
Heim >Java >javaLernprogramm >Wie implementiert man einen ungerichteten Graphen in Java?
Wie implementiert man einen ungerichteten Graphen in Java?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-24 13:52:071671Durchsuche
基本概念
图的定义
一个图是由点集V={vi} 和 VV 中元素的无序对的一个集合E={ek} 所构成的二元组,记为G=(V,E),V中的元素vi叫做顶点,E中的元素 ek叫做边。
对于V中的两个点 u,v,如果边(u,v) 属于E,则称 u,v两点相邻,u,v称为边(u,v)的端点。
我们可以用m(G)=|E| 表示图G中的边数,用n(G)=|V|表示图G中的顶点个数。
无向图的定义
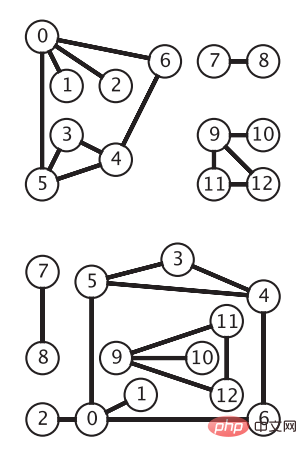
对于E中的任意一条边(vi,vj),如果边(vi,vj) 端点无序,则它是无向边,此时图G称为无向图。无向图是最简单的图模型,下图显示了同一幅无向图,顶点使用圆圈表示,边则是顶点之间的连线,没有箭头(图片来自于《算法第四版》):
无向图的 API
对于一幅无向图,我们关心图的顶点数、边数、每个顶点的相邻顶点和边的添加操作,所以接口如下所示:
package com.zhiyiyo.graph;
/**
* 无向图
*/
public interface Graph {
/**
* 返回图中的顶点数
*/
int V();
/**
* 返回图中的边数
*/
int E();
/**
* 向图中添加一条边
* @param v 顶点 v
* @param w 顶点 w
*/
void addEdge(int v, int w);
/**
* 返回所有相邻顶点
* @param v 顶点 v
* @return 所有相邻顶点
*/
Iterable<Integer> adj(int v);
}无向图的实现方式
邻接矩阵
用矩阵表示图对研究图的性质及应用常常是比较方便的,对于各种图有各种矩阵表示方式,比如权矩阵和邻接矩阵,这里我们只关注邻接矩阵。它的定义为:
对于图G=(V,E),|V|=n,构造一个矩阵 A=(aij)n×n,其中:

则称矩阵A为图G的邻接矩阵。
由定义可知,我们可以使用一个二维的布尔数组 A 来实现邻接矩阵,当 A[i][j] = true 时说明顶点 i 和 j 相邻。
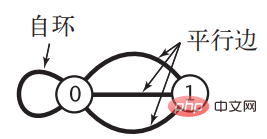
对于 n个顶点的图 G,邻接矩阵需要消耗的空间为 n2个布尔值的大小,对于稀疏图来说会造成很大的浪费,当顶点数很大时所消耗的空间会是个天文数字。同时当图比较特殊,存在自环以及平行边时,邻接矩阵的表示方式是无能为力的。《算法》中给出了存在这两种情况的图:
边的数组
对于无向图,我们可以实现一个类 Edge,里面只用两个实例变量用来存储两个顶点 u和 v,接着在一个数组里面保存所有 Edge 即可。这样做有一个很大的问题,就是在获取顶点 v的所有相邻顶点时必须遍历整个数组才能得到,时间复杂度是O(|E|),由于获取相邻顶点是很常用的操作,所以这种表示方式也不太行。
邻接表数组
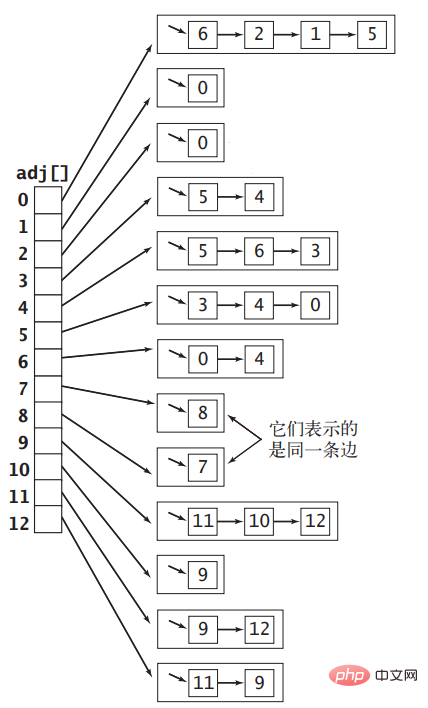
如果我们把顶点表示为一个整数,取值范围为0∼|V|−1,那么就可以用一个长度为|V| 的数组的索引表示每一个顶点,然后将每一个数组元素设置为一个链表,上面挂载着索引所代表的的顶点相邻的其他顶点。图一所示的无向图可以用下图所示的邻接表数组表示出来:
使用邻接表实现无向图的代码如下所示,由于邻接表数组中的每个链表都会保存与顶点相邻的顶点,所以将边添加到图中时需要对数组中的两个链表进行添加节点的操作:
package com.zhiyiyo.graph;
import com.zhiyiyo.collection.stack.LinkStack;
/**
* 使用邻接表实现的无向图
*/
public class LinkGraph implements Graph {
private final int V;
private int E;
private LinkStack<Integer>[] adj;
public LinkGraph(int V) {
this.V = V;
adj = (LinkStack<Integer>[]) new LinkStack[V];
for (int i = 0; i < V; i++) {
adj[i] = new LinkStack<>();
}
}
@Override
public int V() {
return V;
}
@Override
public int E() {
return E;
}
@Override
public void addEdge(int v, int w) {
adj[v].push(w);
adj[w].push(v);
E++;
}
@Override
public Iterable<Integer> adj(int v) {
return adj[v];
}
}这里用到的栈代码如下所示,栈的实现不是这篇博客的重点,所以这里不做过多解释:
package com.zhiyiyo.collection.stack;
import java.util.EmptyStackException;
import java.util.Iterator;
/**
* 使用链表实现的堆栈
*/
public class LinkStack<T> {
private int N;
private Node first;
public void push(T item) {
first = new Node(item, first);
N++;
}
public T pop() throws EmptyStackException {
if (N == 0) {
throw new EmptyStackException();
}
T item = first.item;
first = first.next;
N--;
return item;
}
public int size() {
return N;
}
public boolean isEmpty() {
return N == 0;
}
public Iterator<T> iterator() {
return new ReverseIterator();
}
private class Node {
T item;
Node next;
public Node() {
}
public Node(T item, Node next) {
this.item = item;
this.next = next;
}
}
private class ReverseIterator implements Iterator<T> {
private Node node = first;
@Override
public boolean hasNext() {
return node != null;
}
@Override
public T next() {
T item = node.item;
node = node.next;
return item;
}
@Override
public void remove() {
}
}
}无向图的遍历
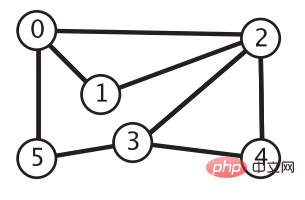
给定下面一幅图,现在要求找到每个顶点到顶点 0 的路径,该如何实现?或者简单点,给定顶点 0 和 4,要求判断从顶点 0 开始走,能否到达顶点 4,该如何实现?这就要用到两种图的遍历方式:深度优先搜索和广度优先搜索。
在介绍这两种遍历方式之前,先给出解决上述问题需要实现的 API:
package com.zhiyiyo.graph;
public interface Search {
/**
* 起点 s 和 顶点 v 之间是否连通
* @param v 顶点 v
* @return 是否连通
*/
boolean connected(int v);
/**
* 返回与顶点 s 相连通的顶点个数(包括 s)
*/
int count();
/**
* 是否存在从起点 s 到顶点 v 的路径
* @param v 顶点 v
* @return 是否存在路径
*/
boolean hasPathTo(int v);
/**
* 从起点 s 到顶点 v 的路径,不存在则返回 null
* @param v 顶点 v
* @return 路径
*/
Iterable<Integer> pathTo(int v);
}深度优先搜索
深度优先搜索的思想类似树的先序遍历。我们从顶点 0 开始,将它的相邻顶点 2、1、5 加到栈中。接着弹出栈顶的顶点 2,将它相邻的顶点 0、1、3、4 添加到栈中,但是写到这你就会发现一个问题:顶点 0 和 1明明已经在栈中了,如果还把他们加到栈中,那这个栈岂不是永远不会变回空。所以还需要维护一个数组 boolean[] marked,当我们将一个顶点 i 添加到栈中时,就将 marked[i] 置为 true,这样下次要想将顶点 i 加入栈中时,就得先检查一个 marked[i] 是否为 true,如果为 true 就不用再添加了。重复栈顶节点的弹出和节点相邻节点的入栈操作,直到栈为空,我们就完成了顶点 0 可达的所有顶点的遍历。
为了记录每个顶点到顶点 0 的路径,我们还需要一个数组 int[] edgeTo。每当我们访问到顶点 u 并将其一个相邻顶点 i 压入栈中时,就将 edgeTo[i] 设置为 u,说明要想从顶点i 到达顶点 0,需要先回退顶点 u,接着再从顶点 edgeTo[u] 处获取下一步要回退的顶点直至找到顶点 0。
package com.zhiyiyo.graph;
import com.zhiyiyo.collection.stack.LinkStack;
import com.zhiyiyo.collection.stack.Stack;
public class DepthFirstSearch implements Search {
private boolean[] marked;
private int[] edgeTo;
private Graph graph;
private int s;
private int N;
public DepthFirstSearch(Graph graph, int s) {
this.graph = graph;
this.s = s;
marked = new boolean[graph.V()];
edgeTo = new int[graph.V()];
dfs();
}
/**
* 递归实现的深度优先搜索
*
* @param v 顶点 v
*/
private void dfs(int v) {
marked[v] = true;
N++;
for (int i : graph.adj(v)) {
if (!marked[i]) {
edgeTo[i] = v;
dfs(i);
}
}
}
/**
* 堆栈实现的深度优先搜索
*/
private void dfs() {
Stack<Integer> vertexes = new LinkStack<>();
vertexes.push(s);
marked[s] = true;
while (!vertexes.isEmpty()) {
Integer v = vertexes.pop();
N++;
// 将所有相邻顶点加到堆栈中
for (Integer i : graph.adj(v)) {
if (!marked[i]) {
edgeTo[i] = v;
marked[i] = true;
vertexes.push(i);
}
}
}
}
@Override
public boolean connected(int v) {
return marked[v];
}
@Override
public int count() {
return N;
}
@Override
public boolean hasPathTo(int v) {
return connected(v);
}
@Override
public Iterable<Integer> pathTo(int v) {
if (!hasPathTo(v)) return null;
Stack<Integer> path = new LinkStack<>();
int vertex = v;
while (vertex != s) {
path.push(vertex);
vertex = edgeTo[vertex];
}
path.push(s);
return path;
}
}广度优先搜索
广度优先搜索的思想类似树的层序遍历。与深度优先搜索不同,从顶点 0 出发,广度优先搜索会先处理完所有与顶点 0 相邻的顶点 2、1、5 后,才会接着处理顶点 2、1、5 的相邻顶点。这个搜索过程就是一圈一圈往外扩展、越走越远的过程,所以可以用来获取顶点 0 到其他节点的最短路径。只要将深度优先搜索中的堆换成队列,就能实现广度优先搜索:
package com.zhiyiyo.graph;
import com.zhiyiyo.collection.queue.LinkQueue;
public class BreadthFirstSearch implements Search {
private boolean[] marked;
private int[] edgeTo;
private Graph graph;
private int s;
private int N;
public BreadthFirstSearch(Graph graph, int s) {
this.graph = graph;
this.s = s;
marked = new boolean[graph.V()];
edgeTo = new int[graph.V()];
bfs();
}
private void bfs() {
LinkQueue<Integer> queue = new LinkQueue<>();
marked[s] = true;
queue.enqueue(s);
while (!queue.isEmpty()) {
int v = queue.dequeue();
N++;
for (Integer i : graph.adj(v)) {
if (!marked[i]) {
edgeTo[i] = v;
marked[i] = true;
queue.enqueue(i);
}
}
}
}
}队列的实现代码如下:
package com.zhiyiyo.collection.queue;
import java.util.EmptyStackException;
public class LinkQueue<T> {
private int N;
private Node first;
private Node last;
public void enqueue(T item) {
Node node = new Node(item, null);
if (++N == 1) {
first = node;
} else {
last.next = node;
}
last = node;
}
public T dequeue() throws EmptyStackException {
if (N == 0) {
throw new EmptyStackException();
}
T item = first.item;
first = first.next;
if (--N == 0) {
last = null;
}
return item;
}
public int size() {
return N;
}
public boolean isEmpty() {
return N == 0;
}
private class Node {
T item;
Node next;
public Node() {
}
public Node(T item, Node next) {
this.item = item;
this.next = next;
}
}
}Das obige ist der detaillierte Inhalt vonWie implementiert man einen ungerichteten Graphen in Java?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!