
Heim >Backend-Entwicklung >Python-Tutorial >Was sind die gängigen Normalisierungsmethoden in Python?
Was sind die gängigen Normalisierungsmethoden in Python?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-20 08:58:142876Durchsuche
Die Datennormalisierung ist ein sehr wichtiger Schritt bei der Vorverarbeitung von Deep-Learning-Daten, der Dimensionen vereinheitlichen und verhindern kann, dass kleine Daten verschluckt werden.
1: Das Konzept der Normalisierung
Normalisierung besteht darin, alle Daten in Zahlen zwischen [0,1] oder [-1,1] umzuwandeln. Ihr Zweck besteht darin, die Unterschiede zwischen den Daten in jeder Dimension aufzuheben Die Differenz verhindert, dass der Netzwerkvorhersagefehler aufgrund des großen Größenordnungsunterschieds zwischen Eingabe- und Ausgabedaten zu groß wird.
2: Die Rolle der Normalisierung
Um die spätere Datenverarbeitung zu erleichtern, kann die Normalisierung einige unnötige numerische Probleme vermeiden.
Um bei laufendem Programm schneller zu konvergieren
Vereinheitlichen Sie die Dimensionen. Die Bewertungskriterien für Beispieldaten sind unterschiedlich, daher müssen sie dimensioniert und die Bewertungskriterien vereinheitlicht werden. Dies wird als Anforderung auf Anwendungsebene angesehen.
Vermeiden Sie eine neuronale Sättigung. Das heißt, wenn die Aktivierung von Neuronen nahe bei 0 oder 1 liegt, ist der Gradient in diesen Bereichen nahezu 0, sodass während des Rückausbreitungsprozesses der lokale Gradient nahe bei 0 liegt, was für das Netzwerk sehr ungünstig ist Ausbildung.
Stellen Sie sicher, dass kleine Werte in den Ausgabedaten nicht verschluckt werden.
Drei: Arten der Normalisierung
1: Lineare Normalisierung
Die lineare Normalisierung wird auch Min-Max-Normalisierung genannt; ist eine lineare Transformation der Originaldaten, bei der die Datenwerte in einen Wert zwischen [0 ,1]. Es wird ausgedrückt als:
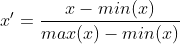
Die Differenzstandardisierung behält die in den Originaldaten bestehende Beziehung bei und ist die einfachste Methode, um den Einfluss von Dimensionen und Datenwertbereichen zu eliminieren. Der Code wird wie folgt implementiert:
def MaxMinNormalization(x,Max,Min):
x = (x - Min) / (Max - Min);
return xAnwendungsbereich: Eher geeignet für Situationen, in denen numerische Werte relativ konzentriert sind
Nachteile:
Wenn Max und Min instabil sind, kann das normalisierte Ergebnis leicht instabil werden , was die spätere Verwendung weniger effektiv macht. Wenn der Wertebereich das aktuelle Attribut [min, max] überschreitet, führt dies dazu, dass das System einen Fehler meldet. Min und Max müssen neu bestimmt werden.
Wenn ein bestimmter Wert im Wertesatz sehr groß ist, liegen die Werte nach der Normalisierung nahe bei 0 und unterscheiden sich nicht wesentlich. (z. B. 1,1.2,1.3,1.4,1.5,1.6,10) dieser Datensatz.
2: Null-Mittelwert-Normalisierung (Z-Score-Normalisierung)
Z-Score-Normalisierung wird auch Standardabweichungsnormalisierung genannt. Der Mittelwert der verarbeiteten Daten beträgt 0 und die Standardabweichung beträgt 1. Die Umrechnungsformel lautet:
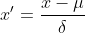
wobei 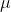 der Mittelwert der Originaldaten ist,
der Mittelwert der Originaldaten ist, 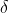 die Standardabweichung der Originaldaten, die am häufigsten verwendete Standardisierungsformel
die Standardabweichung der Originaldaten, die am häufigsten verwendete Standardisierungsformel
Diese Methode gibt den Mittelwert und die Standardabweichung der an Originaldaten (Standardabweichung) standardisieren die Daten. Die verarbeiteten Daten entsprechen der Standardnormalverteilung, das heißt, der Mittelwert ist 0 und die Standardabweichung ist 1. Der Schlüssel hier ist die zusammengesetzte Standardnormalverteilung
Der Code ist wie folgt implementiert:
def Z_ScoreNormalization(x,mu,sigma):
x = (x - mu) / sigma;
return x3: Dezimalskalierungsnormalisierung
Diese Methode wird übergeben. Verschieben Sie die Dezimalstellen des Attributwerts und ordnen Sie den Attributwert einem Wert zwischen [-1,1] zu. Die Anzahl der verschobenen Dezimalstellen hängt vom maximalen Absolutwert des Attributwerts ab. Die Umrechnungsformel lautet:
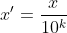
4: Nichtlineare Normalisierung
Diese Methode umfasst logarithmische, exponentielle und tangentiale
Anwendungsbereich: Wird häufig in relativ großen Datenanalyseszenarien verwendet. Einige Werte sind sehr groß, andere sehr klein, Ordnen Sie den ursprünglichen Wert zu.
4: Batch-Normalisierung
1: Einführung
Im vergangenen neuronalen Netzwerktraining wurden nur die Daten der Eingabeschicht normalisiert, in der mittleren Schicht gab es jedoch keine Normalisierung. Obwohl wir die Eingabedaten normalisiert haben, wird sich ihre Datenverteilung wahrscheinlich stark ändern, nachdem die Eingabedaten einer solchen Matrixmultiplikation unterzogen wurden, und da die Anzahl der Schichten des Netzwerks weiter zunimmt. Die Datenverteilung wird sich immer mehr verändern. Daher wird dieser Normalisierungsprozess in der mittleren Schicht des neuronalen Netzwerks, der den Trainingseffekt verbessert, als Batch-Normalisierung (BN) bezeichnet
- Ersetzt die ursprüngliche Datenverteilung, wodurch die Überanpassung bis zu einem gewissen Grad gemildert wird (wodurch verhindert wird, dass eine bestimmte Stichprobe in jedem Trainingsstapel häufig ausgewählt wird).
- Reduziert das Verschwinden des Gradienten, beschleunigt die Konvergenz und verbessert die Trainingsgenauigkeit.
- 3: Prozess des Batch-Normalisierungsalgorithmus (BN) Eingabe: Ausgabeergebnis der vorherigen Ebene 1) Berechnen Sie den Mittelwert der Ausgabedaten der vorherigen Ebene:
-
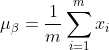
Dabei ist m die Größe dieser Trainingsbeispielcharge.
2) Berechnen Sie die Standardabweichung der Ausgabedaten der vorherigen Ebene:
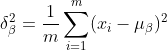
3) Normalisierungsprozess, um
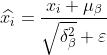
zu erhalten. Das
 in der Formel dient dazu, zu vermeiden, dass der Nenner 0 ist und ein kleiner Wert hinzugefügt wird nahe am 0-Wert.
in der Formel dient dazu, zu vermeiden, dass der Nenner 0 ist und ein kleiner Wert hinzugefügt wird nahe am 0-Wert. 4) Rekonstruktion: Rekonstruieren Sie die nach dem obigen Normalisierungsprozess erhaltenen Daten und erhalten Sie:
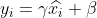
wobei
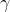 ,
, 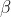 lernbare Parameter sind.
lernbare Parameter sind.
Das obige ist der detaillierte Inhalt vonWas sind die gängigen Normalisierungsmethoden in Python?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!