
Heim >Web-Frontend >js-Tutorial >Erfahren Sie mehr über Puffer in Node
Erfahren Sie mehr über Puffer in Node

- 青灯夜游nach vorne
- 2023-04-25 19:49:112837Durchsuche

Am Ende des Stream-Kapitels bleibt uns die Frage: Was ist der Chunk, der vom folgenden Code ausgegeben wird?
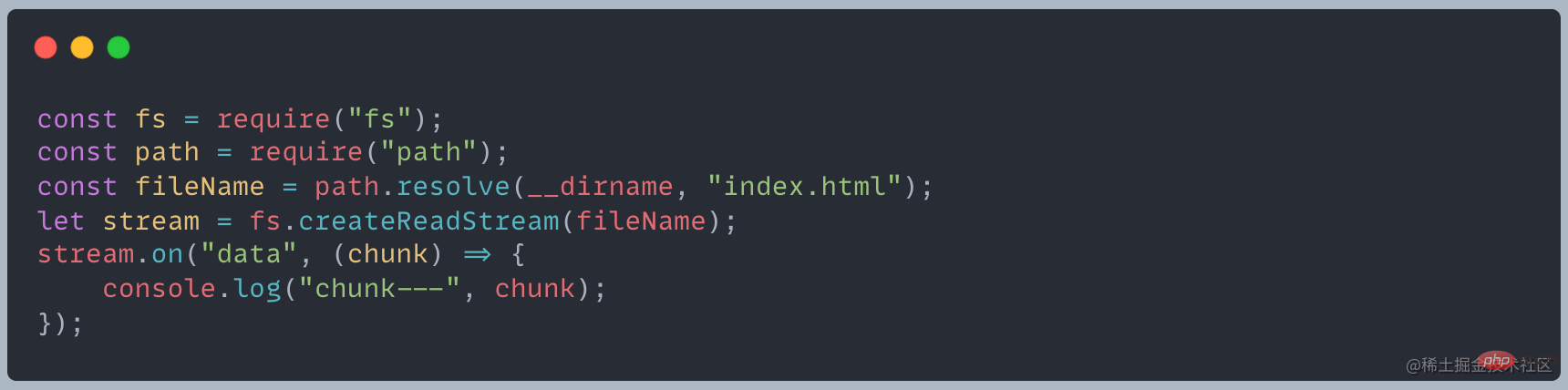
Durch Drucken stellen wir fest, dass Chunk ein Pufferobjekt ist, dessen Elemente hexadezimale zweistellige Zahlen sind, also Werte von 0 bis 255. [Verwandte Tutorial-Empfehlungen: nodejs-Video-Tutorial, Programmierlehre]

erklärt, dass die im Stream fließenden Daten der Puffer sind. Lassen Sie uns also das wahre Gesicht des Puffers erkunden!
Warum wurde Buffer in Node eingeführt?
Am Anfang war es einfach, Unicode-codierte Strings zu verarbeiten, aber es war schwierig, binäre und nicht Unicode-codierte Strings zu verarbeiten . Und Binär ist das Datenformat der niedrigsten Ebene des Computers. Video-/Audio-/Programm-/Netzwerkpakete werden alle im Binärformat gespeichert. Daher muss Node ein Objekt einführen, um binär zu arbeiten. Daher wurde Buffer geboren, der für TCP-Streams/Dateisysteme und andere Vorgänge zur Verarbeitung binärer Bytes verwendet wird.
Da Buffer in Node zu häufig verwendet wird, wurde Buffer beim Start von Node eingeführt. Es besteht keine Notwendigkeit, require() zu verwenden.
Was ist ArrayBuffer? ArrayBuffer ist ein binäres Datenelement im Speicher und kann nicht verwendet werden Der Speicher selbst muss über
TypedArray-Objektoder
DataViewbedient werden. Stellen Sie die Daten im Puffer in einem bestimmten Format dar und lesen und schreiben Sie den Inhalt des Puffers über diese Formate. Es stellt eine Array-Schnittstelle bereit und kann Arrays zum Bearbeiten von Daten verwenden. TypedArray-Ansicht Am häufigsten wird die TypeArray-Ansicht verwendet , wird zum Lesen und Schreiben einfacher ArrayBuffer-Typen verwendet, z. B. der Array-Ansicht Uint8Array (8-Bit-Ganzzahl ohne Vorzeichen) und der Array-Ansicht Int16Array (16-Bit-Ganzzahl). Die Beziehung zwischen und Buffer
Die Buffer-Klasse in NodeJS ist eigentlich die Implementierung von Uint8Array.
Pufferstruktur
Buffer ist ein Objekt ähnlich wie Array, wird jedoch hauptsächlich zum Betrieb von Bytes verwendet.
Modulstruktur
Buffer ist ein Modul, das JS und C++ kombiniert. Der Leistungsteil ist in C++ implementiert, und der Nicht-. Der Leistungsteil ist alles JS. Der vom implementierten
Puffer belegte Speicher wird von V8 nicht zugewiesen und gehört zum Off-Heap-Speicher. Objektstruktur Pufferobjekt ähnelt einem Array, seine Elemente sind hexadezimale zweistellige Zahlen, also Werte von 0 bis 255
Pufferobjekt ähnelt einem Array, seine Elemente sind hexadezimale zweistellige Zahlen, also Werte von 0 bis 255
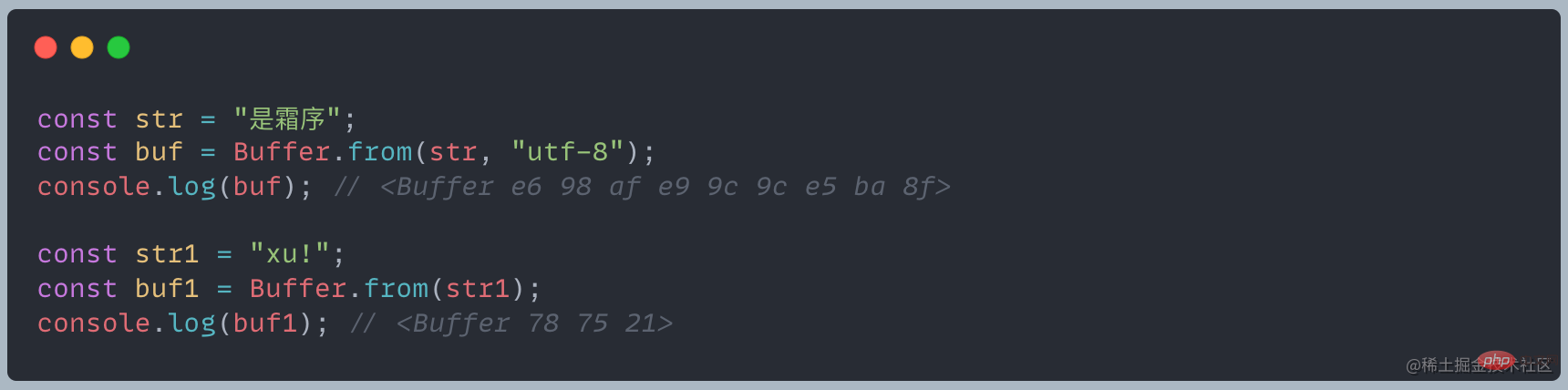
Für die obige Situation ist die Verarbeitung von Buffer wie folgt:
Wenn Sie erhalten: Wenn der Wert größer als 255 ist, subtrahieren Sie einfach 256 nacheinander, bis Sie einen Wert im Bereich von 0 bis 255 erhalten.Wenn der dem Element zugewiesene Wert kleiner als 0 ist, addieren Sie nacheinander 256 zum Wert, bis Sie eine Ganzzahl zwischen 0 und 255 erhalten
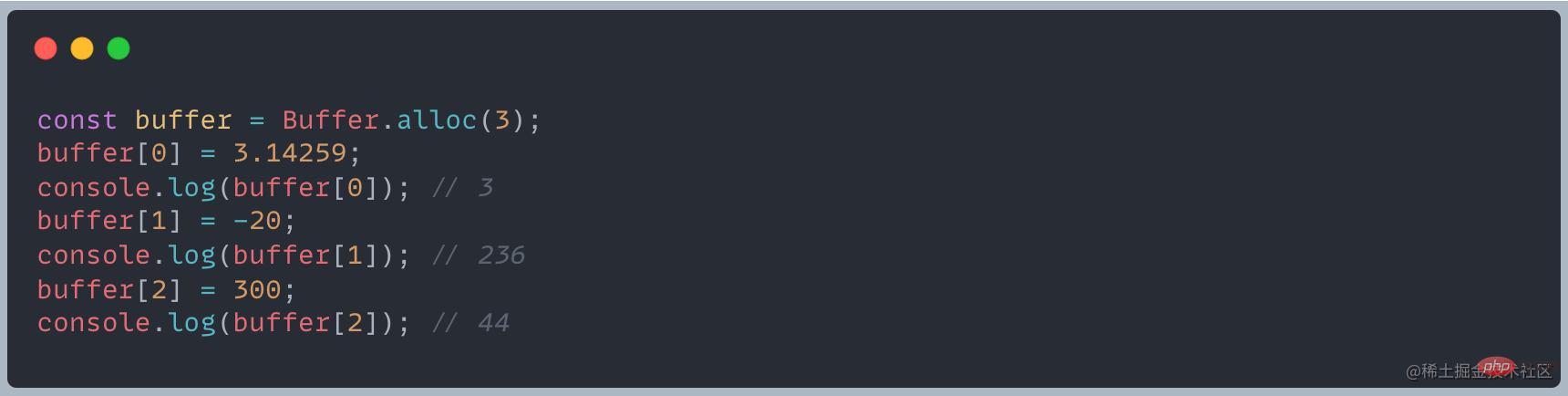 Wenn es sich um eine Dezimalzahl handelt, wird nur der ganzzahlige Teil beibehalten.
Wenn es sich um eine Dezimalzahl handelt, wird nur der ganzzahlige Teil beibehalten.
- Warum? Der Puffer wird hexadezimal angezeigt. Tatsächlich wird er immer noch im Speicher gespeichert. Der Puffer verwendet jedoch hexadezimale Zahlen, wenn er die Speicherdaten anzeigt. Die Puffergröße beträgt beispielsweise 16 Bit von
- Buffer
- Buffer.alloc und Buffer.allocUnsafe
Buffer.alloc(size [, fill [,kodierung]])
- size Die erforderliche Länge des neuen Puffers
- fill Der Wert, der zum Vorfüllen des neuen Puffers verwendet wird. Standard: 0
- encoding Wenn fill ein String ist, ist dies seine Zeichenkodierung. Standardwert: utf8
Buffer.allocUnsafe(size)
Allokiert einen Puffer mit einer Größe von Bytes. Wir haben festgestellt, dass seine Ergebnisse nicht wie Buffer.alloc auf 00 initialisiert werden
Das beim Aufruf von allocUnsafe zugewiesene Speichersegment wurde nicht initialisiert, sodass die Speicherzuweisungsgeschwindigkeit sehr langsam ist, das zugewiesene Speichersegment jedoch möglicherweise alte Daten enthält. Wenn Sie diese alten Daten während der Verwendung nicht überschreiben, kann dies zu Speicherverlusten führen. Versuchen Sie jedoch, die Verwendung zu vermeiden. Das Buffer-Modul weist eine interne Buffer-Instanz mit der Größe Buffer.poolSize als schnell zugewiesene Instanz zu Speicherpool. Verwenden Sie allocUnsafe, um eine neue Pufferinstanz zu erstellen.
Buffer.from Buffer.from(buffer)
Der Speichermechanismus von Buffer.allocUnsafe
Um den angeforderten Speicher effizient zu nutzen, übernimmt Node.js den Slab-Mechanismus für die Voranwendung und Nachzuweisung, einen dynamischen Verwaltungsmechanismus
Verwenden Sie Buffer.alloc(size). Die Übergabe einer bestimmten Größe gilt für einen Speicherbereich mit fester Größe. Die Platte hat die folgenden drei Zustände: vollständig: vollständig zugewiesener Zustand, teilweise: teilweise zugewiesener Zustand, leer: nicht Zugeordneter Status
- Node .js verwendet 8 KB als Grenze, um kleine Objekte von großen Objekten zu unterscheiden. Die Größe des Puffers wird bei der Erstellung festgelegt und kann nicht angepasst werden!
- Kleine Objekte zuweisen
Wenn das zugewiesene Objekt weniger als 8 KB groß ist, weist der Knoten es als kleines Objekt zu.
Der Pufferzuweisungsprozess verwendet hauptsächlich einen lokalen Variablenpool als Zwischenverarbeitungsobjekt und die Platteneinheit im Zuordnungsstatus Alle deuten darauf hin. Im Folgenden wird der Vorgang zum Zuweisen einer neuen Platteneinheit beschrieben, die das neu angewendete SlowBuffer-Objekt darauf verweist. Eine Platteneinheit. Ein 2-KB-Puffer wird zugewiesen. Nach dem Erstellen eines 2-KB-Puffers wird eine Platte erstellt Der Einheitsspeicher lautet wie folgt:Dieser Zuordnungsprozess wird durch die Zuweisungsmethode abgeschlossen.
Wenn der Plattenplatz nicht ausreicht, wird eine neue Platte erstellt und der verbleibende Platz in der ursprünglichen Platte wird verschwendet. Große Objekte zuweisen. Wenn ein Puffer größer als 8 KB ist, wird er direkt zur Funktion creatUnsafeBuffer weitergeleitet und eine Platteneinheit zugewiesen. Diese Platteneinheit wird ausschließlich von diesem großen Pufferobjekt belegt. Der Speicherzuweisungsmechanismus ist dargestellt Der Mechanismus von Buffer ist wie in der Abbildung dargestellt. Durch die Verwendung der Zeichenkodierung können Buffer-Instanzen und JavaScript-Strings ineinander konvertiert werden
- Nachdem wir einen 2-KB-Puffer erstellt haben, ist der aktuelle Plattenstatus teilweise.
- Wenn wir den Puffer erneut erstellen, werden wir dies beurteilen die aktuelle Ob der verbleibende Platz der Platte ausreicht. Wenn ausreichend Platz vorhanden ist, verwenden Sie den verbleibenden Platz und aktualisieren Sie den Plattenzuordnungsstatus.
Node unterstützt derzeit acht Kodierungsmethoden: utf8, ucs2, utf16le, latin1, ascii, base64, hex und base64Url. Spezifische Implementierung
Für jedes unterschiedliche Kodierungsschema wird eine Reihe von APIs implementiert Je nach eingehender Codierung gibt Node.js unterschiedliche Objekte zurück. Konvertierung von Puffer und String. String in Puffer. Hauptsächlich über die oben erwähnte Buffer.from-Methode. Die Standardcodierung ist UTF-8
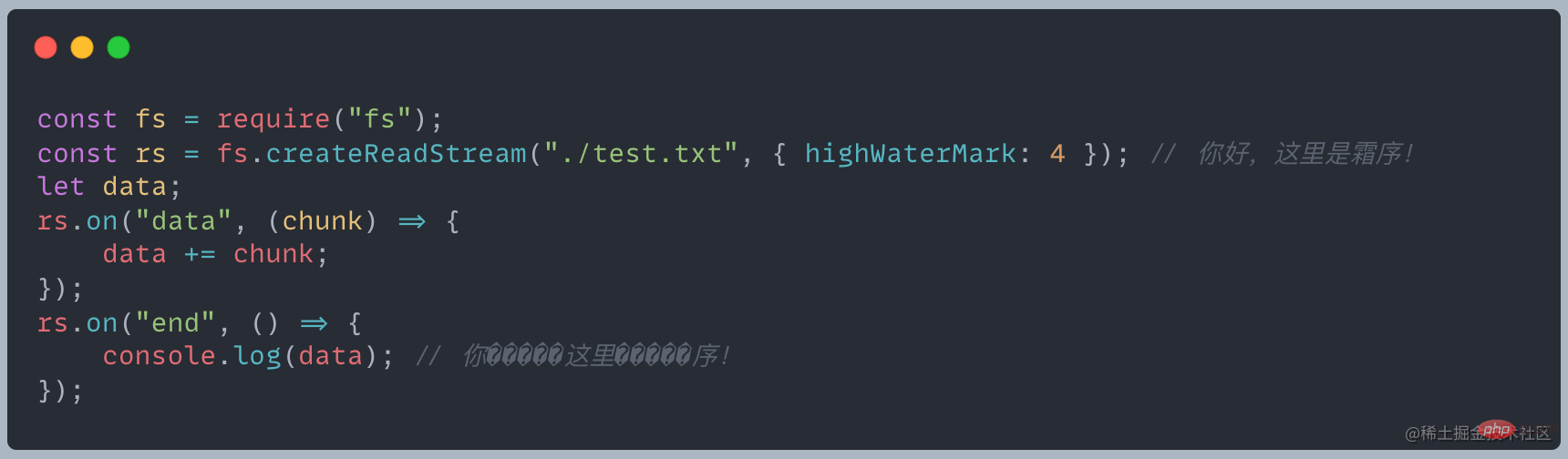
Puffer zum Konvertieren von Zeichenfolgen Warum gibt es verstümmelte Zeichen? Wie kann dieses Problem gelöst werden?In Bezug auf das Lesen beträgt die Länge jedes Lesevorgangs 4 und die Blockausgabe lautet wie folgt:
FürDa ein chinesisches Zeichen drei Bytes belegt, wird das vierte im ersten Block angezeigt. Die Bytes werden angezeigt verstümmelte Zeichen und das erste und zweite Byte des zweiten Blocks können keinen Text usw. bilden, sodass verstümmelte Zeichen angezeigt werden. Weitere Informationen zu Knoten finden Sie unter:nodejs-Tutorial

 Buffer.from Buffer.from(buffer)
Buffer.from Buffer.from(buffer)

 !
! Das obige ist der detaillierte Inhalt vonErfahren Sie mehr über Puffer in Node. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- So verwenden Sie Node.js, um das Fahren von Fahrzeugen zu simulieren
- Wie NodeJS mit Big Data interagiert
- Einige häufige CentOS Node.js-Fehler und ihre Lösungen
- Was nützt NodeJS PM2?
- Lassen Sie uns über den Modul-Hot-Replacement sprechen, der mit Node.js geliefert wird
- So erhalten Sie den Anforderungstext in NodeJS