 循环单商品进行退款,大概耗时在 1 秒左右,前后性能相差 5 倍左右,for 循环退款的代码如下:
long begin1 = System.currentTimeMillis();
for (Long item : items) {
refundDemo.refundByItem(item);
}
log.info("for 循环单个退款耗时{}",System.currentTimeMillis()-begin1);性能的巨大提升是线程池 + 锁两者结合的功劳。
Das obige ist der detaillierte Inhalt vonAnalyse von Nutzungsszenarien für Java-Sperren bei der Arbeit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!