
Heim >Backend-Entwicklung >Python-Tutorial >Lernen Sie Python, um ein autonomes Fahrsystem zu implementieren
Lernen Sie Python, um ein autonomes Fahrsystem zu implementieren

- 王林nach vorne
- 2023-04-21 16:58:081432Durchsuche

Installationsumgebung
gym ist ein Toolkit zum Entwickeln und Vergleichen von Reinforcement-Learning-Algorithmen. Die Installation der Gym-Bibliothek und ihrer Unterszenarien ist relativ einfach.
Fitnessstudio installieren:
pip install gym
Installieren Sie das autonome Fahrmodul. Hier verwenden wir das von Edouard Leurent auf Github veröffentlichte Paket Highway-env:
pip install --user git+https://github.com/eleurent/highway-env
Es enthält 6 Szenen:
- Highway - „highway-v0“
- Zusammenführen - „merge-v0“
- Kreisverkehr – „roundabout-v0“
- Parken – „parking-v0“
- Kreuzung – „intersection-v0“
- Rennstrecke – „racetrack-v0“
Detaillierte Dokumentation kann sein finden Sie hier:
https://www.php.cn/link/c0fda89ebd645bd7cea60fcbb5960309
Konfigurieren Sie die Umgebung
Nach der Installation können Sie mit dem Code experimentieren (mit Nehmen Sie die Autobahnszene als Beispiel) :
import gym
import highway_env
%matplotlib inline
env = gym.make('highway-v0')
env.reset()
for _ in range(3):
action = env.action_type.actions_indexes["IDLE"]
obs, reward, done, info = env.step(action)
env.render()
Nach dem Ausführen wird die folgende Szene im Simulator generiert:
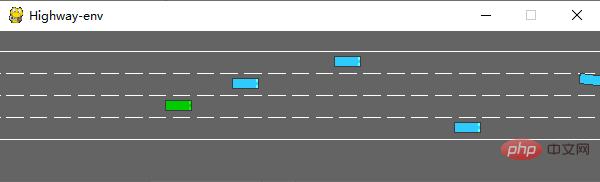
Die Env-Klasse verfügt über viele Parameter, die konfiguriert werden können. Einzelheiten finden Sie im Originaldokument.
Trainingsmodell
1. Datenverarbeitung
(1) Es sind keine Sensoren im Paket state
highway-env definiert. Alle Zustände (Beobachtungen) des Fahrzeugs werden aus dem zugrunde liegenden Code gelesen, was eine Menge vorläufiger Arbeit erspart arbeiten. Der Dokumentation zufolge verfügt state (ovservations) über drei Ausgabemethoden: Kinematik, Graustufenbild und Belegungsraster.
Kinematik
Geben Sie eine Matrix von V*F aus, V stellt die Anzahl der zu beobachtenden Fahrzeuge dar (einschließlich des Ego-Fahrzeugs selbst) und F stellt die Anzahl der zu zählenden Merkmale dar. Beispiel:
Die Daten werden bei der Generierung standardmäßig normalisiert und der Wertebereich ist: [100, 100, 20, 20]. Sie können die Fahrzeugattribute außer dem Ego-Fahrzeug auch auf die absoluten Koordinaten der Karte oder festlegen die relativen Koordinaten des Ego-Fahrzeugs.
Beim Definieren der Umgebung müssen Sie die Parameter der Funktion festlegen:
config =
{
"observation":
{
"type": "Kinematics",
#选取5辆车进行观察(包括ego vehicle)
"vehicles_count": 5,
#共7个特征
"features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"],
"features_range":
{
"x": [-100, 100],
"y": [-100, 100],
"vx": [-20, 20],
"vy": [-20, 20]
},
"absolute": False,
"order": "sorted"
},
"simulation_frequency": 8,# [Hz]
"policy_frequency": 2,# [Hz]
}
Graustufenbild
Erzeugen Sie ein B*H-Graustufenbild, W stellt die Bildbreite dar, H stellt die Bildhöhe dar
Belegungsraster
Generieren a Die dreidimensionale Matrix von WHF verwendet eine W*H-Tabelle, um die Fahrzeugbedingungen rund um das Ego-Fahrzeug darzustellen. Jedes Gitter enthält F-Merkmale.
(2) Aktion
Die Aktionen im Highway-Env-Paket sind in zwei Typen unterteilt: kontinuierlich und diskret. Die kontinuierliche Aktion kann die Werte von Gas und Lenkwinkel direkt definieren. Die diskrete Aktion enthält 5 Metaaktionen:
ACTIONS_ALL = {
0: 'LANE_LEFT',
1: 'IDLE',
2: 'LANE_RIGHT',
3: 'FASTER',
4: 'SLOWER'
}
(3) Belohnung
Das Highway-Env-Paket verwendet die gleiche Belohnungsfunktion mit Ausnahme der Parkszene:

Diese Funktion kann nur im Quellcode geändert werden und das Gewicht kann nur in der äußeren Ebene angepasst werden.
(Die Belohnungsfunktion der Parkszene ist im Originaldokument enthalten)
2. Erstellen Sie das Modell
DQN-Netzwerk. Zur Demonstration verwende ich die erste Zustandsdarstellungsmethode. Da die Menge der Zustandsdaten gering ist (5 Autos * 7 Features), können Sie die Verwendung von CNN ignorieren und die Größe [5,7] der zweidimensionalen Daten direkt in [1,35] konvertieren Modell ist 35. Die Ausgabe ist die Anzahl der diskreten Aktionen, insgesamt 5.
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as T
from torch import FloatTensor, LongTensor, ByteTensor
from collections import namedtuple
import random
Tensor = FloatTensor
EPSILON = 0# epsilon used for epsilon greedy approach
GAMMA = 0.9
TARGET_NETWORK_REPLACE_FREQ = 40 # How frequently target netowrk updates
MEMORY_CAPACITY = 100
BATCH_SIZE = 80
LR = 0.01 # learning rate
class DQNNet(nn.Module):
def __init__(self):
super(DQNNet,self).__init__()
self.linear1 = nn.Linear(35,35)
self.linear2 = nn.Linear(35,5)
def forward(self,s):
s=torch.FloatTensor(s)
s = s.view(s.size(0),1,35)
s = self.linear1(s)
s = self.linear2(s)
return s
class DQN(object):
def __init__(self):
self.net,self.target_net = DQNNet(),DQNNet()
self.learn_step_counter = 0
self.memory = []
self.position = 0
self.capacity = MEMORY_CAPACITY
self.optimizer = torch.optim.Adam(self.net.parameters(), lr=LR)
self.loss_func = nn.MSELoss()
def choose_action(self,s,e):
x=np.expand_dims(s, axis=0)
if np.random.uniform() < 1-e:
actions_value = self.net.forward(x)
action = torch.max(actions_value,-1)[1].data.numpy()
action = action.max()
else:
action = np.random.randint(0, 5)
return action
def push_memory(self, s, a, r, s_):
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.position] = Transition(torch.unsqueeze(torch.FloatTensor(s), 0),torch.unsqueeze(torch.FloatTensor(s_), 0),
torch.from_numpy(np.array([a])),torch.from_numpy(np.array([r],dtype='float32')))#
self.position = (self.position + 1) % self.capacity
def get_sample(self,batch_size):
sample = random.sample(self.memory,batch_size)
return sample
def learn(self):
if self.learn_step_counter % TARGET_NETWORK_REPLACE_FREQ == 0:
self.target_net.load_state_dict(self.net.state_dict())
self.learn_step_counter += 1
transitions = self.get_sample(BATCH_SIZE)
batch = Transition(*zip(*transitions))
b_s = Variable(torch.cat(batch.state))
b_s_ = Variable(torch.cat(batch.next_state))
b_a = Variable(torch.cat(batch.action))
b_r = Variable(torch.cat(batch.reward))
q_eval = self.net.forward(b_s).squeeze(1).gather(1,b_a.unsqueeze(1).to(torch.int64))
q_next = self.target_net.forward(b_s_).detach() #
q_target = b_r + GAMMA * q_next.squeeze(1).max(1)[0].view(BATCH_SIZE, 1).t()
loss = self.loss_func(q_eval, q_target.t())
self.optimizer.zero_grad() # reset the gradient to zero
loss.backward()
self.optimizer.step() # execute back propagation for one step
return loss
Transition = namedtuple('Transition',('state', 'next_state','action', 'reward'))
3. Ergebnisse ausführen
Nachdem die einzelnen Teile abgeschlossen sind, können die Modelle zum Trainieren des Modells kombiniert werden. Der Prozess ähnelt dem von CARLA, daher werde ich nicht auf Details eingehen.
Initialisierungsumgebung (fügen Sie einfach die DQN-Klasse hinzu):
import gym
import highway_env
from matplotlib import pyplot as plt
import numpy as np
import time
config =
{
"observation":
{
"type": "Kinematics",
"vehicles_count": 5,
"features": ["presence", "x", "y", "vx", "vy", "cos_h", "sin_h"],
"features_range":
{
"x": [-100, 100],
"y": [-100, 100],
"vx": [-20, 20],
"vy": [-20, 20]
},
"absolute": False,
"order": "sorted"
},
"simulation_frequency": 8,# [Hz]
"policy_frequency": 2,# [Hz]
}
env = gym.make("highway-v0")
env.configure(config)
Trainingsmodell:
dqn=DQN()
count=0
reward=[]
avg_reward=0
all_reward=[]
time_=[]
all_time=[]
collision_his=[]
all_collision=[]
while True:
done = False
start_time=time.time()
s = env.reset()
while not done:
e = np.exp(-count/300)#随机选择action的概率,随着训练次数增多逐渐降低
a = dqn.choose_action(s,e)
s_, r, done, info = env.step(a)
env.render()
dqn.push_memory(s, a, r, s_)
if ((dqn.position !=0)&(dqn.position % 99==0)):
loss_=dqn.learn()
count+=1
print('trained times:',count)
if (count%40==0):
avg_reward=np.mean(reward)
avg_time=np.mean(time_)
collision_rate=np.mean(collision_his)
all_reward.append(avg_reward)
all_time.append(avg_time)
all_collision.append(collision_rate)
plt.plot(all_reward)
plt.show()
plt.plot(all_time)
plt.show()
plt.plot(all_collision)
plt.show()
reward=[]
time_=[]
collision_his=[]
s = s_
reward.append(r)
end_time=time.time()
episode_time=end_time-start_time
time_.append(episode_time)
is_collision=1 if info['crashed']==True else 0
collision_his.append(is_collision)
Ich habe dem Code einige Zeichenfunktionen hinzugefügt, und ich kann einige Schlüsselindikatoren während des laufenden Prozesses erfassen und jedes Mal 40 Mal trainieren. Berechnen Sie den Durchschnitt Wert.
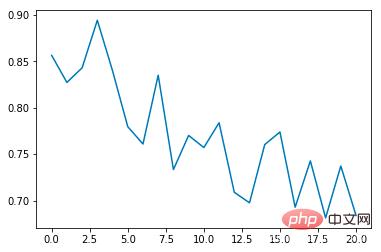
Durchschnittliche Kollisionsinzidenzrate:
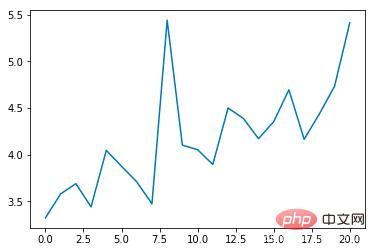
Durchschnittliche Epochendauer (n):
Durchschnittliche Belohnung:
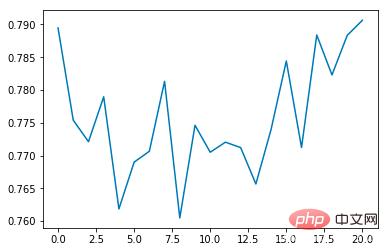
Es ist ersichtlich, dass die durchschnittliche Kollisionsinzidenzrate mit der Anzahl der Schulungen allmählich abnimmt erhöht sich mit jeder Epoche. Die Dauer verlängert sich schrittweise (wenn eine Kollision auftritt, endet die Epoche sofort) Damit der Algorithmus ideal umgesetzt werden kann, kann er in einer virtuellen Umgebung trainiert werden, ohne reale Probleme wie Datenerfassungsmethoden, Sensorgenauigkeit und Berechnungszeit zu berücksichtigen. Es ist sehr benutzerfreundlich für das Design und Testen von End-to-End-Algorithmen, aber aus Sicht der automatischen Steuerung gibt es zunächst weniger Aspekte und ist nicht sehr flexibel in der Forschung.
Das obige ist der detaillierte Inhalt vonLernen Sie Python, um ein autonomes Fahrsystem zu implementieren. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!