
Heim >Java >javaLernprogramm >Anwendungsszenarien und Techniken von Java-Multithreading und IO-Streams
Anwendungsszenarien und Techniken von Java-Multithreading und IO-Streams

- PHPznach vorne
- 2023-04-22 12:10:20803Durchsuche
Java-Multithreading- und Streaming-Anwendungen
Ich habe kürzlich ein Beispiel für die Verwendung von Multithreading zum Herunterladen von Dateien gesehen. Ich fand es sehr interessant, also habe ich es untersucht und versucht, Multithreading zum lokalen Kopieren von Dateien zu verwenden. Nachdem ich mit dem Schreiben fertig war, stellte ich fest, dass die beiden tatsächlich sehr ähnlich sind. Unabhängig davon, ob es sich um das lokale Kopieren von Dateien oder das Herunterladen von Netzwerk-Multithreads handelt, ist die Verwendung von Streams dieselbe. Bei lokalen Dateisystemen wird der Eingabestream aus einer Datei im lokalen Dateisystem abgerufen. Bei Netzwerkressourcen wird er aus einer Datei auf einem Remote-Server abgerufen.
Hinweis: Obwohl viele Leute diesen Multithread-Downloadcode geschrieben haben, versteht ihn vielleicht nicht jeder, deshalb werde ich ihn hier noch einmal schreiben, ha.
Ein offensichtlicher Vorteil der Verwendung von Multithreading ist: Verwenden Sie die CPU im Leerlauf, um die Geschwindigkeit zu erhöhen. Beachten Sie jedoch, dass es umso besser ist, je mehr Threads es gibt. Obwohl es den Anschein hat, dass n Threads zusammen heruntergeladen werden, lädt jeder Thread einen kleinen Teil herunter und die Downloadzeit beträgt 1/n. Das ist ein sehr einfaches Verständnis, so wie es für eine Person 100 Tage dauert, ein Haus zu bauen, für 10.000 Menschen jedoch nur 1/10 Tag? (Das ist übertrieben, haha!)
Das Wechseln zwischen Threads erfordert auch System-Overhead und die Anzahl der Threads muss in einem angemessenen Bereich gesteuert werden.
RamdomAccessFile
Diese Klasse ist relativ einzigartig. Sie kann Daten aus Dateien lesen und in Dateien schreiben. Es handelt sich jedoch nicht um eine Unterklasse von OutputStream und InputStream, sondern um eine Klasse, die diese beiden Schnittstellen DataOutput und DataInput implementiert.
Einführung in die API:
Instanzen dieser Klasse unterstützen das Lesen und Schreiben von Direktzugriffsdateien. Der zufällige Zugriff auf eine Datei verhält sich wie eine große Anzahl von Bytes, die im Dateisystem gespeichert werden. Es gibt eine Art Cursor oder Index in einem impliziten Array, der als Dateizeiger bezeichnet wird. Eingabeoperationen lesen Bytes beginnend beim Dateizeiger und erweitern den Dateizeiger über die gelesenen Bytes hinaus. Die Ausgabeoperation ist auch verfügbar, wenn die Direktzugriffsdatei im Lese-/Schreibmodus erstellt wird; die Ausgabeoperation schreibt Bytes beginnend beim Dateizeiger und setzt den Dateizeiger auf die geschriebenen Bytes vor. Ausgabeoperationen, die auf die aktuelle Seite eines impliziten Arrays schreiben, bewirken, dass das Array erweitert wird. Der Dateizeiger kann von der getFilePointer-Methode gelesen und von der seek-Methode gesetzt werden.
Das Wichtigste an dieser Klasse ist also die Suchmethode. Mit der Suchmethode können Sie die Schreibposition steuern, sodass es viel einfacher ist, Multithreading zu implementieren. Unabhängig davon, ob es sich um das lokale Kopieren von Dateien oder das Herunterladen von Netzwerk-Multithreads handelt, ist diese Klasse erforderlich.
Die konkrete Idee ist: Verwenden Sie zuerst RandomAccessFile, um ein Dateiobjekt zu erstellen, und legen Sie dann die Größe dieser Datei fest. (Ja, die Dateigröße kann direkt eingestellt werden.) Legen Sie fest, dass diese Datei mit der Datei identisch ist, die Sie kopieren oder herunterladen möchten. (Obwohl wir keine Daten in diese Datei geschrieben haben, wurde die Datei erstellt.) Teilen Sie die Datei in mehrere Teile und verwenden Sie Threads, um den Inhalt jedes Teils zu kopieren oder herunterzuladen.
Dies ähnelt in gewisser Weise dem Überschreiben einer Datei. Wenn eine vorhandene Datei beginnt, Daten vom Kopf der Datei zu schreiben und bis zum Ende der Datei zu schreiben, ist die ursprüngliche Datei nicht mehr vorhanden und wird zum neuen geschriebenen Dokument.
Stellen Sie die Dateigröße ein:
private static void createOutputFile(File file, long length) throws IOException {
try (
RandomAccessFile raf = new RandomAccessFile(file, "rw")){
raf.setLength(length);
}
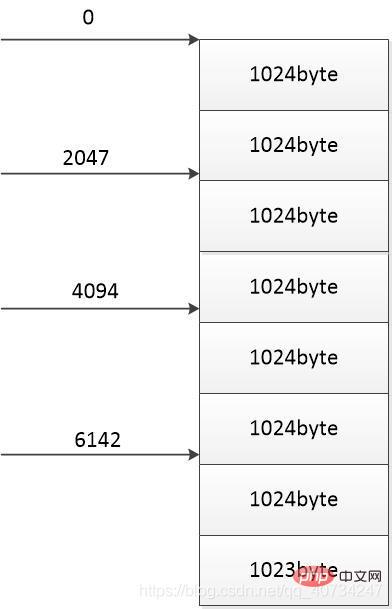
}Verwenden Sie Bilder zur Veranschaulichung: Dieses Bild stellt eine Datei mit einer Größe von 8191 Bytes dar: Die Größe jedes Teils beträgt: 8191 / 4 = 2047 Bytes
Teilen Sie diese Datei in Vier Teile, jeder Teil verwendet einen Thread zum Kopieren oder Herunterladen, und jeder Pfeil stellt die Startposition des Downloads eines Threads dar. Ich habe den letzten Teil absichtlich nicht auf 1024 Bytes eingestellt, da Dateien selten genau durch 1024 Bytes teilbar sind. (Der Grund, warum ich 1024 Byte verwende, liegt darin, dass ich jedes Mal 1024 Byte lese. Wenn 1024 Byte gelesen werden, wird andernfalls die entsprechende Anzahl gelesener Bytes geschrieben.)
Laut diesem Diagramm lädt jeder Thread 2047 Bytes herunter, dann beträgt die Gesamtzahl der heruntergeladenen Bytes: 2047 * 4 = 8188 Bytes Dies schafft also ein Problem. Die Anzahl der Die Anzahl der heruntergeladenen Bytes ist geringer als die Gesamtzahl der Bytes. Dies stellt ein Problem dar, daher muss die Anzahl der heruntergeladenen Bytes größer sein als die Gesamtzahl der Bytes. (Es spielt keine Rolle, ob es mehr sind, da die zusätzlich heruntergeladenen Teile durch die späteren Teile überschrieben werden und keine Probleme verursachen.)
Die Größe jedes Teils sollte also sein: 8191 / 4 + 1 = 2048 Bytes. (Auf diese Weise übersteigt die Summe der Größen der vier Teile die Gesamtgröße und es kommt zu keinem Datenverlust.)
Das Hinzufügen von 1 ist hier also unbedingt erforderlich.
long size = len / FileCopyUtil.THREAD_NUM + 1;
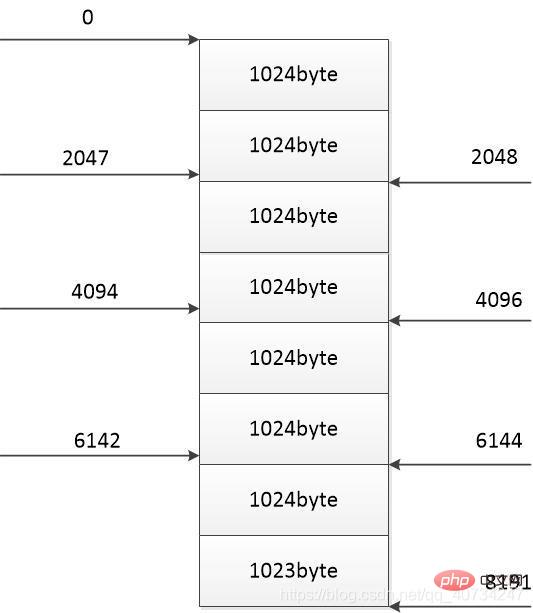
Die Position, an der jeder Thread-Download abgeschlossen ist (rechts) Jeder Thread kopiert nur den Teil des Herunterladens selbst, sodass nicht der gesamte Inhalt heruntergeladen werden muss, sondern die Dateidaten gelesen und geschrieben werden Dem Aktenteil wird ein weiteres Urteil hinzugefügt.
这里增加一个计数器:curlen。它表示是当前复制或者下载的长度,然后每次读取后和 size(每部分的大小)进行比较,如果 curlen 大于 size 就表示相应的部分下载完成了(当然了,这些都要在数据没有读取完的条件下判断)。
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(targetFile));
RandomAccessFile raf = new RandomAccessFile(outputFile, "rw")){
bis.skip(position);
raf.seek(position);
int hasRead = 0;
byte[] b = new byte[1024];
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position+" "+curlen+" "+size);
} catch (IOException e) {
e.printStackTrace();
}
还有需要注意的是,每个线程下载的时候都要: 1. 输出流设置文件指针的位置。 2. 输入流跳过不需要读取的字节。
这是很重要的一步,应该是很好理解的。
bis.skip(position); raf.seek(position);
多线程本地文件复制(完整代码)
package dragon;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
/**
* 用于进行文件复制,但不是常规的文件复制 。
* 准备仿照疯狂Java,写一个多线程的文件复制工具。
* 即可以本地复制和网络复制
* */
/**
* 设计思路:
* 获取目标文件的大小,然后设置复制文件的大小(这样做是有好处的),
* 然后使用将文件分为 n 分,使用 n 个线程同时进行复制(这里我将 n 取为 4)。
*
* 可以进一步拓展:
* 加强为断点复制功能,即程序中断以后,
* 仍然可以继续从上次位置恢复复制,减少不必要的重复开销
* */
public class FileCopyUtil {
//设置一个常量,复制线程的数量
private static final int THREAD_NUM = 4;
private FileCopyUtil() {}
/**
* @param targetPath 目标文件的路径
* @param outputPath 复制输出文件的路径
* @throws IOException
* */
public static void transferFile(String targetPath, String outputPath) throws IOException {
File targetFile = new File(targetPath);
File outputFilePath = new File(outputPath);
if (!targetFile.exists() || targetFile.isDirectory()) { //目标文件不存在,或者是一个文件夹,则抛出异常
throw new FileNotFoundException("目标文件不存在:"+targetPath);
}
if (!outputFilePath.exists()) { //如果输出文件夹不存在,将会尝试创建,创建失败,则抛出异常。
if(!outputFilePath.mkdir()) {
throw new FileNotFoundException("无法创建输出文件:"+outputPath);
}
}
long len = targetFile.length();
File outputFile = new File(outputFilePath, "copy"+targetFile.getName());
createOutputFile(outputFile, len); //创建输出文件,设置好大小。
long[] position = new long[4];
//每一个线程需要复制文件的起点
long size = len / FileCopyUtil.THREAD_NUM + 1;
for (int i = 0; i < FileCopyUtil.THREAD_NUM; i++) {
position[i] = i*size;
copyThread(i, position[i], size, targetFile, outputFile);
}
}
//创建输出文件,设置好大小。
private static void createOutputFile(File file, long length) throws IOException {
try (
RandomAccessFile raf = new RandomAccessFile(file, "rw")){
raf.setLength(length);
}
}
private static void copyThread(int i, long position, long size, File targetFile, File outputFile) {
int n = i; //Lambda 表达式的限制,无法使用变量。
new Thread(()->{
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(targetFile));
RandomAccessFile raf = new RandomAccessFile(outputFile, "rw")){
bis.skip(position); //跳过不需要读取的字节数,注意只能先后跳
raf.seek(position); //跳到需要写入的位置,没有这句话,会出错,但是很难改。
int hasRead = 0;
byte[] b = new byte[1024];
/**
* 注意,每个线程只是读取一部分数据,不能只以 -1 作为循环结束的条件
* 循环退出条件应该是两个,即写入的字节数大于需要读取的字节数 或者 文件读取结束(最后一个线程读取到文件末尾)
*/
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position+" "+curlen+" "+size);
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}多线程网络下载(完整代码)
package dragon;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.net.URL;
import java.net.URLConnection;
/*
* 多线程下载文件:
* 通过一个 URL 获取文件输入流,使用多线程技术下载这个文件。
* */
public class FileDownloadUtil {
//下载线程数
private static final int THREAD_NUM = 4;
/**
* @param url 资源位置
* @param output 输出路径
* @throws IOException
* */
public static void transferFile(String url, String output) throws IOException {
init(output);
URL resource = new URL(url);
URLConnection connection = resource.openConnection();
//获取文件类型
String type = connection.getContentType();
if (type != null) {
type = "."+type.split("/")[1];
} else {
type = "";
}
//创建文件,并设置长度。
long len = connection.getContentLength();
String filename = System.currentTimeMillis()+type;
try (RandomAccessFile raf = new RandomAccessFile(new File(output, filename), "rw")){
raf.setLength(len);
}
//为每一个线程分配相应的下载其实位置
long size = len / THREAD_NUM + 1;
long[] position = new long[THREAD_NUM];
File downloadFile = new File(output, filename);
//开始下载文件: 4个线程
download(url, downloadFile, position, size);
}
private static void download(String url, File file, long[] position, long size) throws IOException {
//开始下载文件: 4个线程
for (int i = 0 ; i < THREAD_NUM; i++) {
position[i] = i * size; //每一个线程下载的起始位置
int n = i; // Lambda 表达式的限制,无法使用变量
new Thread(()->{
URL resource = null;
URLConnection connection = null;
try {
resource = new URL(url);
connection = resource.openConnection();
} catch (IOException e) {
e.printStackTrace();
}
try (
BufferedInputStream bis = new BufferedInputStream(connection.getInputStream());
RandomAccessFile raf = new RandomAccessFile(file, "rw")){ //每个流一旦关闭,就不能打开了
raf.seek(position[n]); //跳到需要下载的位置
bis.skip(position[n]); //跳过不需要下载的部分
int hasRead = 0;
byte[] b = new byte[1024];
long curlen = 0;
while(curlen < size && (hasRead = bis.read(b)) != -1) {
raf.write(b, 0, hasRead);
curlen += (long)hasRead;
}
System.out.println(n+" "+position[n]+" "+curlen+" "+size);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}) .start();
}
}
private static void init(String output) throws FileNotFoundException {
File path = new File(output);
if (!path.exists()) {
if (!path.mkdirs()) {
throw new FileNotFoundException("无法创建输出路径:"+output);
}
} else if (path.isFile()) {
throw new FileNotFoundException("输出路径不是一个目录:"+output);
}
}
}测试代码及结果
因为这个多线程文件复制和多线程下载是很相似的,所以就放在一起测试了。我也想将两个写在一个类里面,这样可以做成方法的重载调用。 文件复制的第一个参数可以是 String 或者 URI。 使用这个作为目标文件的参数。
public File(URI uri)
网络文件下载的第一个参数,可以使用 String 或者是 URL。 不过,因为先写的这个文件复制,后写的多线程下载,就没有做这部分。不过现在这样功能也达到了,可以进行本地文件的复制(多线程)和网络文件的下载(多线程)。
package dragon;
import java.io.IOException;
public class FileCopyTest {
public static void main(String[] args) throws IOException {
//复制文件
long start = System.currentTimeMillis();
try {
FileCopyUtil.transferFile("D:\\DB\\download\\timg.jfif", "D:\\DBC");
} catch (IOException e) {
e.printStackTrace();
}
long time = System.currentTimeMillis()-start;
System.out.println("time: "+time);
//下载文件
start = System.currentTimeMillis();
FileDownloadUtil.transferFile("https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1578151056184&di=594a34f05f3587c31d9377a643ddd72e&imgtype=0&src=http%3A%2F%2Fn.sinaimg.cn%2Fsinacn%2Fw1600h2000%2F20180113%2F0bdc-fyqrewh6850115.jpg", "D:\\DB\\download");
System.out.println("time: "+(System.currentTimeMillis()-start));
}
}运行截图: 注意:这里这个时间并不是复制和下载需要的时间,实际上它没有这个功能!
注意:虽然两部分代码是相同的,但是第三列数字,却不是完全相同的,这个似乎是因为本地和网络得区别吧。但是最后得文件是完全相同的,没有问题得。(我本地文件复制得是网络下载得那张图片,使用图片进行测试有一个好处,就是如果错了一点(字节数目不对),这个图片基本上就会产生问题。)
产生错误之后的图片: 图片无法正常显示,会出现很多的问题,这就说明一定是代码写错了。
Das obige ist der detaillierte Inhalt vonAnwendungsszenarien und Techniken von Java-Multithreading und IO-Streams. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!