
Heim >Backend-Entwicklung >Python-Tutorial >In Python integrierte Typ-Diktat-Quellcode-Analyse
In Python integrierte Typ-Diktat-Quellcode-Analyse

- 王林nach vorne
- 2023-04-24 12:01:071837Durchsuche
Detailliertes Verständnis des integrierten Python-Typs – dict
Hinweis: Dieser Artikel basiert auf den im Tutorial aufgezeichneten Notizen, da für den Nachdruck das Ausfüllen des Links erforderlich ist Ist dies nicht der Fall, wird das Original ausgefüllt, wenn ein Verstoß vorliegt.
In diesem Teil von „Detailliertes Verständnis der integrierten Typen von Python“ werden Sie aus der Perspektive des Quellcodes in verschiedene häufig verwendete integrierte Typen in Python eingeführt.
Dict ist einer der am häufigsten verwendeten integrierten Typen in der täglichen Entwicklung, und der Betrieb der virtuellen Python-Maschine hängt ebenfalls stark von dict-Objekten ab. Die Beherrschung des zugrunde liegenden Wissens von dict sollte hilfreich sein, unabhängig davon, ob es darum geht, das Grundwissen über Datenstrukturen zu verstehen oder die Entwicklungseffizienz zu verbessern.
1 Ausführungseffizienz
Ob Hashmap in Java oder Diktat in Python, beides sind sehr effiziente Datenstrukturen. Hashmap ist auch ein grundlegender Testpunkt in Java-Interviews: Array + verknüpfte Liste + rot-schwarze Baum-Hash-Tabelle, was sehr zeiteffizient ist. In ähnlicher Weise weist dict in Python aufgrund der zugrunde liegenden Hash-Tabellenstruktur auch eine durchschnittliche Komplexität von O(1) (im schlimmsten Fall O(n)) für Operationen wie Einfügen, Löschen und Suchen auf. Hier vergleichen wir Liste und Vorhersage, um zu sehen, wie groß der Unterschied in der Sucheffizienz zwischen den beiden ist: (Die Daten stammen aus dem Originalartikel, Sie können sie selbst testen)
| Containermaßstab | Skalenwachstumskoeffizient | Diktieren Sie den Zeitverbrauch. | Diktieren Sie den zeitaufwändigen Wachstumskoeffizienten s | 1. 1 0 | 0,000216s | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3,679s | 102,19 | 1000000 | 1000 | 0,000382s | |||||||||||||||||||
| 48,044s | 1335,56 |
2 内部结构2.1 PyDictObject
dict对象在Python内部由结构体PyDictObject表示,源码如下: typedef struct {
PyObject_HEAD
/* Number of items in the dictionary */
Py_ssize_t ma_used;
/* Dictionary version: globally unique, value change each time
the dictionary is modified */
uint64_t ma_version_tag;
PyDictKeysObject *ma_keys;
/* If ma_values is NULL, the table is "combined": keys and values
are stored in ma_keys.
If ma_values is not NULL, the table is splitted:
keys are stored in ma_keys and values are stored in ma_values */
PyObject **ma_values;
} PyDictObject;源码分析:
2.2 PyDictKeysObject从PyDictObject的源码中可以看到,相关的哈希表是通过PyDictKeysObject来实现的,源码如下: struct _dictkeysobject {
Py_ssize_t dk_refcnt;
/* Size of the hash table (dk_indices). It must be a power of 2. */
Py_ssize_t dk_size;
/* Function to lookup in the hash table (dk_indices):
- lookdict(): general-purpose, and may return DKIX_ERROR if (and
only if) a comparison raises an exception.
- lookdict_unicode(): specialized to Unicode string keys, comparison of
which can never raise an exception; that function can never return
DKIX_ERROR.
- lookdict_unicode_nodummy(): similar to lookdict_unicode() but further
specialized for Unicode string keys that cannot be the <dummy> value.
- lookdict_split(): Version of lookdict() for split tables. */
dict_lookup_func dk_lookup;
/* Number of usable entries in dk_entries. */
Py_ssize_t dk_usable;
/* Number of used entries in dk_entries. */
Py_ssize_t dk_nentries;
/* Actual hash table of dk_size entries. It holds indices in dk_entries,
or DKIX_EMPTY(-1) or DKIX_DUMMY(-2).
Indices must be: 0 <= indice < USABLE_FRACTION(dk_size).
The size in bytes of an indice depends on dk_size:
- 1 byte if dk_size <= 0xff (char*)
- 2 bytes if dk_size <= 0xffff (int16_t*)
- 4 bytes if dk_size <= 0xffffffff (int32_t*)
- 8 bytes otherwise (int64_t*)
Dynamically sized, SIZEOF_VOID_P is minimum. */
char dk_indices[]; /* char is required to avoid strict aliasing. */
/* "PyDictKeyEntry dk_entries[dk_usable];" array follows:
see the DK_ENTRIES() macro */
};源码分析:
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;
ma_version_tag: Die aktuelle Versionsnummer des Objekts, jedes Mal aktualisiert, wenn es geändert wird (Version Die Nummer kommt mir in der Geschäftsentwicklung ziemlich häufig vor) Typ ist PyDictKeysObject #🎜🎜 #ma_values: zeigt auf ein Array, das aus allen Wertobjekten im Split-Modus besteht (im kombinierten Modus wird der Wert in ma_keys und ma_values gespeichert ist zu diesem Zeitpunkt leer)
dk_size: Hash-Tabellengröße, muss eine ganzzahlige Potenz von 2 sein, damit modulare Operationen in Bitoperationen optimiert werden können (Sie können es lernen und mit tatsächlichen Geschäftsanwendungen kombinieren)# 🎜🎜# dk_lookup: Hash-Lookup-Funktionszeiger, Sie können die optimale Funktion entsprechend auswählen aktueller Status des Diktats
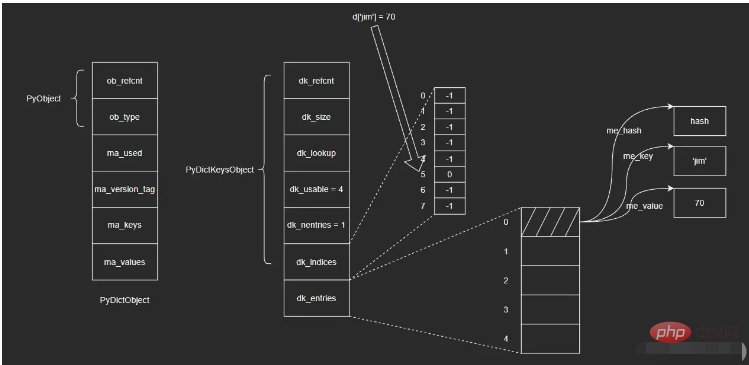
dk_usable: Anzahl der verfügbaren Schlüssel-Wert-Paare array# 🎜🎜# dk_nentries: die Zahl der verwendeten Schlüssel-Wert-Paar-Arrays dk_indices: die Startadresse der Hash-Tabelle. Auf die Hash-Tabelle folgt das Schlüssel-Wert-Paar-Array dk_entries dk_entries ist PyDictKeyEntry 2.3 PyDictKeyEntryWie Sie aus PyDictKeysObject ersehen können, wird die Schlüssel-Wert-Paarstruktur durch PyDictKeyEntry implementiert lautet wie folgt:# define USABLE_FRACTION(n) (((n) << 1)/3)Quellcode-Analyse: #🎜🎜##🎜🎜##🎜🎜##🎜🎜#me_hash: Hashwert des Schlüsselobjekts, um wiederholte Berechnungen zu vermeiden#🎜🎜# #🎜🎜##🎜🎜##🎜🎜#me_key: Schlüsselobjektzeiger#🎜🎜##🎜🎜##🎜🎜##🎜🎜#me_value: Wertobjektzeiger#🎜🎜# #🎜🎜##🎜🎜# #🎜🎜#2.4 Abbildungen und Beispiele #🎜🎜##🎜🎜#Das Hash-Tabellensymbol in dict lautet wie folgt: #🎜🎜##🎜🎜##🎜🎜##🎜🎜# #🎜🎜#Der wahre Kern von Das Diktatobjekt liegt in PyDictKeysObject, das zwei Schlüsselarrays enthält: eines ist das Hash-Index-Array dk_indices und das andere ist das Schlüssel-Wert-Paar-Array dk_entries. Die von dict verwalteten Schlüssel-Wert-Paare werden im Schlüssel-Wert-Paar-Array in der Reihenfolge „Wer zuerst kommt, mahlt zuerst“ gespeichert, und der entsprechende Slot des Hash-Index-Arrays speichert die Position des Schlüssel-Wert-Paares im Array. #🎜🎜##🎜🎜# Nehmen Sie das Einfügen von {'jim': 70} in das leere Diktatobjekt d. Die Schritte sind wie folgt: #🎜🎜##🎜🎜#i Speichern Sie das Schlüssel-Wert-Paar unter das Ende des dk_entries-Arrays (hier Das Array ist zunächst leer und das Ende ist die Position, an der der Array-Index „0“ ist); #🎜🎜##🎜🎜#ii Berechnen Sie den Hash-Wert des Schlüsselobjekts 'jim ' und nehmen Sie die richtigen 3 Ziffern (d. h. Modulo 8). Die Länge des dk_indices-Arrays beträgt 8. Wie bereits erwähnt, kann die Modulo-Operation in eine Bit-Operation umgewandelt werden, indem die Array-Länge als ganzzahlige Potenz von 2 beibehalten wird. Hier nur Nehmen Sie die rechten 3 Ziffern an. Nehmen Sie an, dass der endgültige Wert 5 ist, was der Position des Index 5 im Array dk_indices entspricht „0“ im dk_entries-Array und wird im Hash-Index-Array dk_indices mit der tiefgestellten Position 5 gespeichert. #🎜🎜##🎜🎜#Führen Sie den Suchvorgang aus. Die Schritte sind wie folgt: #🎜🎜##🎜🎜#i Berechnen Sie den Hash-Wert des Schlüsselobjekts „jim“ und nehmen Sie die richtigen 3 Ziffern, um den zu erhalten Hash-Index-Array des Schlüssels Index 5 in dk_indices; #🎜🎜##🎜🎜#ii Suchen Sie die Position mit Index 5 im Hash-Index-Array dk_indices und entnehmen Sie den dort gespeicherten Wert - 0, also den Schlüssel- Wertepaar im dk_entries-Array Location; iii. 找到dk_entries数组下标为0的位置,取出值对象me_value。(这里我不确定在查找时会不会再次验证me_key是否为'jim',感兴趣的读者可以自行去查看一下相应的源码) 这里涉及到的结构比较多,直接看图示可能也不是很清晰,但是通过上面的插入和查找两个过程,应该可以帮助大家理清楚这里的关系。我个人觉得这里的设计还是很巧妙的,可能暂时还看不出来为什么这么做,后续我会继续为大家介绍。 3 容量策略示例: >>> import sys
>>> d1 = {}
>>> sys.getsizeof(d1)
240
>>> d2 = {'a': 1}
>>> sys.getsizeof(d1)
240可以看到,dict和list在容量策略上有所不同,Python会为空dict对象也分配一定的容量,而对空list对象并不会预先分配底层数组。下面简单介绍下dict的容量策略。 哈希表越密集,哈希冲突则越频繁,性能也就越差。因此,哈希表必须是一种稀疏的表结构,越稀疏则性能越好。但是由于内存开销的制约,哈希表不可能无限度稀疏,需要在时间和空间上进行权衡。实践经验表明,一个1/3到2/3满的哈希表,性能是较为理想的——以相对合理的内存换取相对高效的执行性能。 为保证哈希表的稀疏程度,进而控制哈希冲突频率,Python底层通过USABLE_FRACTION宏将哈希表内元素控制在2/3以内。USABLE_FRACTION根据哈希表的规模n,计算哈希表可存储元素个数,也就是键值对数组dk_entries的长度。以长度为8的哈希表为例,最多可以保持5个键值对,超出则需要扩容。USABLE_FRACTION是一个非常重要的宏定义: # define USABLE_FRACTION(n) (((n) << 1)/3) 此外,哈希表的规模一定是2的整数次幂,即Python对dict采用翻倍扩容策略。 4 内存优化在Python3.6之前,dict的哈希表并没有分成两个数组实现,而是由一个键值对数组(结构和PyDictKeyEntry一样,但是会有很多“空位”)实现,这个数组也承担哈希索引的角色: entries = [ ['--', '--', '--'],
[hash, key, value],
['--', '--', '--'],
[hash, key, value],
['--', '--', '--'],
]哈希值直接在数组中定位到对应的下标,找到对应的键值对,这样一步就能完成。Python3.6之后通过两个数组来实现则是出于对内存的考量。
对比一下两种方式在内存上的开销:
5 dict中哈希表这一节主要介绍哈希函数、哈希冲突、哈希攻击以及删除操作相关的知识点。 5.1 哈希函数根据哈希表性质,键对象必须满足以下两个条件,否则哈希表便不能正常工作: i. 哈希值在对象的整个生命周期内不能改变 ii. 可比较,并且比较结果相等的两个对象的哈希值必须相同 满足这两个条件的对象便是可哈希(hashable)对象,只有可哈希对象才可作为哈希表的键。因此,像dict、set等底层由哈希表实现的容器对象,其键对象必须是可哈希对象。在Python的内建类型中,不可变对象都是可哈希对象,而可变对象则不是: >>> hash([])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
hash([])
TypeError: unhashable type: 'list'dict、list等不可哈希对象不能作为哈希表的键: >>> {[]: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
{[]: 'list is not hashable'}
TypeError: unhashable type: 'list'
>>> {{}: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
{{}: 'list is not hashable'}
TypeError: unhashable type: 'dict'而用户自定义的对象默认便是可哈希对象,对象哈希值由对象地址计算而来,且任意两个不同对象均不相等: >>> class A:
pass
>>> a = A()
>>> b = A()
>>> hash(a), hash(b)
(160513133217, 160513132857)
>>>a == b
False
>>> a is b
False那么,哈希值是如何计算的呢?答案是——哈希函数。哈希值计算作为对象行为的一种,会由各个类型对象的tp_hash指针指向的哈希函数来计算。对于用户自定义的对象,可以实现__hash__()魔法方法,重写哈希值计算方法。 5.2 哈希冲突理想的哈希函数必须保证哈希值尽量均匀地分布于整个哈希空间,越是接近的值,其哈希值差别应该越大。而一方面,不同的对象哈希值有可能相同;另一方面,与哈希值空间相比,哈希表的槽位是非常有限的。因此,存在多个键被映射到哈希索引同一槽位的可能性,这就是哈希冲突。
这是Python采用的方法。将数据直接保存于哈希槽位中,如果槽位已被占用,则尝试另一个。一般而言,第i次尝试会在首槽位基础上加上一定的偏移量di。因此,探测方法因函数di而异。常见的方法有线性探测(linear probing)以及平方探测(quadratic probing)
线性探测和平方探测很简单,但同时也存在一定的问题:固定的探测序列会加大冲突的概率。Python对此进行了优化,探测函数参考对象哈希值,生成不同的探测序列,进一步降低哈希冲突的可能性。Python探测方法在lookdict()函数中实现,关键代码如下: static Py_ssize_t _Py_HOT_FUNCTION
lookdict(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject **value_addr)
{
size_t i, mask, perturb;
PyDictKeysObject *dk;
PyDictKeyEntry *ep0;
top:
dk = mp->ma_keys;
ep0 = DK_ENTRIES(dk);
mask = DK_MASK(dk);
perturb = hash;
i = (size_t)hash & mask;
for (;;) {
Py_ssize_t ix = dk_get_index(dk, i);
// 省略键比较部分代码
// 计算下个槽位
// 由于参考了对象哈希值,探测序列因哈希值而异
perturb >>= PERTURB_SHIFT;
i = (i*5 + perturb + 1) & mask;
}
Py_UNREACHABLE();
}源码分析:第20~21行,探测序列涉及到的参数是与对象的哈希值相关的,具体计算方式大家可以看下源码,这里我就不赘述了。 5.3 哈希攻击Python在3.3之前,哈希算法只根据对象本身计算哈希值。因此,只要Python解释器相同,对象哈希值也肯定相同。执行Python2解释器的两个交互式终端,示例如下:(来自原文章) >>> import os >>> os.getpid() 2878 >>> hash('fashion') 3629822619130952182 >>> import os >>> os.getpid() 2915 >>> hash('fashion') 3629822619130952182 如果我们构造出大量哈希值相同的key,并提交给服务器:例如向一台Python2Web服务器post一个json数据,数据包含大量的key,这些key的哈希值均相同。这意味哈希表将频繁发生哈希冲突,性能由O(1)直接下降到了O(n),这就是哈希攻击。
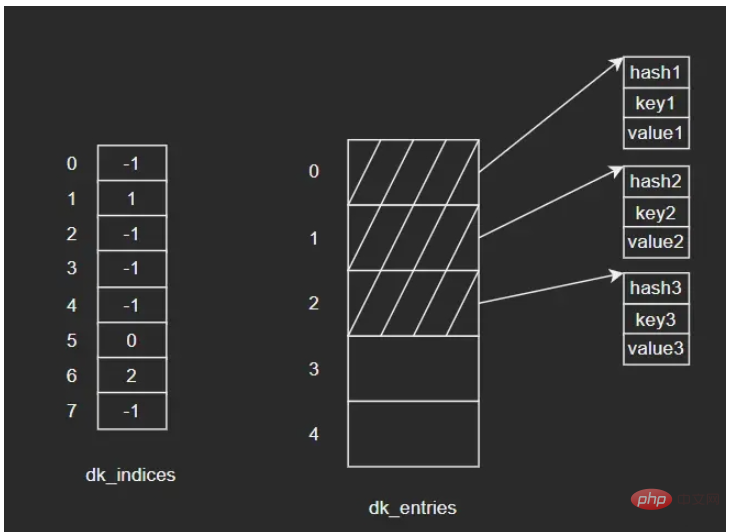
5.4 删除操作示例:向dict依次插入三组键值对,键对象依次为key1、key2、key3,其中key2和key3发生了哈希冲突,经过处理后重新定位到dk_indices[6]的位置。图示如下:
如果要删除key2,假设我们将key2对应的dk_indices[1]设置为-1,那么此时我们查询key3时就会出错——因为key3初始对应的操作就是dk_indices[1],只是发生了哈希冲突蔡最终分配到了dk_indices[6],而此时dk_indices[1]的值为-1,就会导致查询的结果是key3不存在。因此,在删除元素时,会将对应的dk_indices设置为一个特殊的值DUMMY,避免中断哈希探索链(也就是通过标志位来解决,很常见的做法)。 哈希槽位状态常量如下: #define DKIX_EMPTY (-1) #define DKIX_DUMMY (-2) /* Used internally */ #define DKIX_ERROR (-3)
5.5 问题删除操作不会将dk_entries中的条目回收重用,随着插入地进行,dk_entries最终会耗尽,Python将创建一个新的PyDictKeysObject,并将数据拷贝过去。新PyDictKeysObject尺寸由 static int
dictresize(PyDictObject *mp, Py_ssize_t minsize)
{
/* Find the smallest table size > minused. */
for (newsize = PyDict_MINSIZE;
newsize < minsize && newsize > 0;
newsize <<= 1)
;
// ...
}源码分析: 如果此前发生了大量删除(没记错的话是可用个数为0时才会缩容,这里大家可以自行看下源码),剩余元素个数减少很多,PyDictKeysObject尺寸就会变小,此时就会完成缩容(大家还记得前面提到过的dk_usable,dk_nentries等字段吗,没记错的话它们在这里就发挥作用了,大家可以自行看下源码)。总之,缩容不会在删除的时候立刻触发,而是在当插入并且dk_entries耗尽时才会触发。 函数dictresize()的参数Py_ssize_t minsize由GROWTH_RATE宏传入: #define GROWTH_RATE(d) ((d)->ma_used*3)
static int
insertion_resize(PyDictObject *mp)
{
return dictresize(mp, GROWTH_RATE(mp));
}
|
Das obige ist der detaillierte Inhalt vonIn Python integrierte Typ-Diktat-Quellcode-Analyse. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!