
Heim >Java >javaLernprogramm >Java-Webinstanzanalyse
Java-Webinstanzanalyse

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-17 21:55:011340Durchsuche
Text
In tatsächlichen Arbeitsprojekten ist der Cache zu einer Schlüsselkomponente einer Architektur mit hoher Parallelität und hoher Leistung geworden. Warum kann Redis also als Cache verwendet werden? Erstens können zwei Hauptmerkmale des Caches verwendet werden:
Im hierarchischen System weist der Speicher/die CPU eine gute Zugriffsleistung auf,
Die Cache-Daten sind gesättigt und es liegen gute Daten vor Eliminierungsmechanismus
Da Redis natürlich ist Mit diesen beiden Eigenschaften basiert Redis auf Speicheroperationen und verfügt über einen vollständigen Dateneliminierungsmechanismus, wodurch es sich sehr gut als Cache-Komponente eignet.
Unter diesen kann die Kapazität je nach Speicherbetrieb 32-96 GB betragen, die Betriebszeit beträgt durchschnittlich 100 ns und die Betriebseffizienz ist hoch. Darüber hinaus gibt es nach Redis 4.0 viele Dateneliminierungsmechanismen. Es gibt 8 Typen, wodurch Redis auf viele Szenarien als Cache anwendbar ist.
Warum benötigt der Redis-Cache einen Dateneliminierungsmechanismus? Was sind die 8 Dateneliminierungsmechanismen?
Dateneliminierungsmechanismus
Der Redis-Cache basiert auf dem Speicher, daher ist seine Cache-Kapazität begrenzt. Wie soll Redis damit umgehen, wenn der Cache voll ist?
Redis Wenn der Cache voll ist, benötigt Redis einen Cache-Daten-Eliminierungsmechanismus, um einige Daten durch bestimmte Eliminierungsregeln auszuwählen und zu löschen, damit der Cache-Dienst erneut verwendet werden kann. Welche Eliminierungsstrategien verwendet Redis also zum Löschen von Daten?
Nach Redis 4.0 gibt es 6+2 Redis-Cache-Eliminierungsstrategien, die in drei Kategorien unterteilt sind:
Keine Dateneliminierung
keine Eviction, keine Dateneliminierung. Wenn der Cache voll ist, wird Redis dies nicht tun Die direkte Bereitstellung von Diensten gibt einen Fehler zurück.
Im Schlüssel-Wert-Paar, das die Ablaufzeit festlegt,
volatile-random, im Schlüssel-Wert-Paar, das die Ablaufzeit festlegt,
volatile-ttl zufällig löschen Schlüssel-Wert-Paar, das die Ablaufzeit festlegt. Ja, die Löschung erfolgt basierend auf der Ablaufzeit. Je früher das Ablaufdatum liegt, desto früher wird es gelöscht.
volatile-lru, basierend auf dem LRU-Algorithmus (Least Latest Used) zum Filtern von Schlüssel-Wert-Paaren mit einer Ablaufzeit, Filtern von Daten basierend auf dem Prinzip der am wenigsten kürzlich verwendeten Version
volatile-lfu, unter Verwendung des LFU ( Algorithmus „Am wenigsten häufig verwendet“ Wählen Sie die Schlüssel-Wert-Paare mit festgelegter Ablaufzeit und die am seltensten verwendeten Schlüssel-Wert-Paare aus, um die Daten zu filtern.
In allen Schlüssel-Wert-Paaren
allkeys-random, zufällig Daten aus allen Schlüssel-Wert-Paaren auswählen und löschen
allkeys-lru, LRU-Algorithmus verwenden, um alle Daten zu filtern
allkeys-lfu, verwendet den LFU-Algorithmus, um alle Daten zu filtern tail stellt das MRU-Ende bzw. das LRU-Ende dar und repräsentiert die zuletzt verwendeten Daten bzw. die zuletzt am seltensten verwendeten Daten.
In der tatsächlichen Implementierung muss der LRU-Algorithmus verknüpfte Listen verwenden, um alle zwischengespeicherten Daten zu verwalten, was zusätzlichen Speicherplatzaufwand mit sich bringt. Darüber hinaus müssen beim Zugriff auf Daten die Daten in die MRU in der verknüpften Liste verschoben werden. Wenn auf eine große Datenmenge zugegriffen wird, werden viele Verschiebevorgänge für verknüpfte Listen durchgeführt, was sehr zeitaufwändig ist und die Leistung des Redis-Cache verringert .
Unter diesen werden LRU und LFU basierend auf den LRU- und Refcount-Attributen von RedisObject, der Objektstruktur von Redis, implementiert: konfigurierte Anzahl von Parametern maxmemory-samples Als Kandidatensatz werden die Daten mit dem kleinsten lru-Attributwert ausgewählt und eliminiert. 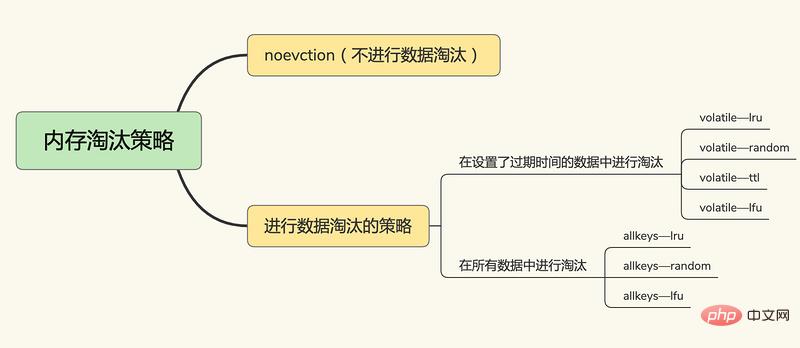
Die Top-Daten verwenden den volatile-lru-Algorithmus. Die Top-Daten legen keine Ablaufzeit fest und werden basierend auf LRU-Regeln gefiltert. Nachdem wir den Redis-Cache-Eliminierungsmechanismus verstanden haben, wollen wir sehen, wie viele Modi Redis als Cache hat? Redis-Cache-ModusBevorzugen Sie den allkeys-lru-Algorithmus, um die Daten, auf die zuletzt zugegriffen wurde, im Cache zu behalten und so die Leistung beim Anwendungszugriff zu verbessern.
- Der Redis-Cache-Modus kann in einen Nur-Lese-Cache und einen Lese-/Schreib-Cache unterteilt werden, je nachdem, ob Schreibanforderungen empfangen werden sollen: Nur-Lese-Cache: Verarbeitet nur Lesevorgänge, alle Aktualisierungsvorgänge befinden sich in der Datenbank Es besteht also die Gefahr eines Datenverlustes.
- Cache-Aside-Modus
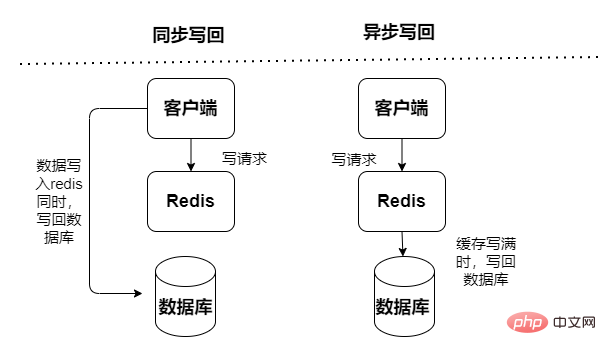
Lese- und Schreibcache, Lese- und Schreibvorgänge werden im Cache ausgeführt und ein Ausfall während der Ausfallzeit führt zu Datenverlust. Cache-Rückschreibdaten in die Datenbank werden in zwei Typen unterteilt: synchron und asynchron:
- Synchron: Die Zugriffsleistung ist gering, wodurch der Schwerpunkt mehr auf der Gewährleistung der Datenzuverlässigkeit liegt
Schreiben -Through-Modus
- Asynchron: Risiko von Datenverlust, der Schwerpunkt liegt auf der Bereitstellung eines Zugriffs mit geringer Latenz
Write-Behind-Modus
Cache-Aside-Modus
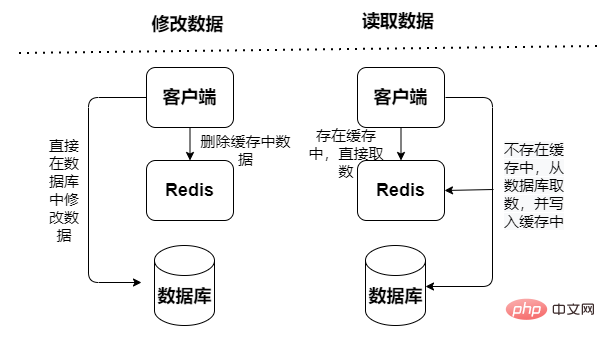
Abfragedaten liest zuerst die Daten aus dem Cache, wenn sie nicht im Cache vorhanden sind, liest dann die Daten aus der Datenbank und aktualisiert sie nach Erhalt der Daten im Cache, Aber beim Aktualisieren von Daten werden zuerst die Daten in der Datenbank aktualisiert und dann werden die Daten im Cache ungültig.
Und der Cache-Aside-Modus birgt Parallelitätsrisiken: Der Lesevorgang überspringt den Cache, und dann wird die Datenbank abgefragt, um die Daten abzurufen, aber gleichzeitig wurden sie nicht in den Cache gestellt. Ein Aktualisierungs-Schreibvorgang macht den Cache ungültig, und dann wird der Lesevorgang erneut ausgeführt. Die Abfrage lädt Daten in den Cache, was zu zwischengespeicherten fehlerhaften Daten führt.
Lese-/Schreibmodus
Abfragedaten und Aktualisierungsdaten greifen beide direkt auf den Cache-Dienst zu. Der Cache-Dienst aktualisiert die Daten synchron in der Datenbank. Die Wahrscheinlichkeit schmutziger Daten ist gering, sie hängt jedoch stark vom Cache ab und stellt höhere Anforderungen an die Stabilität des Cache-Dienstes. Synchrone Aktualisierungen führen jedoch zu einer schlechten Leistung.
Write Behind-Modus
Sowohl das Abfragen von Daten als auch das Aktualisieren von Daten greifen direkt auf den Cache-Dienst zu, aber der Cache-Dienst verwendet eine asynchrone Methode, um die Daten in der Datenbank zu aktualisieren (durch asynchrone Aufgaben). Es ist schnell und effizient, aber die Daten ist konsistent Es ist relativ schlecht, es kann zu Datenverlusten kommen und die Implementierungslogik ist auch relativ komplex.
Wählen Sie den Cache-Modus entsprechend den tatsächlichen Anforderungen des Geschäftsszenarios während der tatsächlichen Projektentwicklung. Warum müssen wir nach dem Verständnis des oben Gesagten den Redis-Cache in unserer Anwendung verwenden?
Die Verwendung des Redis-Cache in Anwendungen kann die Systemleistung und Parallelität verbessern, was sich hauptsächlich in
Hohe Leistung: basierend auf Speicherabfrage, KV-Struktur und einfachen logischen Operationen widerspiegelt
Hohe Parallelität: MySQL kann nur etwa 2000 pro Sekunde unterstützen Auf Wunsch übersteigt Redis leicht 1 W pro Sekunde. Wenn Sie zulassen, dass mehr als 80 % der Abfragen den Cache und weniger als 20 % der Abfragen die Datenbank durchlaufen, kann dies den Systemdurchsatz erheblich verbessern
Obwohl die Verwendung des Redis-Cache die Leistung des Systems erheblich verbessern kann, wird dies auch der Fall sein Bei der Verwendung des Caches kann es zu Problemen kommen, zum Beispiel zu bidirektionalen Inkonsistenzen zwischen Cache und Datenbank, Cache-Lawine usw. Wie können diese Probleme gelöst werden?
Häufige Probleme bei der Verwendung des Caches
Bei der Verwendung des Caches treten einige Probleme auf, die sich hauptsächlich in Folgendem widerspiegeln:
Inkonsistenz zwischen Cache- und Datenbank-Doppelschreibvorgängen
Cache-Lawine: Der Redis-Cache kann eine große Anzahl von Anwendungen nicht verarbeiten Anfragen, Übertragung an Die Datenbankschicht führt zu einem Druckanstieg auf die Datenbankschicht;
Cache-Penetration: Die Zugriffsdaten sind nicht im Redis-Cache und in der Datenbank vorhanden, was dazu führt, dass eine große Anzahl von Zugriffs-Penetrations-Caches direkt übertragen wird
Cache-Ausfall: Der Cache kann keine hochfrequenten Hot-Daten verarbeiten, was zu einem direkten Hochfrequenzzugriff auf die Datenbank führt, was zu einem Druckanstieg auf die Datenbankebene führt Datenbankschicht;
Der Cache stimmt nicht mit den Datenbankdaten überein.
Schreibgeschützter Cache (Cache-Aside-Modus)
Beim schreibgeschützten Cache (Cache-Aside-Modus) finden alle Lesevorgänge im Cache statt Dateninkonsistenzen treten nur bei Löschvorgängen auf (bei neuen Vorgängen nicht, da Neuzugänge nur in der Datenbank verarbeitet werden). Wenn ein Löschvorgang auftritt, markiert der Cache die Daten als ungültig und aktualisiert die Datenbank. Daher kommt es beim Aktualisieren der Datenbank und beim Löschen zwischengespeicherter Werte unabhängig von der Ausführungsreihenfolge der beiden Vorgänge zu Dateninkonsistenzen, solange ein Vorgang fehlschlägt.
Das obige ist der detaillierte Inhalt vonJava-Webinstanzanalyse. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!