
Heim >Java >javaLernprogramm >Umgang mit großen Objekten in Java
Umgang mit großen Objekten in Java

- PHPznach vorne
- 2023-04-19 08:07:041031Durchsuche
Substring in String
Wir alle wissen, dass String in Java unveränderlich ist. Wenn Sie seinen Inhalt ändern, wird ein neuer String generiert. Wenn wir einen Teil der Daten im String verwenden möchten, können wir die Teilstring-Methode verwenden.
Das Folgende ist der Quellcode von String in Java11.
public String substring(int beginIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = length() - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
if (beginIndex == 0) {
return this;
}
return isLatin1() ? StringLatin1.newString(value, beginIndex, subLen)
: StringUTF16.newString(value, beginIndex, subLen);
}
public static String newString(byte[] val, int index, int len) {
if (String.COMPACT_STRINGS) {
byte[] buf = compress(val, index, len);
if (buf != null) {
return new String(buf, LATIN1);
}
}
int last = index + len;
return new String(Arrays.copyOfRange(val, index << 1, last << 1), UTF16);
}Wie im obigen Code gezeigt, generiert substring, wenn wir einen Teilstring benötigen, einen neuen String, der über die Funktion Arrays.copyOfRange des Konstruktors erstellt wird.
Diese Funktion hat nach Java7 kein Problem, aber in Java6 besteht das Risiko eines Speicherverlusts. Wir können diesen Fall untersuchen, um die Probleme zu erkennen, die durch die Wiederverwendung großer Objekte entstehen können. Das Folgende ist der Code in Java6:
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > count) {
throw new StringIndexOutOfBoundsException(endIndex);
}
if (beginIndex > endIndex) {
throw new StringIndexOutOfBoundsException(endIndex - beginIndex);
}
return ((beginIndex == 0) && (endIndex == count)) ?
this :
new String(offset + beginIndex, endIndex - beginIndex, value);
}
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}Sie können sehen, dass beim Erstellen eines Teilstrings nicht nur das erforderliche Objekt kopiert wird, sondern auf den gesamten Wert verwiesen wird. Wenn die ursprüngliche Zeichenfolge relativ groß ist, wird der Speicher nicht freigegeben, auch wenn er nicht mehr verwendet wird.
Zum Beispiel kann der Inhalt eines Artikels mehrere Megabyte groß sein. Wir benötigen nur die zusammenfassenden Informationen und müssen das gesamte große Objekt pflegen.
Einige Interviewer, die schon lange arbeiten, haben den Eindruck, dass sich der Teilstring noch in JDK6 befindet, aber tatsächlich hat Java diesen Fehler bereits geändert. Wenn Sie im Vorstellungsgespräch auf diese Frage stoßen, können Sie sicherheitshalber die Frage nach dem Verbesserungsprozess beantworten.
Für uns bedeutet dies: Wenn Sie ein relativ großes Objekt erstellen und andere Informationen basierend auf diesem Objekt generieren, müssen Sie zu diesem Zeitpunkt daran denken, die Referenzbeziehung zu diesem großen Objekt zu entfernen.
Erweiterung großer Sammlungsobjekte
Objekterweiterung ist ein häufiges Phänomen in Java, wie z. B. StringBuilder, StringBuffer, HashMap, ArrayList usw. Zusammenfassend lässt sich sagen, dass die Daten in Java-Sammlungen, einschließlich List, Set, Queue, Map usw., nicht kontrollierbar sind. Wenn die Kapazität nicht ausreicht, kommt es zu Erweiterungsvorgängen, bei denen die Daten neu organisiert werden müssen, sodass sie nicht threadsicher sind.
Schauen wir uns zunächst den Erweiterungscode von StringBuilder an:
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}Wenn die Kapazität nicht ausreicht, wird der Speicher verdoppelt und die Quelldaten werden mit Arrays.copyOf kopiert.
Das Folgende ist der Erweiterungscode von HashMap. Nach der Erweiterung wird auch die Größe verdoppelt. Seine Erweiterungsaktion ist viel komplizierter. Zusätzlich zu den Auswirkungen des Lastfaktors ist auch ein erneutes Hashen der Originaldaten erforderlich. Da die native Arrays.copy-Methode nicht verwendet werden kann, ist die Geschwindigkeit sehr langsam.
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}Sie können den Code der Liste selbst anzeigen. Er blockiert auch das 1,5-fache der ursprünglichen Länge.
Da Sammlungen im Code sehr häufig verwendet werden, möchten Sie möglicherweise eine angemessene Initialisierungsgröße festlegen, wenn Sie die spezifische Obergrenze der Datenelemente kennen. Beispielsweise erfordert HashMap 1024 Elemente und 7 Erweiterungen, was sich auf die Leistung der Anwendung auswirkt. Diese Frage wird in Vorstellungsgesprächen häufig gestellt, und Sie müssen die Auswirkungen dieser Erweiterungsvorgänge auf die Leistung verstehen.
Aber bitte beachten Sie, dass für eine Sammlung wie HashMap mit einem Ladefaktor (0,75) die Anfangsgröße = die erforderliche Anzahl/der Ladefaktor + 1 ist. Wenn Sie sich über die zugrunde liegende Struktur nicht ganz im Klaren sind, können Sie diese genauso gut beibehalten Standard.
Als nächstes erläutere ich die Optimierung auf Anwendungsebene ausgehend von der Strukturdimension und der Zeitdimension der Daten.
Behalten Sie eine angemessene Objektgranularität bei
Lassen Sie mich einen praktischen Fall mit Ihnen teilen: Wir haben ein Geschäftssystem mit sehr hoher Parallelität, das eine häufige Nutzung der Basisdaten der Benutzer erfordert.
Da die Basisinformationen des Benutzers in einem anderen Dienst gespeichert sind, ist, wie in der folgenden Abbildung gezeigt, bei jeder Verwendung der Basisinformationen des Benutzers eine Netzwerkinteraktion erforderlich. Noch inakzeptabler ist, dass selbst wenn nur das Geschlechtsattribut des Benutzers benötigt wird, alle Benutzerinformationen abgefragt und abgerufen werden müssen.
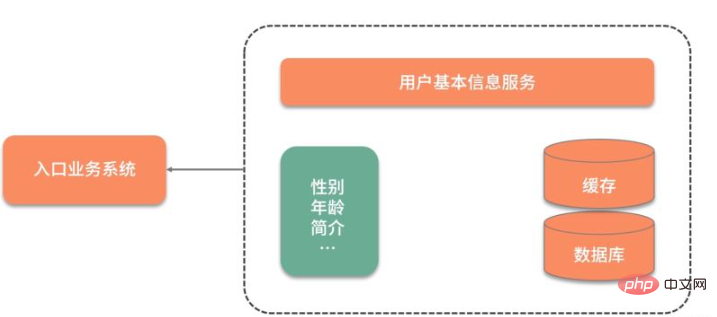
Um die Datenabfrage zu beschleunigen, wurden die Daten zunächst zwischengespeichert und in Redis abgelegt. Die Abfrageleistung wurde erheblich verbessert, es mussten jedoch immer noch viele redundante Daten abgefragt werden.
Der ursprüngliche Redis-Schlüssel ist wie folgt gestaltet:
type: string
key: user_${userid}
value: jsonBei diesem Design gibt es zwei Probleme:
Um den Wert eines bestimmten Felds abzufragen, müssen Sie alle JSON-Daten abfragen und selbst analysieren.
Eins aktualisieren von ihnen Der Wert des Feldes erfordert die Aktualisierung der gesamten JSON-Zeichenfolge, was kostspielig ist.
Für diese Art von großkörnigen JSON-Informationen können sie auf verstreute Weise optimiert werden, sodass jede Aktualisierung und Abfrage ein fokussiertes Ziel hat.
Als nächstes haben wir die Daten in Redis wie folgt entworfen und dabei eine Hash-Struktur anstelle einer JSON-Struktur verwendet:
type: hash
key: user_${userid}
value: {sex:f, id:1223, age:23}Auf diese Weise können wir den Befehl hget oder hmget verwenden, um die gewünschten Daten abzurufen und den Informationsfluss zu beschleunigen . .
Bitmap verkleinert Objekte
Kann es zusätzlich zu den oben genannten Vorgängen weiter optimiert werden? Beispielsweise werden die Geschlechtsdaten des Benutzers in unserem System häufig verwendet, um einige Geschenke zu verteilen, einige Freunde des anderen Geschlechts zu empfehlen, Benutzer regelmäßig zu reinigen, usw. oder um einige Benutzerstatusinformationen zu speichern, z online sind und ob sie eingecheckt haben, ob kürzlich Informationen gesendet wurden usw., um aktive Benutzer zu zählen usw. Dann kann die Operation der beiden Werte von Ja und Nein mithilfe der Bitmap-Struktur komprimiert werden.
这里还有个高频面试问题,那就是 Java 的 Boolean 占用的是多少位?
在 Java 虚拟机规范里,描述是:将 Boolean 类型映射成的是 1 和 0 两个数字,它占用的空间是和 int 相同的 32 位。即使有的虚拟机实现把 Boolean 映射到了 byte 类型上,它所占用的空间,对于大量的、有规律的 Boolean 值来说,也是太大了。
如代码所示,通过判断 int 中的每一位,它可以保存 32 个 Boolean 值!
int a= 0b0001_0001_1111_1101_1001_0001_1111_1101;
Bitmap 就是使用 Bit 进行记录的数据结构,里面存放的数据不是 0 就是 1。还记得我们在之前 《分布式缓存系统必须要解决的四大问题》中提到的缓存穿透吗?就可以使用 Bitmap 避免,Java 中的相关结构类,就是 java.util.BitSet,BitSet 底层是使用 long 数组实现的,所以它的最小容量是 64。
10 亿的 Boolean 值,只需要 128MB 的内存,下面既是一个占用了 256MB 的用户性别的判断逻辑,可以涵盖长度为 10 亿的 ID。
static BitSet missSet = new BitSet(010_000_000_000);
static BitSet sexSet = new BitSet(010_000_000_000);
String getSex(int userId) {
boolean notMiss = missSet.get(userId);
if (!notMiss) {
//lazy fetch
String lazySex = dao.getSex(userId);
missSet.set(userId, true);
sexSet.set(userId, "female".equals(lazySex));
}
return sexSet.get(userId) ? "female" : "male";
}这些数据,放在堆内内存中,还是过大了。幸运的是,Redis 也支持 Bitmap 结构,如果内存有压力,我们可以把这个结构放到 Redis 中,判断逻辑也是类似的。
再插一道面试算法题:给出一个 1GB 内存的机器,提供 60亿 int 数据,如何快速判断有哪些数据是重复的?
大家可以类比思考一下。Bitmap 是一个比较底层的结构,在它之上还有一个叫作布隆过滤器的结构(Bloom Filter),布隆过滤器可以判断一个值不存在,或者可能存在。
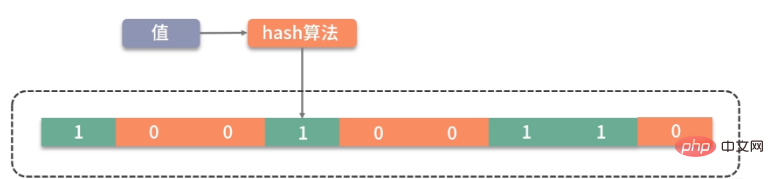
如图,它相比较 Bitmap,它多了一层 hash 算法。既然是 hash 算法,就会有冲突,所以有可能有多个值落在同一个 bit 上。它不像 HashMap一样,使用链表或者红黑树来处理冲突,而是直接将这个hash槽重复使用。从这个特性我们能够看出,布隆过滤器能够明确表示一个值不在集合中,但无法判断一个值确切的在集合中。
Guava 中有一个 BloomFilter 的类,可以方便地实现相关功能。
上面这种优化方式,本质上也是把大对象变成小对象的方式,在软件设计中有很多类似的思路。比如像一篇新发布的文章,频繁用到的是摘要数据,就不需要把整个文章内容都查询出来;用户的 feed 信息,也只需要保证可见信息的速度,而把完整信息存放在速度较慢的大型存储里。
数据的冷热分离
数据除了横向的结构纬度,还有一个纵向的时间维度,对时间维度的优化,最有效的方式就是冷热分离。
所谓热数据,就是靠近用户的,被频繁使用的数据;而冷数据是那些访问频率非常低,年代非常久远的数据。
同一句复杂的 SQL,运行在几千万的数据表上,和运行在几百万的数据表上,前者的效果肯定是很差的。所以,虽然你的系统刚开始上线时速度很快,但随着时间的推移,数据量的增加,就会渐渐变得很慢。
冷热分离是把数据分成两份,如下图,一般都会保持一份全量数据,用来做一些耗时的统计操作。
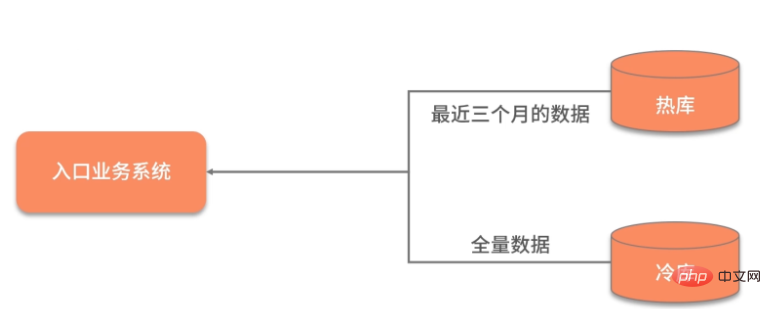
由于冷热分离在工作中经常遇到,所以面试官会频繁问到数据冷热分离的方案。下面简单介绍三种:
数据双写
把对冷热库的插入、更新、删除操作,全部放在一个统一的事务里面。由于热库(比如 MySQL)和冷库(比如 Hbase)的类型不同,这个事务大概率会是分布式事务。在项目初期,这种方式是可行的,但如果是改造一些遗留系统,分布式事务基本上是改不动的,我通常会把这种方案直接废弃掉。
写入 MQ 分发
通过 MQ 的发布订阅功能,在进行数据操作的时候,先不落库,而是发送到 MQ 中。单独启动消费进程,将 MQ 中的数据分别落到冷库、热库中。使用这种方式改造的业务,逻辑非常清晰,结构也比较优雅。像订单这种结构比较清晰、对顺序性要求较低的系统,就可以采用 MQ 分发的方式。但如果你的数据库实体量非常大,用这种方式就要考虑程序的复杂性了。
使用 Binlog 同步
针对 MySQL,就可以采用 Binlog 的方式进行同步,使用 Canal 组件,可持续获取最新的 Binlog 数据,结合 MQ,可以将数据同步到其他的数据源中。
思维发散
对于结果集的操作,我们可以再发散一下思维。可以将一个简单冗余的结果集,改造成复杂高效的数据结构。这个复杂的数据结构可以代理我们的请求,有效地转移耗时操作。
Zum Beispiel ist unser häufig verwendeter Datenbankindex eine Art Reorganisation und Beschleunigung von Daten. Der B+-Baum kann die Anzahl der Interaktionen zwischen der Datenbank und der Festplatte effektiv reduzieren. Er indiziert die am häufigsten verwendeten Daten über eine Datenstruktur ähnlich dem B+-Baum und speichert sie in einem begrenzten Speicherplatz.
Es gibt auch eine Serialisierung, die häufig in RPC verwendet wird. Einige Dienste verwenden das SOAP-Protokoll WebService, ein auf XML basierendes Protokoll. Die Übertragung großer Inhalte ist langsam und ineffizient. Die meisten heutigen Webdienste verwenden JSON-Daten für die Interaktion, und JSON ist effizienter als SOAP.
Außerdem sollte jeder von Googles Protobuf gehört haben. Da es ein binäres Protokoll ist und Daten komprimiert, ist seine Leistung sehr überlegen. Nachdem Protobuf die Daten komprimiert hat, beträgt die Größe nur 1/10 von JSON und 1/20 von XML, aber die Leistung wird um das 5- bis 100-fache verbessert.
Es lohnt sich, vom Design von protobuf zu lernen. Es verarbeitet die Daten sehr kompakt über die drei Abschnitte von tag|leng|value und die Analyse- und Übertragungsgeschwindigkeit ist sehr schnell.
Das obige ist der detaillierte Inhalt vonUmgang mit großen Objekten in Java. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!