
Heim >Java >javaLernprogramm >Was ist das Prinzip und der Prozess des Java Synchronized Lock-Upgrades?
Was ist das Prinzip und der Prozess des Java Synchronized Lock-Upgrades?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-19 22:22:121753Durchsuche
Werkzeugvorbereitung
Bevor wir offiziell über das Prinzip der Synchronisierung sprechen, sprechen wir über Spin-Lock, denn bei der Optimierung der Synchronisierung, Spin Lock spielte eine große Rolle. Um Spin Lock zu verstehen, müssen wir zunächst verstehen, was Atomizität ist.
Die sogenannte Atomizität bedeutet einfach, dass jeder Vorgang entweder nicht erledigt ist oder alles erledigt ist, was bedeutet, dass er beispielsweise während des Vorgangs nicht unterbrochen werden kann Drei Schritte, um eins zur Variablen data hinzuzufügen: data进行加一操作,有以下三个步骤:
将
data从内存加载到寄存器。将
data这个值加一。将得到的结果写回内存。
原子性就表示一个线程在进行加一操作的时候,不能够被其他线程中断,只有这个线程执行完这三个过程的时候其他线程才能够操作数据data。
我们现在用代码体验一下,在Java当中我们可以使用AtomicInteger进行对整型数据的原子操作:
import java.util.concurrent.atomic.AtomicInteger;
public class AtomicDemo {
public static void main(String[] args) throws InterruptedException {
AtomicInteger data = new AtomicInteger();
data.set(0); // 将数据初始化位0
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
data.addAndGet(1); // 对数据 data 进行原子加1操作
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 100000; i++) {
data.addAndGet(1);// 对数据 data 进行原子加1操作
}
});
// 启动两个线程
t1.start();
t2.start();
// 等待两个线程执行完成
t1.join();
t2.join();
// 打印最终的结果
System.out.println(data); // 200000
}
}从上面的代码分析可以知道,如果是一般的整型变量如果两个线程同时进行操作的时候,最终的结果是会小于200000。
我们现在来模拟一下一般的整型变量出现问题的过程:
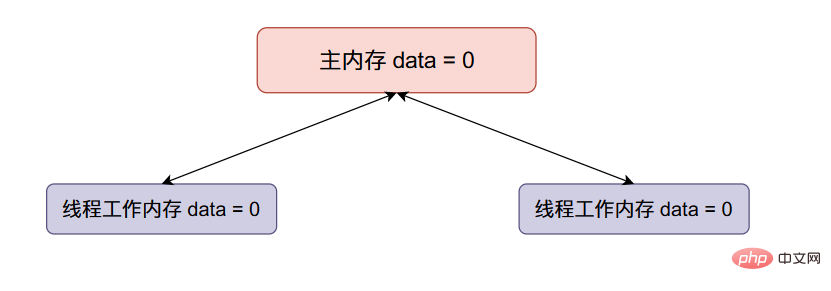
主内存data的初始值等于0,两个线程得到的data初始值都等于0。
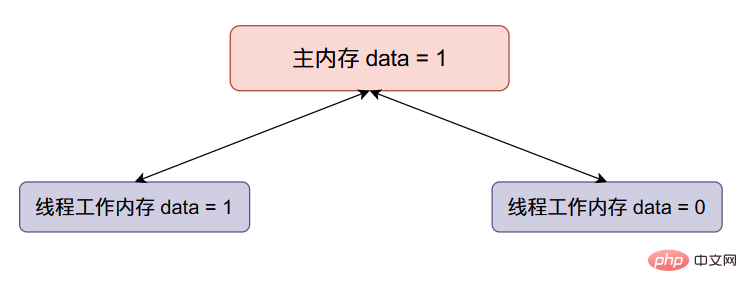
现在线程一将data加一,然后线程一将data的值同步回主内存,整个内存的数据变化如下:
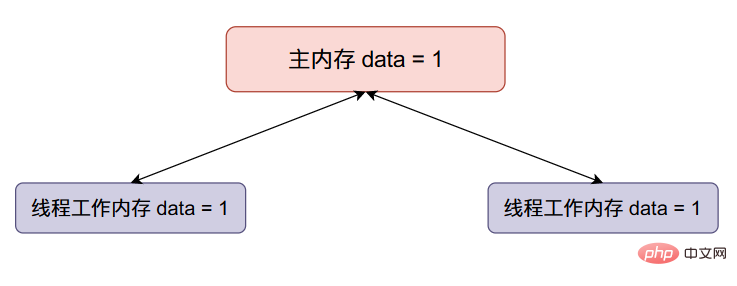
现在线程二data加一,然后将data的值同步回主内存(将原来主内存的值覆盖掉了):
我们本来希望data的值在经过上面的变化之后变成2,但是线程二覆盖了我们的值,因此在多线程情况下,会使得我们最终的结果变小。
但是在上面的程序当中我们最终的输出结果是等于20000的,这是因为给data进行+1的操作是原子的不可分的,在操作的过程当中其他线程是不能对data进行操作的。这就是原子性带来的优势。
事实上上面的+1原子操作就是通过自旋锁实现的,我们可以看一下AtomicInteger的源代码:
public final int addAndGet(int delta) {
// 在 AtomicInteger 内部有一个整型数据 value 用于存储具体的数值的
// 这个 valueOffset 表示这个数据 value 在对象 this (也就是 AtomicInteger一个具体的对象)
// 当中的内存偏移地址
// delta 就是我们需要往 value 上加的值 在这里我们加上的是 1
return unsafe.getAndAddInt(this, valueOffset, delta) + delta;
}上面的代码最终是调用UnSafe类的方法进行实现的,我们再看一下他的源代码:
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset); // 从对象 o 偏移地址为 offset 的位置取出数据 value ,也就是前面提到的存储整型数据的变量
} while (!compareAndSwapInt(o, offset, v, v + delta));
return v;
}上面的代码主要流程是不断的从内存当中取对象内偏移地址为offset的数据,然后执行语句!compareAndSwapInt(o, offset, v, v + delta)
这条语句的主要作用是:比较对象o内存偏移地址为offset的数据是否等于v,如果等于v则将偏移地址为offset的数据设置为v + delta,如果这条语句执行成功返回 true否则返回false
data aus dem Speicher in das Register laden. Füge eins zum Wert von data hinzu.
data manipuliert werden. - Lassen Sie es uns jetzt mit Code erleben. In Java können wir
AtomicIntegerverwenden, um atomare Operationen an ganzzahligen Daten auszuführen://设置偏向延迟时间 只有经过这个时间只有对象锁才会有偏向锁这个状态 -XX:BiasedLockingStartupDelay=4 //禁止偏向锁 -XX:-UseBiasedLocking //开启偏向锁 -XX:+UseBiasedLocking
Aus dem obigen Code Die Analyse kann zeigen, dass das Endergebnis weniger als 200.000 beträgt, wenn es sich um eine allgemeine Ganzzahlvariable handelt und zwei Threads gleichzeitig ausgeführt werden. Lassen Sie uns nun den Prozess von Problemen mit allgemeinen Ganzzahlvariablen simulieren: Der Anfangswert des Hauptspeichersdataist gleich 0 und zwei Threads Die Anfangswerte der erhaltenenDatensind alle gleich 0. -
 Jetzt Thread eins Fügen Sie einen zu
Jetzt Thread eins Fügen Sie einen zu datahinzu, und dann synchronisiert Thread 1 den Wert vondatazurück in den Hauptspeicher. Die Daten im gesamten Speicher ändern sich wie folgt: #🎜 🎜# Jetzt zwei
Daten einfädeln code> fügt einen hinzu und synchronisiert dann den Wert von <code>datazurück mit dem Hauptspeicher (überschreibt den ursprünglichen Wert des Hauptspeichers):
Wir hatten ursprünglich gehofft, dass der Wert von data 2Aber im obigen Programm ist unser endgültiges Ausgabeergebnis gleich 20000. Dies liegt daran, dass die Operation von +1 für data atomar ist. Untrennbar ist, dass andere Threads während des Vorgangs nicht mit Daten arbeiten können. Dies ist der Vorteil, den
mit sich bringt.
#🎜🎜#Tatsächlich wird die obige atomare Operation+1 durch #🎜🎜#Spin lock#🎜🎜# implementiert. Wir können einen Blick auf AtomicInteger werfen. Code >s Quellcode: #🎜🎜#<pre class="brush:java;">import org.openjdk.jol.info.ClassLayout;
import java.util.concurrent.TimeUnit;
public class MarkWord {
public Object o = new Object();
public synchronized void demo() {
synchronized (o) {
System.out.println("synchronized代码块内");
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
public static void main(String[] args) throws InterruptedException {
System.out.println("等待4s前");
System.out.println(ClassLayout.parseInstance(new Object()).toPrintable());
TimeUnit.SECONDS.sleep(4);
MarkWord markWord = new MarkWord();
System.out.println("等待4s后");
System.out.println(ClassLayout.parseInstance(new Object()).toPrintable());
Thread thread = new Thread(markWord::demo);
thread.start();
thread.join();
System.out.println(ClassLayout.parseInstance(markWord.o).toPrintable());
}
}</pre>#🎜🎜#Der obige Code wird letztendlich durch den Aufruf der Methode der Klasse <code>UnSafe implementiert. Schauen wir uns noch einmal den Quellcode an: #🎜 🎜#<dependency> <groupId>org.openjdk.jol</groupId> <artifactId>jol-core</artifactId> <version>0.10</version> </dependency># 🎜🎜#Der Hauptprozess des obigen Codes besteht darin, die Daten mit der Offset-Adresse
offset im Objekt kontinuierlich aus dem Speicher abzurufen und dann die Anweisung !compareAndSwapInt(o) auszuführen , offset, v, v + delta )#🎜🎜##🎜🎜#Die Hauptfunktion dieser Anweisung besteht darin, zu vergleichen, ob die Daten des Objekts o, dessen Speicheroffsetadresse offset ist gleich v, wenn gleich v, setzen Sie die Daten mit der Offset-Adresse offset auf v + delta, wenn diese Anweisung erfolgreich ausgeführt wird, gibt sie true zurück, andernfalls gibt sie false zurück. Das nennen wir oft #🎜🎜#CAS#. 🎜🎜# in Java. #🎜🎜##🎜🎜#Wenn Sie dies sehen, sollten Sie festgestellt haben, dass die While-Schleife fortgesetzt wird, bis die Operation erfolgreich ist, und wenn die Ausführung der obigen Anweisung fehlschlägt Ist dies nicht erfolgreich, wird es hier fortgesetzt. Operationen wie diese sind #🎜🎜#spin#🎜🎜#, und die durch diese #🎜🎜#spin#🎜🎜#-Methode gebildete Sperre heißt #🎜🎜#spinlock # 🎜🎜#. #🎜🎜##🎜🎜#Objektspeicherlayout#🎜🎜##🎜🎜#In der JVM gibt es drei Hauptspeicherteile für ein Java-Objekt: #🎜🎜##🎜🎜##🎜🎜##🎜🎜 #Object Header, der Objektheader enthält zwei Datenteile, nämlich #🎜🎜#Mark Word#🎜🎜# und Typzeiger (#🎜🎜#Kclass-Zeiger#🎜🎜#). #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Instanzdaten sind die verschiedenen Daten, die wir in der Klasse definieren. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#Ausrichtungsauffüllung: Wenn die JVM implementiert ist, muss die von jedem Objekt belegte Speichergröße ein ganzzahliges Vielfaches von 8 Bytes sein Wenn die Speichergröße kein ganzzahliges Vielfaches von 8 Byte ist, muss sie auf 8 Byte aufgefüllt werden. Wenn beispielsweise eine Objektstation 60 Byte groß ist, wird sie schließlich auf 64 Byte aufgefüllt. #🎜🎜##🎜🎜##🎜🎜##🎜🎜#In engem Zusammenhang mit dem Prinzip der synchronisierten Sperraktualisierung, über das wir sprechen werden, steht #🎜🎜#Wort markieren#🎜🎜#. Dieses Feld wird hauptsächlich zum Speichern von Objekten verwendet Laufzeitdaten, wie der Hashcode des Objekts, das Generationsalter des GC, der Thread, der die Sperre hält usw. Der Kclass-Zeiger wird hauptsächlich verwendet, um auf die Klasse des Objekts zu verweisen, hauptsächlich um anzugeben, zu welcher Klasse das Objekt gehört, und um die Metadaten der Klasse zu finden. #🎜🎜##🎜🎜#In der 32-Bit-Java-Virtual-Machine hat das Mark-Wort 4 Bytes und insgesamt 32 Bits. Sein Inhalt ist wie folgt: #🎜🎜#
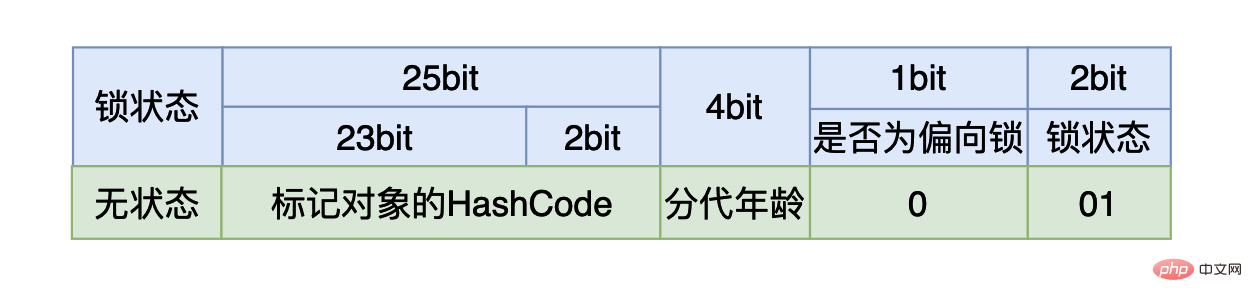
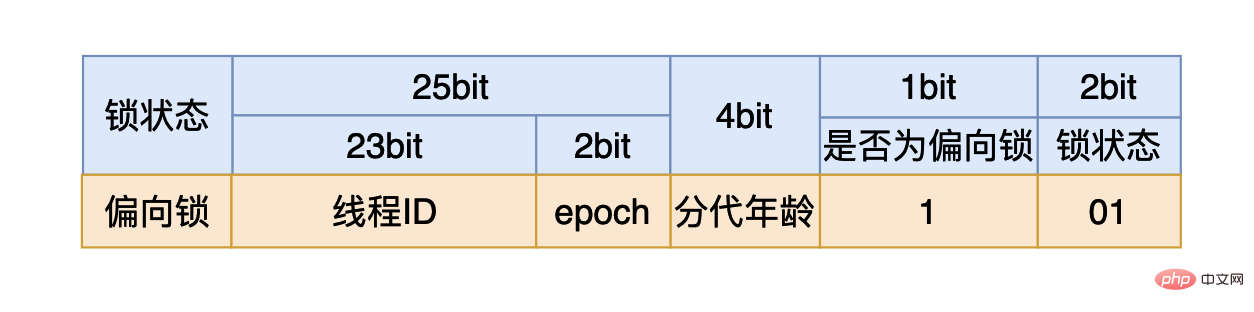
我们在使用synchronized时,如果我们是将synchronized用在同步代码块,我们需要一个锁对象。对于这个锁对象来说一开始还没有线程执行到同步代码块时,这个4个字节的内容如上图所示,其中有25个比特用来存储哈希值,4个比特用来存储垃圾回收的分代年龄(如果不了解可以跳过),剩下三个比特其中第一个用来表示当前的锁状态是否为偏向锁,最后的两个比特表示当前的锁是哪一种状态:
如果最后三个比特是:001,则说明锁状态是没有锁。
如果最后三个比特是:101,则说明锁状态是偏向锁。
如果最后两个比特是:00, 则说明锁状态是轻量级锁。
如果最后两个比特是:10, 则说明锁状态是重量级锁。
而synchronized锁升级的顺序是:无????->偏向????->轻量级????->重量级????。
在Java当中有一个JVM参数用于设置在JVM启动多少秒之后开启偏向锁(JDK6之后默认开启偏向锁,JVM默认启动4秒之后开启对象偏向锁,这个延迟时间叫做偏向延迟,你可以通过下面的参数进行控制):
//设置偏向延迟时间 只有经过这个时间只有对象锁才会有偏向锁这个状态 -XX:BiasedLockingStartupDelay=4 //禁止偏向锁 -XX:-UseBiasedLocking //开启偏向锁 -XX:+UseBiasedLocking
我们可以用代码验证一下在无锁状态下,MarkWord的内容是什么:
import org.openjdk.jol.info.ClassLayout;
import java.util.concurrent.TimeUnit;
public class MarkWord {
public Object o = new Object();
public synchronized void demo() {
synchronized (o) {
System.out.println("synchronized代码块内");
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
public static void main(String[] args) throws InterruptedException {
System.out.println("等待4s前");
System.out.println(ClassLayout.parseInstance(new Object()).toPrintable());
TimeUnit.SECONDS.sleep(4);
MarkWord markWord = new MarkWord();
System.out.println("等待4s后");
System.out.println(ClassLayout.parseInstance(new Object()).toPrintable());
Thread thread = new Thread(markWord::demo);
thread.start();
thread.join();
System.out.println(ClassLayout.parseInstance(markWord.o).toPrintable());
}
}上面代码输出结果,下面的红框框住的表示是否是偏向锁和锁标志位(可能你会有疑问为什么是这个位置,不应该是最后3个比特位表示锁相关的状态吗,这个其实是数据表示的大小端问题,大家感兴趣可以去查一下,在这你只需知道红框三个比特就是用于表示是否为偏向锁和锁的标志位):
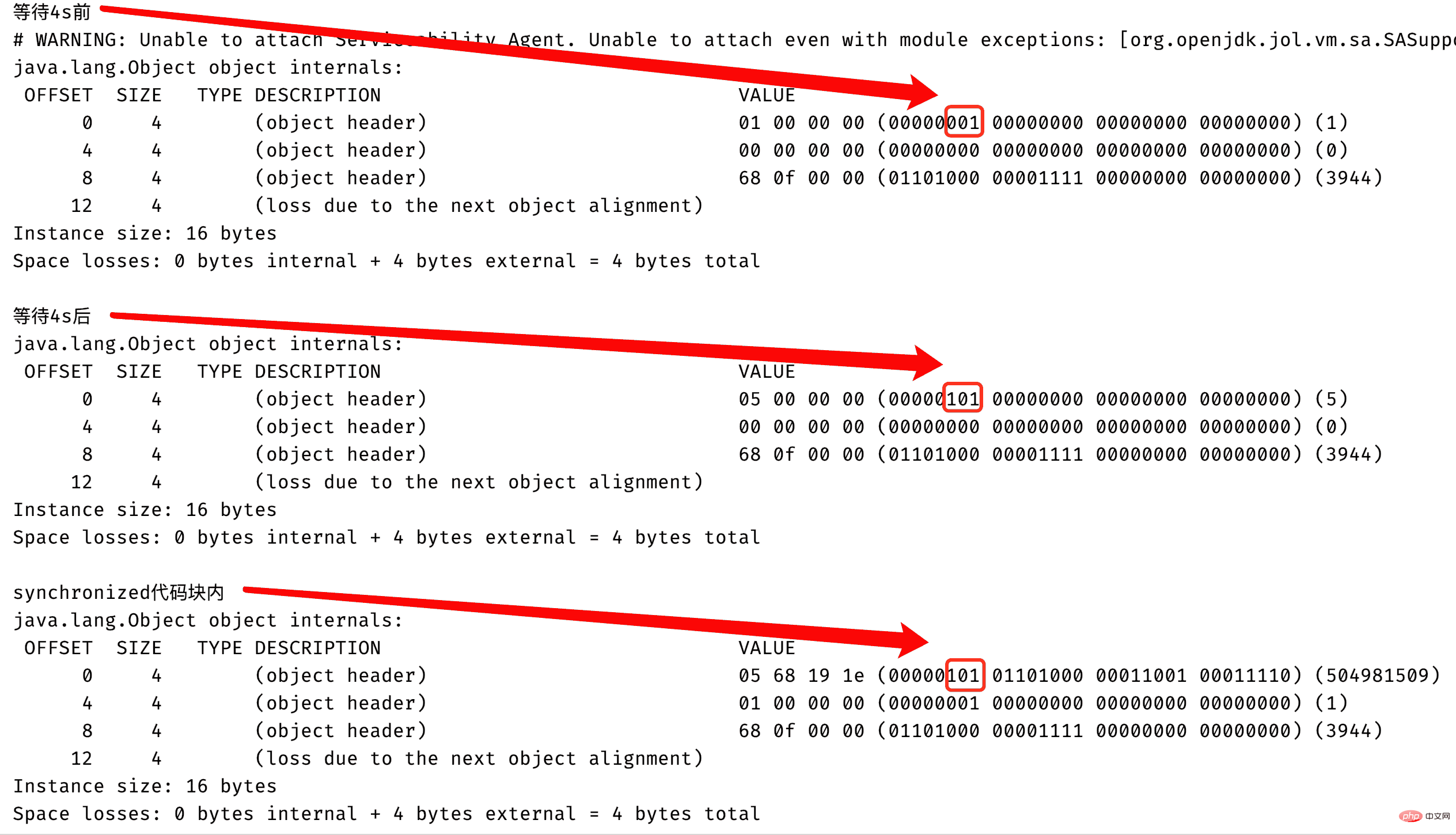
从上面的图当中我们可以分析得知在偏向延迟的时间之前,对象锁的状态还不会有偏向锁,因此对象头中的Markword当中锁状态是01,同时偏向锁状态是0,表示这个时候是无锁状态,但是在4秒之后偏向锁的状态已经变成1了,因此当前的锁状态是偏向锁,但是还没有线程占有他,这种状态也被称作匿名偏向,因为在上面的代码当中只有一个线程进入了synchronized同步代码块,因此可以使用偏向锁,因此在synchronized代码块当中打印的对象的锁状态也是偏向锁。
上面的代码当中使用到了jol包,你需要在你的pom文件当中引入对应的包:
<dependency> <groupId>org.openjdk.jol</groupId> <artifactId>jol-core</artifactId> <version>0.10</version> </dependency>
上图当中我们显示的结果是在64位机器下面显示的结果,在64位机器当中在Java对象头当中的MarkWord和Klcass Pointer内存布局如下:

其中MarkWord占8个字节,Kclass Pointer占4个字节。JVM在64位和32位机器上的MarkWord内容基本一致,64位机器上和32位机器上的MarkWord内容和表示意义是一样的,因此最后三位的意义你可以参考32位JVM的MarkWord。
锁升级过程
偏向锁
假如你写的synchronized代码块没有多个线程执行,而只有一个线程执行的时候这种锁对程序性能的提高还是非常大的。他的具体做法是JVM会将对象头当中的第三个用于表示是否为偏向锁的比特位设置为1,同时会使用CAS操作将线程的ID记录到Mark Word当中,如果操作成功就相当于获得????了,那么下次这个线程想进入临界区就只需要比较一下线程ID是否相同了,而不需要进行CAS或者加锁这样花费比较大的操作了,只需要进行一个简单的比较即可,这种情况下加锁的开销非常小。
可能你会有一个疑问在无锁的状态下Mark Word存储的是哈希值,而在偏向锁的状态下存储的是线程的ID,那么之前存储的Hash Code不就没有了嘛!你可能会想没有就没有吧,再算一遍不就行了!事实上不是这样,如果我们计算过哈希值之后我们需要尽量保持哈希值不变(但是这个在Java当中并没有强制,因为在Java当中可以重写hashCode方法),因此在Java当中为了能够保持哈希值的不变性就会在第一次计算一致性哈希值(Mark Word里面存储的是一致性哈希值,并不是指重写的hashCode返回值,在Java当中可以通过 Object.hashCode()或者System.identityHashCode(Object)方法计算一致性哈希值)的时候就将计算出来的一致性哈希值存储到Mark Word当中,下一次再有一致性哈希值的请求的时候就将存储下来的一致性哈希值返回,这样就可以保证每次计算的一致性哈希值相同。但是在变成偏向锁的时候会使用线程ID覆盖哈希值,因此当一个对象计算过一致性哈希值之后,他就再也不能进行偏向锁状态,而且当一个对象正处于偏向锁状态的时候,收到了一致性哈希值的请求的时候,也就是调用上面提到的两个方法,偏向锁就会立马膨胀为重量级锁,然后将Mark Word 储在重量级锁里。
下面的代码就是验证当在偏向锁的状态调用System.identityHashCode函数锁的状态就会升级为重量级锁:
import org.openjdk.jol.info.ClassLayout;
import java.util.concurrent.TimeUnit;
public class MarkWord {
public Object o = new Object();
public synchronized void demo() {
System.out.println("System.identityHashCode(o) 函数之前");
System.out.println(ClassLayout.parseInstance(o).toPrintable());
synchronized (o) {
System.identityHashCode(o);
System.out.println("System.identityHashCode(o) 函数之后");
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
public static void main(String[] args) throws InterruptedException {
TimeUnit.SECONDS.sleep(5);
MarkWord markWord = new MarkWord();
Thread thread = new Thread(markWord::demo);
thread.start();
thread.join();
TimeUnit.SECONDS.sleep(2);
System.out.println(ClassLayout.parseInstance(markWord.o).toPrintable());
}
}
轻量级锁
轻量级锁也是在JDK1.6加入的,当一个线程获取偏向锁的时候,有另外的线程加入锁的竞争时,这个时候就会从偏向锁升级为轻量级锁。
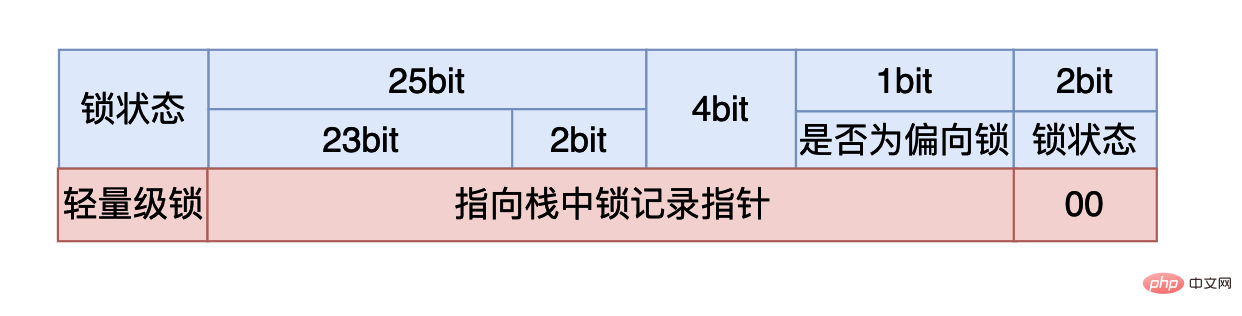
在轻量级锁的状态时,虚拟机首先会在当前线程的栈帧当中建立一个锁记录(Lock Record),用于存储对象MarkWord的拷贝,官方称这个为Displaced Mark Word。然后虚拟机会使用CAS操作尝试将对象的MarkWord指向栈中的Lock Record,如果操作成功说明这个线程获取到了锁,能够进入同步代码块执行,否则说明这个锁对象已经被其他线程占用了,线程就需要使用CAS不断的进行获取锁的操作,当然你可能会有疑问,难道就让线程一直死循环了吗?这对CPU的花费那不是太大了吗,确实是这样的因此在CAS满足一定条件的时候轻量级锁就会升级为重量级锁,具体过程在重量级锁章节中分析。
当线程需要从同步代码块出来的时候,线程同样的需要使用CAS将Displaced Mark Word替换回对象的MarkWord,如果替换成功,那么同步过程就完成了,如果替换失败就说明有其他线程尝试获取该锁,而且锁已经升级为重量级锁,此前竞争锁的线程已经被挂起,因此线程在释放锁的同时还需要将挂起的线程唤醒。
重量级锁
所谓重量级锁就是一种开销最大的锁机制,在这种情况下需要操作系统将没有进入同步代码块的线程挂起,JVM(Linux操作系统下)底层是使用pthread_mutex_lock、pthread_mutex_unlock、pthread_cond_wait、pthread_cond_signal和pthread_cond_broadcast这几个库函数实现的,而这些函数依赖于futex系统调用,因此在使用重量级锁的时候因为进行了系统调用,进程需要从用户态转为内核态将线程挂起,然后从内核态转为用户态,当解锁的时候又需要从用户态转为内核态将线程唤醒,这一来二去的花费就比较大了(和CAS自旋锁相比)。
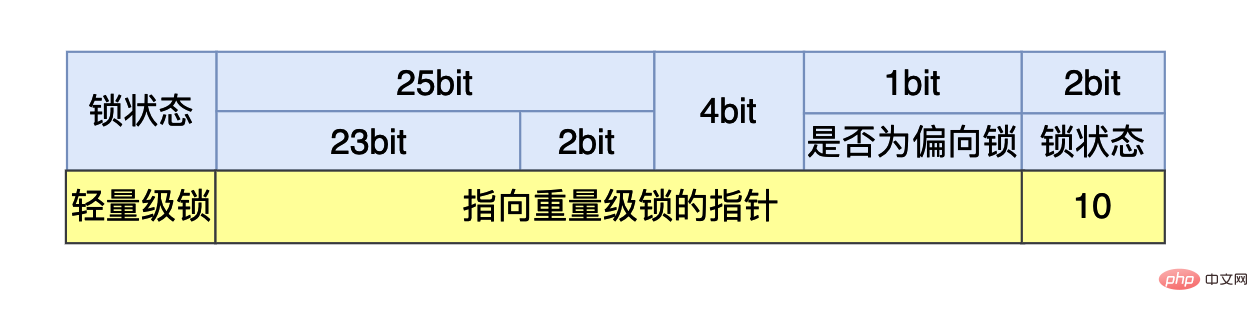
在有两个以上的线程竞争同一个轻量级锁的情况下,轻量级锁不再有效(轻量级锁升级的一个条件),这个时候锁为膨胀成重量级锁,锁的标志状态变成10,MarkWord当中存储的就是指向重量级锁的指针,后面等待锁的线程就会被挂起。
因为这个时候MarkWord当中存储的已经是指向重量级锁的指针,因此在轻量级锁的情况下进入到同步代码块在出同步代码块的时候使用CAS将Displaced Mark Word替换回对象的MarkWord的时候就会替换失败,在前文已经提到,在失败的情况下,线程在释放锁的同时还需要将被挂起的线程唤醒。
Das obige ist der detaillierte Inhalt vonWas ist das Prinzip und der Prozess des Java Synchronized Lock-Upgrades?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!