
Heim >Backend-Entwicklung >Python-Tutorial >Acht Python-Bibliotheken zur Verbesserung der Produktivität der Datenwissenschaft!
Acht Python-Bibliotheken zur Verbesserung der Produktivität der Datenwissenschaft!

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-18 20:28:011374Durchsuche
1. Optuna
Optuna ist ein Open-Source-Framework zur Hyperparameteroptimierung, das automatisch den besten Wert für Modelle für maschinelles Lernen finden kann . Beste Hyperparameter.
Die einfachste (und wahrscheinlich bekannteste) Alternative ist GridSearchCV von sklearn, das mehrere Hyperparameterkombinationen ausprobiert und anhand einer Kreuzvalidierung die beste auswählt.
GridSearchCV versucht Kombinationen innerhalb des zuvor definierten Bereichs. Beispielsweise möchten Sie für einen zufälligen Waldklassifikator möglicherweise die maximale Tiefe mehrerer verschiedener Bäume testen. GridSearchCV stellt alle möglichen Werte für jeden Hyperparameter bereit und betrachtet alle Kombinationen.
Optuna verwendet seinen eigenen Versuchsverlauf innerhalb eines definierten Suchraums, um zu bestimmen, welche Werte als nächstes ausprobiert werden sollen. Die verwendete Methode ist ein Bayes'scher Optimierungsalgorithmus namens „Tree-structured Parzen Estimator“.
Dieser andere Ansatz bedeutet, dass statt sinnlos jeden Wert auszuprobieren, nach dem besten Kandidaten gesucht wird, bevor er ihn ausprobiert kann auch zu besseren Ergebnissen führen).
Schließlich ist es Framework-unabhängig, was bedeutet, dass Sie es mit TensorFlow, Keras, PyTorch oder jedem anderen ML-Framework verwenden können.
2, ITMO_FS
ITMO_FS ist eine Funktionsauswahlbibliothek, die eine Funktionsauswahl für ML-Modelle durchführen kann. Je weniger Beobachtungen Sie haben, desto vorsichtiger müssen Sie mit zu vielen Features umgehen, um eine Überanpassung zu vermeiden. Mit „vorsichtig“ meine ich, dass Sie Ihr Modell standardisieren sollten. Normalerweise ist ein einfacheres Modell (weniger Funktionen) leichter zu verstehen und zu interpretieren.
ITMO_FS-Algorithmen sind in 6 verschiedene Kategorien unterteilt: überwachte Filter, unüberwachte Filter, Wrapper, Hybride, eingebettet, Ensembles (obwohl sie sich hauptsächlich auf überwachte Filter konzentrieren).
Ein einfaches Beispiel für einen „überwachten Filter“-Algorithmus besteht darin, Features basierend auf ihrer Korrelation mit einer Zielvariablen auszuwählen. Mit der „Rückwärtsauswahl“ können Sie versuchen, Features einzeln zu entfernen und zu überprüfen, wie sich diese Features auf die Vorhersagefähigkeit des Modells auswirken.
Hier ist ein triviales Beispiel für die Verwendung von ITMO_FS und seine Auswirkungen auf Modellbewertungen:
>>> from sklearn.linear_model import SGDClassifier >>> from ITMO_FS.embedded import MOS >>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2) >>> sel = MOS() >>> trX = sel.fit_transform(X, y, smote=False) >>> cl1 = SGDClassifier() >>> cl1.fit(X, y) >>> cl1.score(X, y) 0.9033333333333333 >>> cl2 = SGDClassifier() >>> cl2.fit(trX, y) >>> cl2.score(trX, y) 0.9433333333333334
ITMO_FS ist eine relativ neue Bibliothek, daher immer noch etwas seltsam , aber ich empfehle trotzdem, es auszuprobieren. Bisher haben wir Bibliotheken für die Funktionsauswahl und Hyperparameter-Optimierung gesehen, aber warum? Was ist, wenn Sie nicht beides gleichzeitig verwenden können? Das ist es, was Shap-Hypetune tut.
Beginnen wir damit, zu verstehen, was „SHAP“ ist: Für die Interpretation der Ausgabe eines beliebigen maschinellen Lernmodells. „
SHAP ist eines davon Die am weitesten verbreiteten Bibliotheken dienen der Interpretation des Modells, indem sie die Bedeutung jedes Merkmals für die endgültige Vorhersage des Modells ermitteln.
Andererseits profitiert Shap-Hypertune von diesem Ansatz, um die besten Features und auch die besten Hyperparameter auszuwählen. Warum möchten Sie sie zusammenführen? Die unabhängige Auswahl von Features und die Optimierung von Hyperparametern können zu suboptimalen Entscheidungen führen, da ihre Wechselwirkungen nicht berücksichtigt werden. Wenn Sie beides gleichzeitig ausführen, wird dies nicht nur berücksichtigt, sondern auch etwas Programmierzeit gespart (obwohl sich die Laufzeit aufgrund des größeren Suchraums verlängern kann).
Die Suche kann auf drei Arten erfolgen: Rastersuche, Zufallssuche oder Bayes'sche Suche (außerdem kann sie parallelisiert werden).
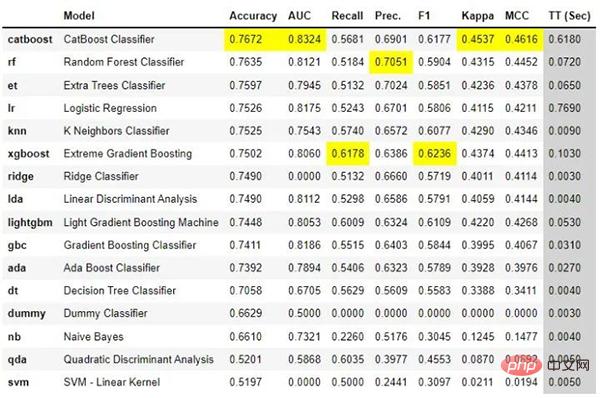
Shap-Hypertune funktioniert jedoch nur bei Gradienten-Boosting-Modellen! PyCaret ist eine Open-Source-Low-Code-Bibliothek für maschinelles Lernen, die Arbeitsabläufe für maschinelles Lernen automatisiert. Es umfasst explorative Datenanalyse, Vorverarbeitung, Modellierung (einschließlich Interpretierbarkeit) und MLOps. Schauen wir uns einige tatsächliche Beispiele auf ihrer Website an, um zu sehen, wie es funktioniert: 🎜🎜 #Mit nur wenigen Codezeilen können Sie mehrere Modelle ausprobieren und sie anhand der wichtigsten Klassifizierungsmetriken vergleichen.
Es ermöglicht auch die Erstellung einer Basisanwendung zur Interaktion mit dem Modell:
# load dataset
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# init setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# compare models
best = compare_models()Schließlich können API- und Docker-Dateien einfach für das Modell erstellt werden: # 🎜🎜#from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice,target = 'Purchase')
lr = create_model('lr')
create_app(lr) Einfacher geht es nicht, oder?
PyCaret ist eine sehr vollständige Bibliothek und es wäre schwierig, hier alles abzudecken. Es wird empfohlen, sie jetzt herunterzuladen und mit der Verwendung zu beginnen, um einige ihrer Funktionen in der Praxis zu verstehen.
5, floWeaver
FloWeaver kann Sankey-Diagramme aus Streaming-Datensätzen generieren. Wenn Sie nicht wissen, was ein Sankey-Diagramm ist, finden Sie hier ein Beispiel:
 zeigt einen Conversion-Trichter, eine Marketingreise oder ein Budget Zuordnung Sie sind sehr nützlich bei der Arbeit mit Daten (Beispiel oben). Die Portaldaten sollten im folgenden Format vorliegen: „Quelle x Ziel x Wert“. Es ist nur eine Codezeile erforderlich, um einen solchen Plot zu erstellen (sehr spezifisch, aber auch sehr intuitiv).
zeigt einen Conversion-Trichter, eine Marketingreise oder ein Budget Zuordnung Sie sind sehr nützlich bei der Arbeit mit Daten (Beispiel oben). Die Portaldaten sollten im folgenden Format vorliegen: „Quelle x Ziel x Wert“. Es ist nur eine Codezeile erforderlich, um einen solchen Plot zu erstellen (sehr spezifisch, aber auch sehr intuitiv).
6、Gradio
如果你阅读过敏捷数据科学,就会知道拥有一个让最终用户从项目开始就与数据进行交互的前端界面是多么有帮助。一般情况下在Python中最常用是 Flask,但它对初学者不太友好,它需要多个文件和一些 html、css 等知识。
Gradio 允许您通过设置输入类型(文本、复选框等)、功能和输出来创建简单的界面。尽管它似乎不如 Flask 可定制,但它更直观。
由于 Gradio 现在已经加入 Huggingface,可以在互联网上永久托管 Gradio 模型,而且是免费的!
7、Terality
理解 Terality 的最佳方式是将其视为“Pandas ,但速度更快”。这并不意味着完全替换 pandas 并且必须重新学习如何使用df:Terality 与 Pandas 具有完全相同的语法。实际上,他们甚至建议“import Terality as pd”,并继续按照以前的习惯的方式进行编码。
它快多少?他们的网站有时会说它快 30 倍,有时快 10 到 100 倍。
另一个重要是 Terality 允许并行化并且它不在本地运行,这意味着您的 8GB RAM 笔记本电脑将不会再出现 MemoryErrors!
但它在背后是如何运作的呢?理解 Terality 的一个很好的比喻是可以认为他们在本地使用的 Pandas 兼容的语法并编译成 Spark 的计算操作,使用Spark进行后端的计算。所以计算不是在本地运行,而是将计算任务提交到了他们的平台上。
那有什么问题呢?每月最多只能免费处理 1TB 的数据。如果需要更多则必须每月至少支付 49 美元。1TB/月对于测试工具和个人项目可能绰绰有余,但如果你需要它来实际公司使用,肯定是要付费的。
8、torch-handle
如果你是Pytorch的使用者,可以试试这个库。
torchhandle是一个PyTorch的辅助框架。它将PyTorch繁琐和重复的训练代码抽象出来,使得数据科学家们能够将精力放在数据处理、创建模型和参数优化,而不是编写重复的训练循环代码。使用torchhandle,可以让你的代码更加简洁易读,让你的开发任务更加高效。
torchhandle将Pytorch的训练和推理过程进行了抽象整理和提取,只要使用几行代码就可以实现PyTorch的深度学习管道。并可以生成完整训练报告,还可以集成tensorboard进行可视化。
from collections import OrderedDict
import torch
from torchhandle.workflow import BaseConpython
class Net(torch.nn.Module):
def __init__(self, ):
super().__init__()
self.layer = torch.nn.Sequential(OrderedDict([
('l1', torch.nn.Linear(10, 20)),
('a1', torch.nn.ReLU()),
('l2', torch.nn.Linear(20, 10)),
('a2', torch.nn.ReLU()),
('l3', torch.nn.Linear(10, 1))
]))
def forward(self, x):
x = self.layer(x)
return x
num_samples, num_features = int(1e4), int(1e1)
X, Y = torch.rand(num_samples, num_features), torch.rand(num_samples)
dataset = torch.utils.data.TensorDataset(X, Y)
trn_loader = torch.utils.data.DataLoader(dataset, batch_size=64, num_workers=0, shuffle=True)
loaders = {"train": trn_loader, "valid": trn_loader}
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = {"fn": Net}
criterion = {"fn": torch.nn.MSELoss}
optimizer = {"fn": torch.optim.Adam,
"args": {"lr": 0.1},
"params": {"layer.l1.weight": {"lr": 0.01},
"layer.l1.bias": {"lr": 0.02}}
}
scheduler = {"fn": torch.optim.lr_scheduler.StepLR,
"args": {"step_size": 2, "gamma": 0.9}
}
c = BaseConpython(model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
conpython_tag="ex01")
train = c.make_train_session(device, dataloader=loaders)
train.train(epochs=10)定义一个模型,设置数据集,配置优化器、损失函数就可以自动训练了,是不是和TF差不多了。
Das obige ist der detaillierte Inhalt vonAcht Python-Bibliotheken zur Verbesserung der Produktivität der Datenwissenschaft!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!