

 Technologie-PeripheriegeräteKIModellierung digitaler Zwillinge basierend auf maschinellem Lernen und eingeschränkter Optimierung
Technologie-PeripheriegeräteKIModellierung digitaler Zwillinge basierend auf maschinellem Lernen und eingeschränkter OptimierungModellierung digitaler Zwillinge basierend auf maschinellem Lernen und eingeschränkter Optimierung

Übersetzer |. Zhu Xianzhong
Rezensent | Zwillinge) – Digitale Zwillinge sind digitale Gegenstücke realer physischer Systeme oder Prozesse, die zur Simulation und Vorhersage des Eingabeverhaltens, zur Überwachung, Wartung, Planung usw. verwendet werden können. Während digitale Zwillinge wie kognitive Kundenservice-Bots in alltäglichen Anwendungen weit verbreitet sind, werde ich in diesem Artikel die beiden verschiedenen Typen für die Modellierung vergleichen, indem ich zwei verschiedene Arten von digitalen Zwillingen in der Industrie veranschauliche.
Zwei weit verbreitete datenwissenschaftliche Bereiche digitaler Zwillinge, die in diesem Artikel besprochen werden, sind wie folgt:
a) Diagnostische und prädiktive Analyse:Hier Bei analytischen Methoden wird der digitale Zwilling anhand einer Reihe von Eingaben verwendet, um die Ursache zu diagnostizieren oder das zukünftige Verhalten des Systems vorherzusagen. IoT-basierte Modelle des maschinellen Lernens werden verwendet, um intelligente Maschinen und Fabriken zu schaffen. Dieses Modell ermöglicht die Analyse von Sensoreingaben in Echtzeit, um zukünftige Probleme und Ausfälle zu diagnostizieren, vorherzusagen und zu verhindern, bevor sie auftreten.
b) Präskriptive Analyse: Diese Analysemethode simuliert das gesamte Netzwerk, sodass es anhand einer Reihe von Variablen und Einschränkungen, die eingehalten werden müssen, analysiert und die Situation bestimmt werden kann beste oder realisierbare Lösung aus einer großen Anzahl von Kandidaten, normalerweise mit dem Ziel, die angegebenen Geschäftsziele wie Durchsatz, Auslastung, Output usw. zu maximieren. Diese Optimierungsprobleme werden häufig im Bereich der Lieferkettenplanung und -planung eingesetzt, beispielsweise wenn ein Logistikdienstleister einen Zeitplan für seine Ressourcen (Fahrzeuge, Personal) erstellt, um die pünktliche Lieferung zu maximieren; die den Einsatz von Maschinen und Bedienern optimieren, um eine maximale OTIF-Lieferung (On Time In Full) zu erreichen. Die hier verwendete datenwissenschaftliche Technik ist die eingeschränkte mathematische Optimierung, ein Algorithmus, der leistungsstarke Löser verwendet, um komplexe entscheidungsgesteuerte Probleme zu lösen.
Zusammenfassend sagen ML-Modelle mögliche Ergebnisse für einen bestimmten Satz von Eingabemerkmalen auf der Grundlage historischer Daten voraus, und Optimierungsmodelle helfen Ihnen bei der Entscheidung, wie Sie bei Eintreten des vorhergesagten Ergebnisses eine Lösung/Abschwächung planen sollten. Nutzen Sie es aus, denn Ihr Unternehmen hat mehrere potenziell konkurrierende Ziele, die Sie möglicherweise mit begrenzten Ressourcen verfolgen möchten. Diese beiden Bereiche der Datenwissenschaft mobilisieren zwar einige Tools (z. B. Python-Bibliotheken), mobilisieren jedoch Datenwissenschaftler mit völlig unterschiedlichen Fähigkeiten – die oft unterschiedliche Denkweisen und Modellierung von Geschäftsproblemen erfordern. Versuchen wir also, die beteiligten Methoden zu verstehen und zu vergleichen, damit ein Datenwissenschaftler mit Erfahrung in einem Bereich Fähigkeiten und Techniken verstehen und nutzen kann, die möglicherweise in einem anderen Bereich anwendbar sind.
Anwendungsfall des digitalen Zwillingsmodells
Betrachten wir zum Vergleich ein Zwillingsmodell des ML-basierten Produktions-Ursachenanalyseprozesses (RCA: Root Cause Analysis), dessen Zweck Ist die Diagnose der Grundursache von Mängeln oder Anomalien, die im fertigen Produkt oder Herstellungsprozess festgestellt wurden. Dies hilft Abteilungsleitern, die wahrscheinlichsten Grundursachen auf der Grundlage der Vorhersagen des Tools zu beseitigen, letztendlich Probleme zu identifizieren und CAPA (Corrective & Preventive Actions: Korrektur- und Vorbeugemaßnahmen) umzusetzen und alle Maschinenwartungsaufzeichnungen schnell und ohne großen Personalaufwand zu durchsuchen Verlaufsaufzeichnungen, Prozess-SOP (Standard Operating Procedure: Standard Operating Procedure), IoT-Sensoreingabe usw. Ziel ist es, Maschinenstillstände und Produktionsausfälle zu minimieren und die Ressourcenauslastung zu verbessern.
Technisch gesehen kann dies als ein Klassifizierungsproblem mit mehreren Kategorien betrachtet werden. Bei diesem Problem versucht das Modell unter der Annahme, dass ein bestimmter Fehler vorliegt, die Wahrscheinlichkeit jedes einzelnen Satzes möglicher Grundursachenbezeichnungen vorherzusagen, z. B. maschinenbezogen, bedienerbezogen, verfahrensanweisungenbezogen, rohstoffbezogen usw. oder etwas anderes, sowie feinkörnige Gründe wie Maschinenkalibrierung, Maschinenwartung, Bedienerfähigkeiten, Bedienerschulung usw. unter diesen Klassifizierungsetiketten der ersten Ebene. Obwohl die optimale Lösung für diese Situation die Auswertung mehrerer komplexer ML-Modelle erfordert, lassen Sie uns, um den Zweck dieses Artikels hervorzuheben, etwas vereinfachen – nehmen wir an, dass es sich um ein multinomiales logistisches Regressionsproblem handelt (aus Gründen, die im nächsten Abschnitt erläutert werden). Abschnitt).
Zum Vergleich betrachten wir ein optimiertes Zwillingsmodell des Produktionsplanungsprozesses, das einen Zeitplan basierend auf Maschinen, Bedienern, Prozessschritten, Dauer, Rohstoffankunftsplänen, Ablaufdaten usw. erstellt. Versuchen, ein Ziel wie Ertrag oder Umsatz zu maximieren. Solche automatisierten Zeitpläne helfen Unternehmen, ihre Ressourcen schnell anzupassen, um auf neue Marktchancen zu reagieren (z. B. die Nachfrage nach Medikamenten aufgrund von COVID-19) oder die Auswirkungen ihrer Rohstoffe, Lieferanten, Logistikanbieter und des Kunden-/Marktmixes zu minimieren die Auswirkungen unvorhergesehener Ereignisse, wie z. B. jüngste Engpässe in der Lieferkette.
Auf einer grundlegenden Ebene für die Modellierung eines beliebigen Geschäftsproblems erfordert die Entwicklung eines solchen digitalen Zwillings die Berücksichtigung folgender Punkte: #B Eingabedaten – die Werte dieser Dimensionen
C. Regeln für die Transformation von Eingabe zu Ausgabe 🎜🎜#
A. Eingabefunktionen: Dies sind die Datendimensionen im System, die sowohl für ML als auch für die Optimierung geeignet sind. Für ein ML-Modell, das versucht, Probleme in einem Produktionsprozess zu diagnostizieren, könnten folgende Funktionen berücksichtigt werden: IoT-Eingaben, historische Maschinenwartungsdaten, Bedienerfähigkeiten und Schulungsinformationen, Informationen zur Rohstoffqualität, befolgte SOPs (Standard Operating Procedures) und andere Inhalte .
In ähnlicher Weise müssen in einer Optimierungsumgebung unter Randbedingungen folgende Merkmale berücksichtigt werden: Geräteverfügbarkeit, Bedienerverfügbarkeit, Rohstoffverfügbarkeit, Arbeitszeit, Produktivität, Fähigkeiten usw. typische Merkmale, die für die Entwicklung eines optimalen Produktionsplans erforderlich sind.
B. Eingabedaten: Hier verwenden die beiden oben genannten Methoden Eigenwerte auf deutlich unterschiedliche Weise. Unter anderem erfordern ML-Modelle für das Training eine große Menge an historischen Daten. Allerdings sind häufig erhebliche Arbeiten im Zusammenhang mit der Datenaufbereitung, -verwaltung und -normalisierung erforderlich, bevor Daten in ein Modell eingespeist werden können. Es ist wichtig zu beachten, dass ein Verlauf eine Aufzeichnung eines Ereignisses ist, das tatsächlich eingetreten ist (z. B. ein Maschinenausfall oder ein Problem mit den Fähigkeiten des Bedieners, das zu einer unzureichenden Leistung geführt hat), aber normalerweise keine einfache Kombination aller möglichen Werte ist, die diese haben Eigenschaften erhalten können. Mit anderen Worten: Der Transaktionsverlauf enthält mehr Datensätze für die Szenarien, die häufig auftreten, und relativ weniger Datensätze für einige andere Szenarien – möglicherweise selten, einschließlich Szenarios, die selten auftreten. Das Ziel des Modelltrainings besteht darin, die Beziehung zwischen Merkmalen und Ausgabebezeichnungen zu lernen und genaue Bezeichnungen vorherzusagen – selbst wenn die Trainingsdaten nur wenige oder keine Merkmalswerte oder Kombinationen von Merkmalswerten enthalten.
Andererseits werden bei Optimierungsmethoden die Kennwerte normalerweise als ihre tatsächlichen Daten beibehalten, z. B. Tage, Chargen, Fristen, Rohstoffverfügbarkeit nach Datum, Wartungspläne, Maschinenwechselzeiten, Prozessschritte, Bedienerfähigkeiten , usw. Der Hauptunterschied zu ML-Modellen besteht darin, dass die Eingabedatenverarbeitung die Erstellung einer Indextabelle für jede mögliche gültige Kombination von Stammdaten-Merkmalswerten (z. B. Tage, Fähigkeiten, Maschinen, Bediener, Prozesstypen usw.) erfordert, um eine Liste zu erstellen machbare Lösungen Teil. Beispielsweise verwendet Bediener A Maschine M1 am ersten Tag der Woche und führt Schritt 1 des Prozesses mit der Fähigkeitsstufe S1 aus, oder Bediener B verwendet Maschine M1 am zweiten Tag und führt Schritt 1 mit der Fähigkeitsstufe S2 aus; sogar für jede mögliche Kombination aus Bediener, Maschine, Qualifikationsniveau, Datum usw., unabhängig davon, ob diese Kombinationen tatsächlich in der Vergangenheit aufgetreten sind. Dies führt zu einem sehr großen Satz an Eingabedatensätzen, die der Optimierungsmaschine bereitgestellt werden. Das Ziel eines Optimierungsmodells besteht darin, eine bestimmte Kombination von Eigenwerten auszuwählen, die den gegebenen Einschränkungen entspricht und gleichzeitig die Zielgleichung maximiert (oder minimiert).
C. Eingabe-Ausgabe-Konvertierungsregeln: Dies ist auch ein wesentlicher Unterschied zwischen den beiden Methoden. Obwohl sowohl ML als auch Optimierungsmodelle auf fortgeschrittenen mathematischen Theorien basieren, erfordert die mathematische Modellierung und Programmierung komplexer Geschäftsprobleme in Optimierungsmethoden im Vergleich zu ML in der Regel mehr Aufwand, was sich in der folgenden Einführung widerspiegeln wird.
Der Grund dafür ist, dass in ML mit Hilfe von Open-Source-Bibliotheken wie scikit-learn, Frameworks wie Pytorch oder Tensorflow und sogar ML/Deep-Learning-Modellen von Cloud-Dienstanbietern die Regeln für die Umwandlung von Eingaben in Ausgaben vollständig außer Kraft gesetzt werden um das Modell zu finden, was auch die Aufgabe beinhaltet, eine Verlustkorrektur durchzuführen, um optimale Regeln (Gewichte, Verzerrungen, Aktivierungsfunktionen usw.) abzuleiten. Die Hauptaufgabe eines Datenwissenschaftlers besteht darin, die Qualität und Vollständigkeit der Eingabemerkmale und ihrer Werte sicherzustellen.
Bei Optimierungsmethoden ist dies nicht der Fall, da die Regeln dafür, wie die Eingaben interagieren und in Ausgaben umgewandelt werden, mithilfe detaillierter Gleichungen geschrieben und dann an Löser wie Gurobi, CPLEX usw. weitergeleitet werden müssen, um die zu finden optimaler oder realisierbarer Lösungsplan. Darüber hinaus erfordert die Formulierung von Geschäftsproblemen als mathematische Gleichungen ein tiefes Verständnis der Zusammenhänge im Modellierungsprozess und erfordert eine enge Zusammenarbeit von Datenwissenschaftlern mit Geschäftsanalysten.
Lassen Sie uns dies unten anhand eines schematischen Diagramms eines logistischen Regressionsmodells für eine problematische RCA-Anwendung (Root Cause Analysis) veranschaulichen:
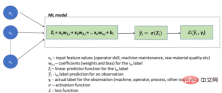
Logistisches Regressions-ML-Modell
Beachten Sie, dass in diesem Fall auf den Eingabedaten basiert Die Aufgabe, die Regeln (Zᵢ) zu berechnen, die die Ergebnisse generieren, wird dem Modell überlassen, um sie abzuleiten, während Datenwissenschaftler normalerweise damit beschäftigt sind, wohldefinierte Verwirrungsmatrizen, RMSE und andere Messtechniken zu verwenden, um visuell genaue Vorhersagen zu erzielen.
Wir können dies mit der Art und Weise vergleichen, wie Produktionspläne durch Optimierungsmethoden erstellt werden:
(I) Der erste Schritt besteht darin, die Geschäftsregeln (Einschränkungen) zu definieren, die den Planungsprozess kapseln.
Hier ist ein Beispiel für einen Produktionsplan:
Zuerst definieren wir einige Eingabevariablen (von denen einige Entscheidungsvariablen sein können, die zur Zielvorgabe verwendet werden):
- Bᵦ,p,ᵢ – Binäre Variable, die angibt, ob die Charge β (in der Chargentabelle) von Produkt p (in der Produkttabelle) am i-ten Tag geplant ist.
- Oₒ,p,ᵢ – Binäre Variable, die angibt, ob der Bediener am Index o (in der Bedienertabelle) am Tag i eine Charge von Produkt p verarbeiten soll.
- Mm,p,ᵢ – Binäre Variable, die angibt, ob die Maschine mit Index m (in der Maschinentabelle) am Tag i eine Charge von Produkt p verarbeiten soll.
und einige Koeffizienten:
- TOₒ, p – die Zeit, die Bediener o benötigt, um eine Produktcharge p zu verarbeiten.
- TMm,p – Die Zeit, die Maschine m benötigt, um eine Charge von Produkt p zu verarbeiten.
- OAvₒ,ᵢ – Die Anzahl der verfügbaren Stunden für den Operator-Index o am Tag i.
- MAvm,ᵢ – Die Anzahl der Stunden, die für die Maschine mit Index m am Tag i verfügbar sind.
In diesem Fall können einige Einschränkungen (Regeln) wie folgt umgesetzt werden:
a) Im Plan kann eine bestimmte Charge nur einmal gestartet werden.
Wobei für jede Produktcharge Bt die Gesamtzahl der Chargen, Pr die Gesamtzahl der Produkte und D die Anzahl der Tage im Plan ist:
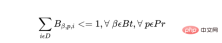
b) Ein Produkt kann nur gestartet werden einmal pro Tag an einem Bediener oder einer Maschine.
Für jeden Tag für jedes Produkt, wobei Op die Menge aller Bediener und Mc die Menge aller Maschinen ist:
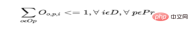
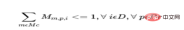
c) Die Gesamtzeit, die für die Charge (alle Produkte) aufgewendet wird, sollte nicht überschritten werden an diesem Tag Bediener- und Maschinenverfügbarkeitsstunden.
Für jeden Bediener gelten die folgenden Einschränkungen:
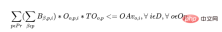
Für jeden Tag jeder Maschine gelten die folgenden Einschränkungen:
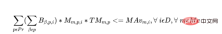
d) Wenn der Bediener innerhalb der ersten 5 Tage des Zeitplans eins bearbeitet Für jede Produktcharge müssen alle anderen Chargen desselben Produkts demselben Bediener zugewiesen werden. Dies gewährleistet die Kontinuität und Produktivität des Bedieners.
Für jeden Bediener und jedes Produkt gelten für jeden Tag d (ab Tag 6) die folgenden Einschränkungen:
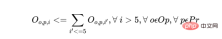
Die oben genannten sind einige der Hunderten von Einschränkungen, die dazu in das Programm geschrieben werden müssen Geschäftsregeln für tatsächliche Produktionsplanungsszenarien bilden mathematische Gleichungen. Beachten Sie, dass es sich bei diesen Einschränkungen um lineare Gleichungen (oder genauer gesagt um gemischte ganzzahlige Gleichungen) handelt. Der Komplexitätsunterschied zwischen ihnen und logistischen Regressions-ML-Modellen ist jedoch immer noch sehr offensichtlich.
(II) Sobald die Einschränkungen festgelegt sind, müssen die Ausgabeziele definiert werden. Dies ist ein entscheidender Schritt und kann ein komplexer Prozess sein, wie im nächsten Abschnitt erläutert.
(III) Schließlich werden die eingegebenen Entscheidungsvariablen, Einschränkungen und Ziele an den Löser gesendet, um die Lösung (Zeitplan) zu erhalten.
Ein schematisches Diagramm, das einen digitalen Zwilling basierend auf Optimierungsmethoden beschreibt, lautet wie folgt:
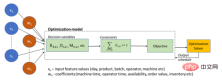
Optimierungsmodell
D, Ausgabe oder Ziel: Für ML-Modelle, abhängig von der Art des Problems (Klassifizierung, Regression, Clustering) können sehr gut etablierte Ausgaben und Metriken zur Messung ihrer Genauigkeit sein. Obwohl ich in diesem Artikel nicht weiter auf diese Themen eingehen werde, ist es angesichts der Fülle an verfügbaren Informationen erwähnenswert, dass die Ausgabe verschiedener Modelle mit einem hohen Grad an Automatisierung ausgewertet werden kann, wie beispielsweise die Ausgabe führender CSPs (AWS Sagemaker, Azure). ML usw.).
Die Beurteilung, ob ein optimiertes Modell die richtige Ausgabe generiert, ist schwieriger. Optimierungsmodelle funktionieren, indem sie versuchen, einen Rechenausdruck, der als „Ziel“ bezeichnet wird, zu maximieren oder zu minimieren. Ebenso wie Einschränkungen werden Ziele zum Teil von Datenwissenschaftlern auf der Grundlage dessen entworfen, was das Unternehmen erreichen möchte. Genauer gesagt wird dies erreicht, indem Belohnungsbedingungen und Strafbedingungen an Entscheidungsvariablen geknüpft werden, deren Summe der Optimierer zu maximieren versucht. Bei realen Problemen sind viele Iterationen erforderlich, um die richtigen Gewichtungen für verschiedene Ziele zu finden und so ein gutes Gleichgewicht zwischen manchmal widersprüchlichen Zielen zu finden.
Um das obige Produktionsplanungsbeispiel weiter zu veranschaulichen, könnten wir genauso gut die folgenden zwei Ziele entwerfen:
a) Der Zeitplan sollte vorab geladen werden; Chargen sollten so schnell wie möglich geplant werden, und die verbleibende Kapazität sollte im Plan enthalten sein sollte am Ende des Plans stehen. Wir können dies erreichen, indem wir einem Batch eine eintägige Strafe hinzufügen, die jeden Tag im Zeitplan schrittweise ansteigt.
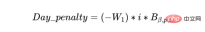
b) Andererseits möchten wir auch Chargen desselben Produkts gruppieren, damit der Ressourcenteil (Bediener und Maschine) optimal genutzt wird, vorausgesetzt, dass die Chargen den Liefertermin einhalten und die Gruppe die Maschinenkapazität nicht überschreitet. Daher definieren wir einen Batch_group_bonus, der einen höheren Bonus bietet (daher die Exponentialfunktion im folgenden Ausdruck), wenn die Chargen in größeren Gruppen statt in kleineren Gruppen angeordnet sind. Es ist wichtig zu beachten, dass sich dies manchmal mit früheren Zielen überschneiden kann, da einige Chargen, die möglicherweise heute beginnen, in einigen Tagen mit weiteren Chargen gestartet werden, sodass möglicherweise einige Ressourcen zu Beginn des Zeitplans nicht erfüllt werden.
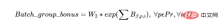
Je nachdem, wie der Solver funktioniert, ist in der eigentlichen Implementierungsmethode häufig eine Batch-Gruppen-Entscheidungsvariable erforderlich. Dies drückt jedoch das folgende Konzept aus:
Der Löser maximiert das Ziel, nämlich:
Ziel = Batch_group_bonus + Tagesstrafe
Welche der beiden oben genannten Komponenten des Ziels hat an einem bestimmten Tag des Zeitplans mehr Einfluss? Das Maximum hängt von den Gewichten W₁, W₂ und den Terminen des Zeitplans ab, da in den späteren Phasen des Zeitplans der Tagesstrafenwert allmählich größer wird (je höher der i-Wert). Wenn der Tagesstrafenwert irgendwann größer ist als der Batch_group_bonus, wird es der Planungslöser für ratsam halten, die Charge nicht zu planen. Daher wird eine Strafe von Null anfallen, selbst wenn im Plan Ressourcenkapazität vorhanden ist eine Netto-Negativstrafe, wodurch das Tor maximiert wird. Diese Probleme müssen von Datenwissenschaftlern behoben werden.
Relativer Arbeitsaufwandsvergleich zwischen ML-Methoden und Optimierungsmethoden
Basierend auf der obigen Diskussion kann gefolgert werden, dass Optimierungsprojekte im Allgemeinen mehr Aufwand erfordern als ML-Projekte. Die Optimierung erfordert umfangreiche datenwissenschaftliche Arbeiten in nahezu jeder Phase des Entwicklungsprozesses. Die spezifische Zusammenfassung lautet wie folgt:
a) Eingabedatenverarbeitung: Bei ML und Optimierung wird dies von Datenwissenschaftlern durchgeführt. Die ML-Datenverarbeitung erfordert die Auswahl relevanter Funktionen, Standardisierung, Diskretisierung usw. Für unstrukturierte Daten wie Text können NLP-basierte Methoden wie Merkmalsextraktion, Tokenisierung usw. enthalten sein. Derzeit gibt es auf mehreren Sprachen basierende Bibliotheken für die statistische Analyse von Merkmalen sowie Methoden zur Dimensionsreduktion wie PCA.
Bei der Optimierung weist jedes Unternehmen und jeder Plan Nuancen auf, die in das Modell integriert werden müssen. Optimierungsprobleme befassen sich nicht mit historischen Daten, sondern kombinieren alle möglichen Datenänderungen und identifizierten Merkmale in einem Index, von dem Entscheidungsvariablen und Einschränkungen abhängen müssen. Allerdings erfordert die Datenverarbeitung im Gegensatz zu ML viel Entwicklungsarbeit.
b) Modellentwicklung: Wie oben erwähnt, erfordert die Modellformulierung von Optimierungslösungen einen großen Aufwand von Datenwissenschaftlern und Geschäftsanalysten, um Einschränkungen und Ziele zu formulieren. Ein Löser führt mathematische Algorithmen aus, und obwohl er die Aufgabe hat, Hunderte oder sogar Tausende von Gleichungen gleichzeitig zu lösen, um eine Lösung zu finden, hat er keinen betriebswirtschaftlichen Hintergrund.
In ML ist das Modelltraining hochgradig automatisiert und Algorithmen werden als Open-Source-Bibliotheks-APIs oder von Cloud-Dienstanbietern gepackt. Hochkomplexe, vorab trainierte neuronale Netzwerkmodelle auf Basis geschäftsspezifischer Daten vereinfachen die Trainingsaufgabe bis in die letzten Schichten. Tools wie AWS Sagemaker Autopilot oder Azure AutoML können sogar den gesamten Prozess der Eingabedatenverarbeitung, Funktionsauswahl, Schulung und Bewertung verschiedener Modelle sowie Ausgabegenerierung automatisieren.
c) Testen und Ausgabeverarbeitung : In ML kann die Ausgabe eines Modells mit minimaler Verarbeitung genutzt werden. Es ist im Allgemeinen leicht zu verstehen (z. B. die Wahrscheinlichkeiten verschiedener Bezeichnungen), obwohl möglicherweise ein gewisser Aufwand erforderlich ist, um andere Aspekte einzuführen, beispielsweise die Interpretierbarkeit der Ergebnisse. Auch die Ausgabe- und Fehlervisualisierung erfordert möglicherweise etwas Aufwand, ist aber im Vergleich zur Eingabeverarbeitung nicht viel.
Auch hier erfordert das Optimierungsproblem iterative manuelle Tests und Validierungen mit dem geschulten Blick von Planungsexperten zur Beurteilung des Fortschritts. Während der Löser versucht, das Ziel zu maximieren, macht dies allein aus Sicht der Zeitplanqualität oft wenig Sinn. Im Gegensatz zu ML kann man nicht sagen, dass ein Zielwert oberhalb oder unterhalb eines Schwellenwerts einen richtigen oder falschen Plan beinhaltet. Wenn sich herausstellt, dass ein Zeitplan nicht mit den Geschäftszielen übereinstimmt, hängt das Problem möglicherweise mit Einschränkungen, Entscheidungsvariablen oder Zielfunktionen zusammen und erfordert eine sorgfältige Analyse, um die Ursache von Anomalien in großen, komplexen Zeitplänen zu finden.
Darüber hinaus ist die Entwicklung zu berücksichtigen, die erforderlich ist, um die Ausgabe des Lösers in ein für Menschen lesbares Format zu interpretieren. Der Löser übernimmt Eingabeentscheidungsvariablen, bei denen es sich um Indexwerte der tatsächlichen physischen Einheiten im Plan handelt, wie z. B. Chargengruppenindex, Chargenprioritätsindex, Bediener- und Maschinenindex, und gibt die ausgewählten Werte zurück. Um diese Indexwerte aus ihren jeweiligen Datenrahmen in eine kohärente Zeitleiste umzuwandeln, die von Experten visuell dargestellt und analysiert werden kann, ist eine umgekehrte Verarbeitung erforderlich.
d) Schließlich erfordern ML-Modelle selbst in der Betriebsphase im Vergleich zur Trainingsphase viel weniger Rechenaufwand und Zeit, um Beobachtungsvorhersagen zu generieren. Der Zeitplan wird jedoch jedes Mal von Grund auf neu erstellt und erfordert für jeden Lauf die gleichen Ressourcen.
Die folgende Abbildung ist eine grobe Darstellung der relativen Arbeitsbelastung jeder Phase von ML- und Optimierungsprojekten:
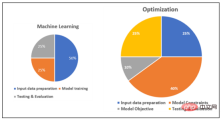
Schematisches Diagramm zum Vergleich der relativen Arbeitsbelastung von ML und Optimierung
Können ML und Optimierung zusammenarbeiten?
Maschinelles Lernen und Optimierung lösen komplementäre Probleme für Unternehmen; daher verstärken sich die Ergebnisse von ML-Modellen und Optimierung gegenseitig und umgekehrt. KI/ML-Anwendungen wie IoT Predictive Maintenance und Fehlererkennung, AR/VR-Fernwartung und der bereits erwähnte Produktionsprozess RCA sind Teil der Connected-Factory-Strategie des Herstellers.
Optimierungsanwendungen bilden die Grundlage der Supply-Chain-Planung und können als Verknüpfung der Geschäftsstrategie mit dem Betrieb betrachtet werden. Sie helfen Organisationen, auf unvorhergesehene Ereignisse zu reagieren und diese zu planen. Wenn beispielsweise in einer Produktionslinie ein Problem erkannt wird, helfen RCA-Tools (Root Cause Analysis) dem Produktionslinienmanager, die möglichen Ursachen schnell einzugrenzen und die erforderlichen Maßnahmen zu ergreifen. Dies kann jedoch manchmal zu unerwarteten Maschinenabschaltungen oder der Neuzuweisung von Betriebsanweisungen führen. Daher müssen Produktionspläne möglicherweise unter Nutzung der verfügbaren reduzierten Kapazität neu erstellt werden.
Einige ML-Techniken können auf die Optimierung angewendet werden und umgekehrt?
Erfahrungen aus ML-Projekten können auf Optimierungsprojekte angewendet werden; Beispielsweise ist bei einer Zielfunktion, die für die Optimierung der Ausgabe entscheidend ist, manchmal die Geschäftseinheit im Hinblick auf die mathematische Modellierung nicht so gut definiert wie die Einschränkungen, bei denen es sich um Regeln handelt, die befolgt werden müssen und daher normalerweise gut bekannt sind. Die Geschäftsziele lauten beispielsweise wie folgt:
a) Chargen sollen unter Einhaltung der Lieferfristen möglichst früh in der Prioritätsreihenfolge angeordnet werden.
b) Zeitpläne sollten vorab geladen werden; sie sollten mit möglichst kleinen Intervallen und mit geringer Ressourcenauslastung geplant werden.
c) Chargen sollten gruppiert werden, um die Kapazität effizient zu nutzen.
d) Bedienern mit einem höheren Qualifikationsniveau für hochwertige Produkte werden solche Chargen am besten zugewiesen.
Einige dieser Ziele haben möglicherweise konkurrierende Prioritäten, die richtig ausbalanciert werden müssen, was dazu führt, dass Datenwissenschaftler beim Verfassen komplexer Kombinationen von Einflussfaktoren (z. B. Boni und Strafen) oft das durchschreiben, was für die gängigste Planung zu gelten scheint Es geschieht durch Versuch und Irrtum, aber manchmal ist die Logik schwer zu verstehen und aufrechtzuerhalten, wenn Fehler auftreten. Da Optimierungslöser häufig Produkte von Drittanbietern verwenden, steht ihr Code den Datenwissenschaftlern, die die Modelle erstellen, die sie debuggen möchten, häufig nicht zur Verfügung. Dies macht es unmöglich, zu erkennen, welche Werte bestimmte Boni und Strafen zu einem bestimmten Zeitpunkt im Zeitplanerstellungsprozess angenommen haben, und es sind diese Werte, die dafür sorgen, dass es sich richtig verhält, was das Schreiben überzeugender Zielausdrücke sehr wichtig macht.
Der obige Ansatz trägt somit dazu bei, die Standardisierung von Boni und Strafen zu übernehmen, die eine weit verbreitete ML-Praxis ist. Die normalisierten Werte können dann mithilfe von Konfigurationsparametern oder anderen Mitteln auf kontrollierte Weise skaliert werden, um die Auswirkungen der einzelnen Faktoren, ihre Beziehung zueinander und die Werte der vorhergehenden und nachfolgenden Faktoren innerhalb jedes einzelnen Faktors zu steuern.
Fazit
Zusammenfassend lässt sich sagen, dass maschinelles Lernen und eingeschränkte Optimierung beides fortgeschrittene mathematische Methoden zur Lösung verschiedener Probleme in Organisationen und im täglichen Leben sind. Sie alle können verwendet werden, um digitale Zwillinge von physischen Geräten, Prozessen oder Netzwerkressourcen bereitzustellen. Während beide Arten von Anwendungen ähnlichen Entwicklungsprozessen auf hoher Ebene folgen, können ML-Projekte ein hohes Maß an Automatisierung nutzen, das in Bibliotheken und Cloud-nativen Algorithmen verfügbar ist, während die Optimierung eine enge Zusammenarbeit zwischen Unternehmen und Datenwissenschaftlern erfordert, um den komplexen Planungsprozess vollständig umzusetzen Modellieren. Im Allgemeinen erfordern Optimierungsprojekte mehr Entwicklungsarbeit und sind ressourcenintensiv. In der tatsächlichen Entwicklung müssen ML- und Optimierungstools in Unternehmen häufig zusammenarbeiten, und beide Technologien sind für Datenwissenschaftler nützlich.
Einführung in den Übersetzer
Zhu Xianzhong, 51CTO-Community-Redakteur, 51CTO-Expertenblogger, Dozent, Computerlehrer an einer Universität in Weifang und ein Veteran in der freiberuflichen Programmierbranche.
Originaltitel: Digital Twin Modeling Using Machine Learning and Constrained Optimization, Autor: Partha Sarkar
Das obige ist der detaillierte Inhalt vonModellierung digitaler Zwillinge basierend auf maschinellem Lernen und eingeschränkter Optimierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 KI -Therapeuten sind hier: 14 bahnbrechende Instrumente für psychische Gesundheit, die Sie wissen müssenApr 30, 2025 am 11:17 AM
KI -Therapeuten sind hier: 14 bahnbrechende Instrumente für psychische Gesundheit, die Sie wissen müssenApr 30, 2025 am 11:17 AMObwohl es nicht die menschliche Verbindung und Intuition eines ausgebildeten Therapeuten herstellen kann, hat die Forschung gezeigt, dass viele Menschen sich wohl fühlen, wenn sie ihre Sorgen und Bedenken mit relativ gesichtslosen und anonymen AI -Bots teilen. Ob dies immer ein gutes Ich ist
 Rufen Sie die KI zum Lebensmittelgang anApr 30, 2025 am 11:16 AM
Rufen Sie die KI zum Lebensmittelgang anApr 30, 2025 am 11:16 AMKünstliche Intelligenz (KI), eine Technologie -Jahrzehnte in der Herstellung, revolutioniert die Lebensmitteleinzelhandel. Von groß angelegten Effizienzgewinnen und Kostensenkungen bis hin zu optimierten Prozessen über verschiedene Geschäftsfunktionen hinweg sind die Auswirkungen von AI unzählig
 PEP -Gespräche von generativen KI erhalten, um Ihren Geist zu hebenApr 30, 2025 am 11:15 AM
PEP -Gespräche von generativen KI erhalten, um Ihren Geist zu hebenApr 30, 2025 am 11:15 AMReden wir darüber. Diese Analyse eines innovativen KI -Durchbruchs ist Teil meiner laufenden Forbes -Säulenberichterstattung über die neueste in der KI, einschließlich der Identifizierung und Erklärung verschiedener wirksamer KI -Komplexitäten (siehe Link hier). Außerdem für meinen Comp comp
 Warum AI-betriebene Hyperpersonalisierung ein Muss für alle Unternehmen istApr 30, 2025 am 11:14 AM
Warum AI-betriebene Hyperpersonalisierung ein Muss für alle Unternehmen istApr 30, 2025 am 11:14 AMDie Aufrechterhaltung eines professionellen Images erfordert gelegentliche Kleiderschrank -Updates. Während Online-Shopping bequem ist, fehlt es die Gewissheit von persönlichen Try-Ons. Meine Lösung? KI-betriebene Personalisierung. Ich stelle mir einen KI -Assistenten vor
 Vergessen Sie Duolingo: Die neue KI -Funktion von Google Translate lehrt SprachenApr 30, 2025 am 11:13 AM
Vergessen Sie Duolingo: Die neue KI -Funktion von Google Translate lehrt SprachenApr 30, 2025 am 11:13 AMGoogle Translate fügt die Funktion des Sprachlernens hinzu Laut Android Authority hat App Expert AssembleDeBug festgestellt, dass die neueste Version der Google Translate App eine neue "Praxis" -Modus des Testcode enthält, mit denen Benutzer ihre Sprachkenntnisse durch personalisierte Aktivitäten verbessern können. Diese Funktion ist derzeit für Benutzer unsichtbar, aber AssembleDeBug kann sie teilweise aktivieren und einige seiner neuen Elemente der Benutzeroberfläche anzeigen. Bei der Aktivierung fügt die Funktion am unteren Rand des Bildschirms ein neues Abschlusskapellymbol hinzu, das mit einem "Beta" -Anzeichen markiert wird, das anfällt, dass die Funktion "Praxis" anfänglich in experimenteller Form veröffentlicht wird. Die zugehörige Popup-Eingabeaufforderung zeigt "Üben Sie die für Sie zugeschnittenen Aktivitäten!", Dies bedeutet, dass Google individuell generiert wird
 Sie machen TCP/IP für KI und heißt NandaApr 30, 2025 am 11:12 AM
Sie machen TCP/IP für KI und heißt NandaApr 30, 2025 am 11:12 AMMIT -Forscher entwickeln Nanda, ein bahnbrechendes Webprotokoll für KI -Agenten. Nanda, kurz für vernetzte Agenten und dezentrale KI
 Die Eingabeaufforderung: DeepFake -Erkennung ist ein boomendes GeschäftApr 30, 2025 am 11:11 AM
Die Eingabeaufforderung: DeepFake -Erkennung ist ein boomendes GeschäftApr 30, 2025 am 11:11 AMMETAs neuestes Unternehmen: Eine KI -App zum Konkurrenz von Chatgpt Meta, die Muttergesellschaft von Facebook, Instagram, WhatsApp und Threads, startet eine neue AI-betriebene Anwendung. Diese eigenständige App, Meta AI, zielt darauf ab, direkt mit Openai's Chatgpt zu konkurrieren. Hebel
 Die nächsten zwei Jahre in der KI -Cybersicherheit für GeschäftsführerApr 30, 2025 am 11:10 AM
Die nächsten zwei Jahre in der KI -Cybersicherheit für GeschäftsführerApr 30, 2025 am 11:10 AMNavigation der steigenden Flut von AI -Cyber -Angriffen In jüngster Zeit unterstrich Jason Clinton, Ciso für anthropische, die aufkommenden Risiken, die mit nichtmenschlichen Identitäten gebunden sind-als Kommunikation mit Maschine zu Maschinen, die diese "Identitäten" schützen, werden werden


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

PHPStorm Mac-Version
Das neueste (2018.2.1) professionelle, integrierte PHP-Entwicklungstool

Dreamweaver CS6
Visuelle Webentwicklungstools

SecLists
SecLists ist der ultimative Begleiter für Sicherheitstester. Dabei handelt es sich um eine Sammlung verschiedener Arten von Listen, die häufig bei Sicherheitsbewertungen verwendet werden, an einem Ort. SecLists trägt dazu bei, Sicherheitstests effizienter und produktiver zu gestalten, indem es bequem alle Listen bereitstellt, die ein Sicherheitstester benötigen könnte. Zu den Listentypen gehören Benutzernamen, Passwörter, URLs, Fuzzing-Payloads, Muster für vertrauliche Daten, Web-Shells und mehr. Der Tester kann dieses Repository einfach auf einen neuen Testcomputer übertragen und hat dann Zugriff auf alle Arten von Listen, die er benötigt.

