
Heim >Datenbank >MySQL-Tutorial >Was sind die grundlegenden Probleme mit MySQL?
Was sind die grundlegenden Probleme mit MySQL?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-17 15:10:031048Durchsuche

Regelmäßiges Kapitel
1. Sprechen wir über die drei Hauptparadigmen von Datenbanken?
Erste Normalform: Feldatomarität, zweite Normalform: Zeilen sind eindeutig und haben Primärschlüsselspalten, dritte Normalform: Jede Spalte steht in Beziehung zur Primärschlüsselspalte.
In tatsächlichen Anwendungen wird eine kleine Anzahl redundanter Felder verwendet, um die Anzahl verwandter Tabellen zu reduzieren und die Abfrageeffizienz zu verbessern.
2. Es wird nur ein Datenelement abgefragt, aber die Ausführung ist sehr langsam. Was sind die häufigsten Gründe?
Die MySQL-Datenbank selbst ist blockiert, zum Beispiel: unzureichende System- oder Netzwerkressourcen.
-
SQL-Anweisungen sind blockiert, wie zum Beispiel: Tabellensperren, Zeilensperren usw., was dazu führt, dass die Speicher-Engine die entsprechenden Aktionen nicht ausführt SQL-Anweisungen
Es wird zwar durch unsachgemäße Verwendung des Index und keine Indizierung verursacht
Die Eigenschaften der Daten in der Tabelle werden verwendet, aber die Anzahl der Tabellenrückgaben ist riesig
3. count(*), count(0), Was sind die Unterschiede in der Implementierung von count(id)?
Für Zählfunktionen in der Form
count(*),count(constant),count(primary key), die Optimierer Sie können den Index mit den geringsten Scankosten auswählen, um die Effizienz zu verbessern. Ihre Ausführungsprozesse sind gleich.count(*)、count(常数)、count(主键)形式的count函数来说,优化器可以选择扫描成本最小的索引执行查询,从而提升效率,它们的执行过程是一样的。而对于
count(非索引列)来说,优化器选择全表扫描,说明只能在聚集索引的叶子结点顺序扫描。count(二级索引列)
count (non-index columns) wählt der Optimierer einen vollständigen Tabellenscan, was bedeutet, dass er nur die Blattknoten des Clustered-Index nacheinander scannen kann. 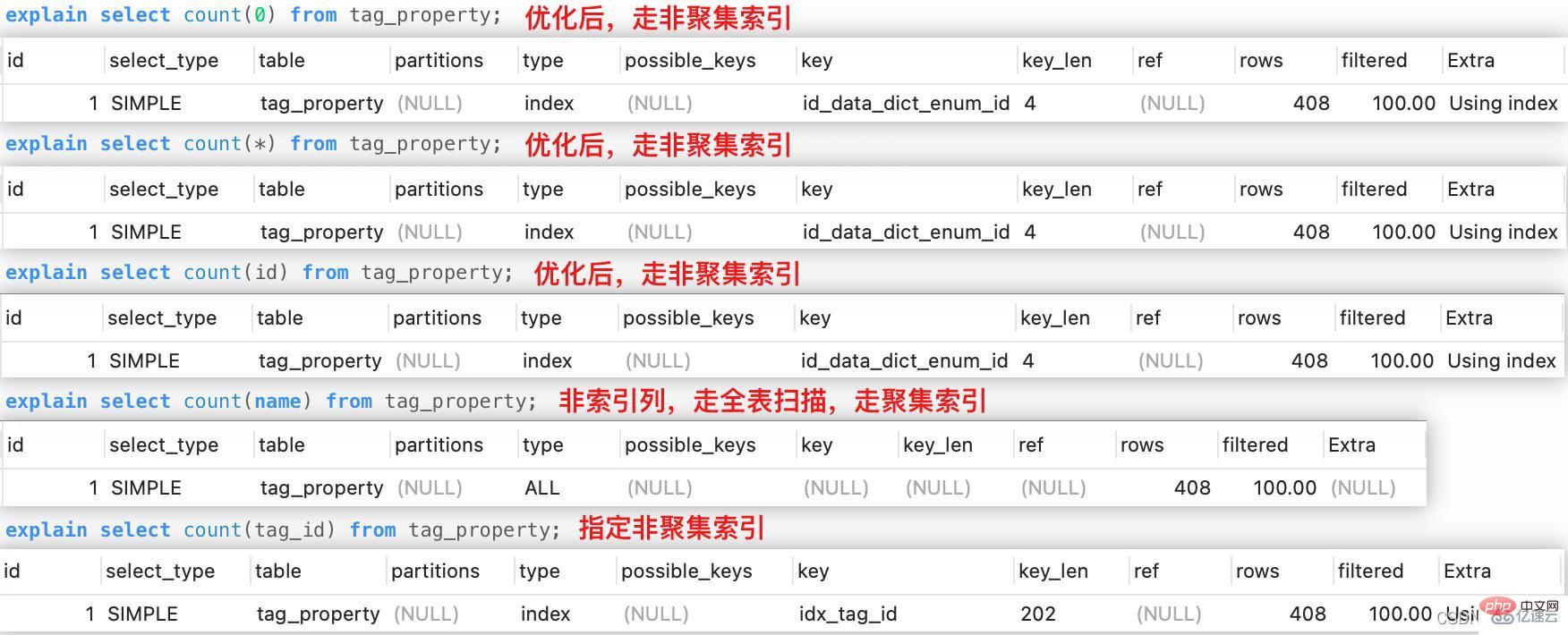
count (sekundäre Indexspalte) kann nur den Index auswählen, der die Spalten enthält, die wir zum Ausführen der Abfrage angeben, was dazu führen kann, dass die vom Optimierer ausgewählten Indexausführungskosten nicht die niedrigsten sind.
- 4. Was soll ich tun, wenn ich versehentlich Daten lösche?
- 1) Wenn die Datenmenge relativ groß ist, verwenden Sie das physische Backup xtrabackup. Führen Sie regelmäßig vollständige Sicherungen der Datenbank durch. Sie können auch inkrementelle Sicherungen durchführen.
- 2) Wenn die Datenmenge gering ist, verwenden Sie mysqldump oder mysqldumper und verwenden Sie dann binlog, um die Daten wiederherzustellen, oder richten Sie eine Master-Slave-Methode ein, um die Daten wiederherzustellen. Sie können die folgenden Punkte wiederherstellen:
- DML-Fehlbedienung Aussage: Sie können Flashback verwenden, um zuerst das Binlog-Ereignis zu analysieren und es dann umzukehren.
RM-Löschung: Verwenden Sie ein Backup, um computerraumübergreifend oder vorzugsweise stadtübergreifend zu speichern. 5. Der Unterschied zwischen Löschen, Abschneiden und Löschen Die Zeile wird zur Vereinfachung als Transaktionsdatensatz im Protokoll gespeichert. Führen Sie einen Rollback-Vorgang durch.
- TRUNCATE TABLE löscht alle Daten auf einmal aus der Tabelle und zeichnet keine einzelnen Löschvorgangsdatensätze im Protokoll auf. Gelöschte Zeilen können nicht wiederhergestellt werden. Und der mit der Tabelle verbundene Löschauslöser wird während des Löschvorgangs nicht aktiviert und die Ausführungsgeschwindigkeit ist hoch.
- Die Drop-Anweisung gibt den gesamten von der Tabelle belegten Platz frei.
- 6. Warum führt die Abfrage großer MySQL-Tabellen nicht zum Platzen des Speichers?
MySQL sendet beim Lesen, was bedeutet, dass der MySQL-Server die Ergebnisse nicht senden kann und die Transaktionsausführungszeit länger wird, wenn der Client langsam empfängt.
- Der Server muss keinen vollständigen Ergebnissatz speichern. Die Prozesse zum Abrufen und Senden von Daten werden alle über einen next_buffer abgewickelt.
- Speicherdatenseiten werden im Buffer Pool (BP) verwaltet.
- InnoDB verwaltet den Pufferpool mithilfe eines verbesserten LRU-Algorithmus, der mithilfe einer verknüpften Liste implementiert wird. Bei der InnoDB-Implementierung wird die gesamte verknüpfte LRU-Liste im Verhältnis 5:3 in junge Bereiche und alte Bereiche unterteilt, um sicherzustellen, dass heiße Daten nicht weggespült werden, wenn kalte Daten in großen Mengen geladen werden.
- 7. Wie gehe ich mit Deep Paging um (extrem großes Paging)?
Mit der ID optimieren: Finden Sie zuerst die maximale ID des letzten Pagings und verwenden Sie dann den Index für die ID, um ähnliches abzufragen um * vom Benutzer auszuwählen, wobei die ID>1000000 auf 100 begrenzt ist.
Mit abdeckendem Index optimieren: Wenn eine MySQL-Abfrage den Index vollständig erreicht, wird sie als abdeckender Index bezeichnet. Dies ist sehr schnell, da die Abfrage nur im Index suchen muss und zurückgeben kann direkt danach, anstatt zur Tabelle zurückzukehren, um die Daten abzurufen, können wir zuerst die ID des Index ermitteln und dann die Daten basierend auf der ID abrufen.
Begrenzen Sie die Anzahl der Seiten, wenn das Geschäft dies zulässt
8. Unter täglicher Entwicklung Wie Optimieren Sie SQL?
Geeignete Indizes hinzufügen: Indizieren Sie die Felder als Abfragebedingungen und sortieren Sie sie nach. Berücksichtigen Sie mehrere Abfragefelder, um einen kombinierten Index zu erstellen. Achten Sie dabei auf die Kombination Platzieren Sie in der Reihenfolge der Indexfelder die Spalten, die am häufigsten als restriktive Bedingungen verwendet werden, ganz links in absteigender Reihenfolge. Die Indizes sollten nicht zu viele sein, im Allgemeinen innerhalb von 5.
Tabellenstruktur optimieren: Numerische Felder sind besser als Zeichenfolgentypen, kleinere Datentypen sind normalerweise besser, versuchen Sie, NOT NULL zu verwenden
# 🎜 🎜#- Abfrageanweisungen optimieren: Analysieren Sie den SQL-Ausführungsplan, ob der Index erreicht wird usw. Wenn die SQL-Struktur sehr komplex ist, optimieren Sie die SQL-Struktur. Wenn die Menge der Tabellendaten zu groß ist, sollten Sie eine Aufteilung der Tabelle in Betracht ziehen #🎜 🎜#
- Im Ergebnis der Ausführung von show Processlist habe ich Tausende von Verbindungen gesehen, was sich auf gleichzeitige Verbindungen bezieht.
- Die Anweisung „aktuell ausgeführt“ ist eine gleichzeitige Abfrage.
- Die Anzahl gleichzeitiger Verbindungen wirkt sich auf den Speicher aus.
- Zu viele gleichzeitige Abfragen sind schlecht für die CPU. Eine Maschine verfügt über eine begrenzte Anzahl von CPU-Kernen und wenn alle Threads in Eile sind, sind die Kosten für den Kontextwechsel zu hoch.
- Es ist zu beachten, dass die Anzahl gleichzeitiger Threads um eins reduziert wird, nachdem der Thread in die Sperrwartezeit eintritt, sodass Threads, die auf Zeilensperren oder Lückensperren warten, nicht berücksichtigt werden im Zählbereich innerhalb. Das heißt, der Thread, der auf die Sperre wartet, beansprucht nicht die CPU und verhindert so, dass das gesamte System blockiert.
- Wenn die Daten identisch sind, wird keine Aktualisierung durchgeführt.
- Die Protokollverarbeitungsmethoden sind jedoch für verschiedene Binlog-Formate unterschiedlich:
- #🎜🎜 #1 ) Im Zeilenmodus gleicht die Serverschicht den zu aktualisierenden Datensatz ab und stellt fest, dass der neue Wert mit dem alten Wert übereinstimmt. Er kehrt direkt ohne Aktualisierung zurück und zeichnet das Binlog nicht auf.
- 2) Wenn MySQL auf einer Anweisung oder einem gemischten Format basiert, führt es die Update-Anweisung aus und zeichnet die Update-Anweisung im Binlog auf.
Der Datumsbereich von datetime ist 1001-9999; der Zeitbereich von timestamp ist 1970-2038
- # Der Speicher Der Speicherplatz für Datetime beträgt 8 Bytes; der Speicherplatz für Timestamp beträgt 4 Bytes
- Der Standardwert für Datetime ist null; null) und der Standardwert ist die aktuelle Zeit (current_timestamp)
12 Was sind die Isolationsstufen von Transaktionen?
- „Read Uncommitted“ ist die niedrigste Stufe und kann unter keinen Umständen garantiert werden
# 🎜🎜 #„Read Committed“ kann Dirty Reads vermeiden
- „Repeatable Read“ kann Dirty Reads und nicht wiederholbare Reads vermeiden.
„Serialisierbar“ kann das Auftreten von schmutzigen Lesevorgängen, nicht wiederholbaren Lesevorgängen und Phantom-Lesevorgängen vermeiden ist „Wiederholbares Lesen“
- 13 Es gibt zwei im MySQL-Kill-Befehl
- Abfrage + Thread-ID beenden, was bedeutet, dass die in diesem Thread ausgeführte Anweisung beendet wird bedeutet, diesen Thread zu trennen
- INDEX
#🎜 🎜#1 Was sind die Indexkategorien?
Je nach Inhalt des Blattknotens wird der Indextyp in Primärschlüsselindex und Nicht-Primärschlüsselindex unterteilt.
- Der Blattknoten des Primärschlüsselindex speichert die gesamte Datenzeile. In InnoDB wird der Primärschlüsselindex auch als Clustered-Index bezeichnet.
Der Inhalt von Blattknoten in Nicht-Primärschlüsselindizes ist der Wert des Primärschlüssels. In InnoDB werden Nicht-Primärschlüsselindizes auch Sekundärindizes genannt.
2. Was ist der Unterschied zwischen Clustered-Index und Non-Clustered-Index?
-
Clustered-Index: Ein Clustered-Index ist ein Index, der mit dem Primärschlüssel erstellt wird. Der Clustered-Index speichert die Daten in der Tabelle in den Blattknoten.

-
Nicht gruppierter Index: Der durch Nicht-Primärschlüssel erstellte Index speichert den Primärschlüssel und die Indexspalte im Blattknoten Primärschlüssel auf dem Blatt und überprüfen Sie dann die zu findenden Daten. (Der Vorgang, den Primärschlüssel abzurufen und dann danach zu suchen, wird als Tabellenrückgabe bezeichnet.)
Abdeckender Index: Angenommen, die abgefragten Spalten sind zufällig die Spalten, die dem Index entsprechen, und es besteht keine Notwendigkeit, zur Tabelle zurückzukehren, um nachzuschlagen, dann wird diese Indexspalte als a bezeichnet abdeckender Index.
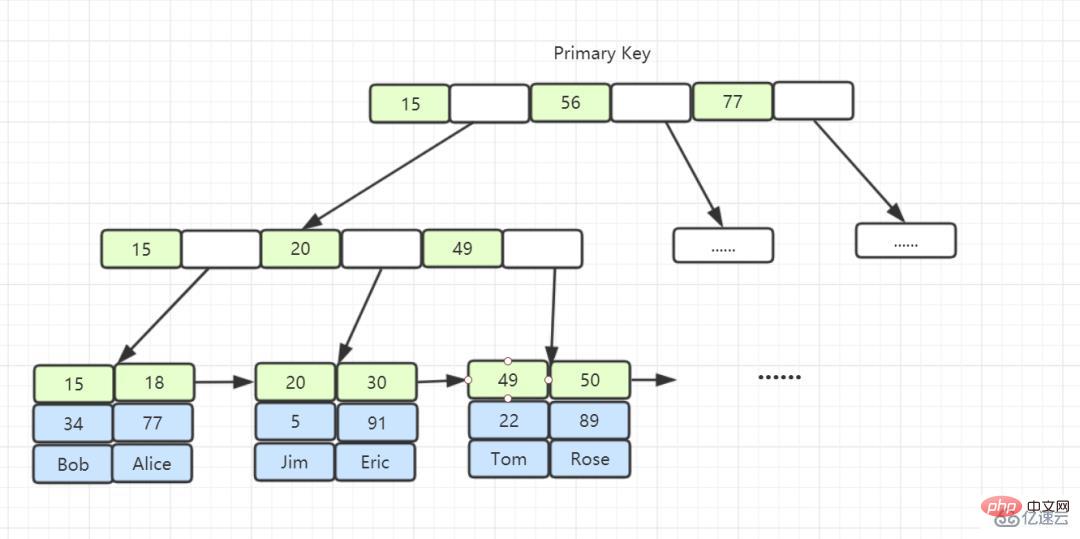
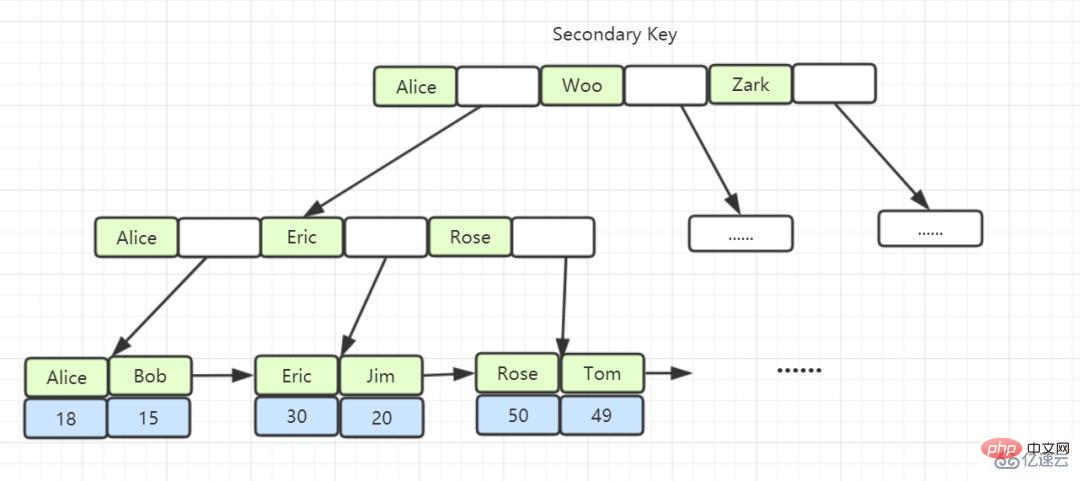
3. Warum entwirft InnoDB einen B+-Baum anstelle von B-Baum, Hash, Binärbaum und Rot-Schwarz-Baum?
Der Hash-Index kann das Hinzufügen, Löschen, Ändern und Abfragen einer einzelnen Datenzeile mit O(1)-Geschwindigkeit verarbeiten, führt jedoch bei Bereichsabfragen oder Sortierungen zu den Ergebnissen eines vollständigen Tabellenscans.
Der B-Baum kann Daten in Nicht-Blattknoten speichern. Da alle Knoten Zieldaten enthalten können, müssen wir den Teilbaum immer vom Wurzelknoten nach unten durchlaufen, um Datenzeilen zu finden, die die Bedingungen erfüllen Die Anzahl der zufälligen E/A-Vorgänge führt zu Leistungseinbußen.
Alle Datenzeilen des B+-Baums werden in Blattknoten gespeichert, und diese Blattknoten können der Reihe nach über „Zeiger“ verbunden werden. Wenn wir die Daten im B+-Baum wie unten gezeigt durchlaufen, können wir direkt zwischen mehreren durchsuchen Untergeordnete Knoten Das Springen zwischen Dateien kann viel Festplatten-E/A-Zeit sparen.
Binärbaum: Die Höhe des Baums ist ungleichmäßig und kann nicht selbstausgleichend sein. Die Sucheffizienz hängt von den Daten (der Höhe des Baums) ab und die IO-Kosten sind hoch.
Rot-Schwarz-Baum: Die Höhe des Baums nimmt mit zunehmender Datenmenge zu und die E/A-Kosten sind hoch.
4. Reden wir über Clustered-Index und Non-Clustered-Index?
In InnoDB speichert der Blattknoten des Index B+ Tree die gesamte Datenzeile und ist der Primärschlüsselindex, auch Clustered-Index genannt, der den Datenspeicher und den Index zusammenfügt. Sie finden die Daten.
Die Blattknoten des Index B + Baum speichern den Wert des Primärschlüssels, bei dem es sich um einen Nicht-Primärschlüsselindex handelt, der auch als nicht gruppierter Index und Sekundärindex bezeichnet wird.
Der erste Index ist normalerweise eine sequentielle E/A, und der Vorgang der Rückkehr zur Tabelle ist eine zufällige E/A. Je öfter wir zur Tabelle zurückkehren müssen, das heißt, je öfter wir zufällige E/A benötigen, desto mehr neigen wir dazu, vollständige Tabellenscans zu verwenden.
5. Werden nicht gruppierte Indizes definitiv Tabellenabfragen zurückgeben?
Dabei geht es nicht unbedingt darum, ob alle von der Abfrageanweisung benötigten Felder den Index erreichen. Wenn alle Felder den Index erreichen, besteht keine Notwendigkeit, eine Abfrage zurück an die Tabelle durchzuführen. Ein Index enthält (deckt) die Werte aller Felder ab, die abgefragt werden müssen, und wird als „Abdeckungsindex“ bezeichnet.
6. Erzählen Sie mir etwas über das Prinzip des ganz linken Präfixes von MySQL?
Das Präfixprinzip ganz links hat bei der Erstellung eines mehrspaltigen Index je nach Geschäftsanforderungen die am häufigsten verwendete Spalte in der Where-Klausel ganz links.
MySQL führt den Abgleich nach rechts fort, bis eine Bereichsabfrage (>, <, between, like) auftritt, und stoppt dann den Abgleich, z. B. a = 1 und b = 2 und c > 3 und d = 4 Wenn ein Index in der Reihenfolge a, b, c, d eingerichtet ist, wird d nicht für die Indizierung verwendet. Wenn Sie einen Index von (a, b, d, c) erstellen, kann er verwendet werden a, b, d können beliebig angepasst werden.
= und in können nicht in der richtigen Reihenfolge sein, z. B. a = 1 und b = 2 und c = 3. Sie können (a, b, c)-Indizes in beliebiger Reihenfolge erstellen. Der Abfrageoptimierer von MySQL hilft Ihnen bei der Optimierung in etwas, das an der Indexform erkennbar ist.
7. Was ist Index-Pushdown?
Wenn das Prinzip des Präfixes ganz links erfüllt ist, kann das Präfix ganz links zum Auffinden von Datensätzen im Index verwendet werden.
Vor MySQL 5.6 konnten Sie Tabellen nur einzeln, beginnend mit der ID, zurückgeben. Suchen Sie die Datenzeile im Primärschlüsselindex und vergleichen Sie dann die Feldwerte.
Die in MySQL 5.6 eingeführte Indexbedingungs-Pushdown-Optimierung (Index Condition Pushdown) kann zunächst die im Index enthaltenen Felder während des Indexdurchlaufprozesses beurteilen, Datensätze, die die Bedingungen nicht erfüllen, direkt herausfiltern und die Anzahl der Tabellen reduzieren kehrt zurück.
8. Warum verwendet Innodb die automatisch inkrementierende ID als Primärschlüssel?
Wenn die Tabelle einen automatisch inkrementierenden Primärschlüssel verwendet, werden die Datensätze jedes Mal, wenn ein neuer Datensatz eingefügt wird, nacheinander an der nachfolgenden Position des aktuellen Indexknotens hinzugefügt. Wenn eine Seite voll ist, entsteht eine neue Seite wird automatisch geöffnet. Wenn Sie einen nicht automatisch ansteigenden Primärschlüssel verwenden (z. B. ID-Nummer oder Studentennummer usw.), muss jeder neue Datensatz irgendwo in der Mitte eingefügt werden, da der Wert des jedes Mal eingefügten Primärschlüssels ungefähr zufällig ist Die vorhandene Indexseite verursachte häufig eine starke Fragmentierung und führte zu einer nicht kompakten Indexstruktur. Anschließend musste OPTIMIZE TABLE (Tabelle optimieren) verwendet werden, um die Tabelle neu aufzubauen und die gefüllten Seiten zu optimieren.
9. Wie wird die Transaktions-ACID-Funktion implementiert?
„Atomizität“: Wird mithilfe des Rückgängig-Protokolls implementiert. Wenn während der Transaktionsausführung ein Fehler auftritt oder der Benutzer ein Rollback ausführt, gibt das System den Status des Transaktionsstarts über das Rückgängig-Protokoll zurück.
„Persistenz“: Verwenden Sie das Redo-Protokoll, um dies zu erreichen. Solange das Redo-Protokoll bestehen bleibt, können die Daten bei einem Systemabsturz über das Redo-Protokoll wiederhergestellt werden.
„Isolation“: Verwenden Sie Sperren und MVCC, um Transaktionen voneinander zu isolieren.
„Konsistenz“: Erreichen Sie Konsistenz durch Rollback, Wiederherstellung und Isolation in gleichzeitigen Situationen.
10. Was ist der Unterschied zwischen der Art und Weise, wie MyISAM und InnoDB den B-Tree-Index implementieren?
InnoDB-Speicher-Engine: Die Blattknoten des B+-Baumindex speichern die Daten selbst;
MyISAM-Speicher-Engine: Die Blattknoten des B+-Baumindex speichern die physische Adresse der Daten; InnoDB, seine Datendatei selbst ist Indexdateien, im Vergleich zu MyISAM sind die Tabellendatendateien selbst eine von B+Tree organisierte Indexstruktur Der Schlüssel dieses Index ist der Primärschlüssel der Tabelle, daher ist die InnoDB-Tabellendatendatei selbst der Primärindex, der als „Clustered-Index“ oder Clustered-Index bezeichnet wird, und die übrigen Indizes dienen als Sekundärindizes Das Datenfeld des Sekundärindex speichert den Wert des Primärschlüssels des entsprechenden Datensatzes anstelle der Adresse. Dies unterscheidet sich ebenfalls von MyISAM.
- 11. Welche Indexkategorien gibt es?
Entsprechend dem Inhalt des Blattknotens wird der Indextyp in Primärschlüsselindex und Nicht-Primärschlüsselindex unterteilt.
Der Blattknoten des Primärschlüsselindex speichert die gesamte Datenzeile. In InnoDB wird der Primärschlüsselindex auch Clustered-Index genannt.
Der Inhalt von Blattknoten in Nicht-Primärschlüsselindizes ist der Wert des Primärschlüssels. In InnoDB werden Nicht-Primärschlüsselindizes auch Sekundärindizes genannt.
- 12. Welche Szenarien führen zu einem Indexausfall?
Hintergrund: Die vom B+-Baum bereitgestellte Fähigkeit zur schnellen Positionierung beruht auf der Ordnung der Geschwisterknoten auf derselben Ebene. Wenn diese Ordnung zerstört wird, wird sie daher höchstwahrscheinlich wie folgt fehlschlagen:
Verwenden Sie den linken oder linken Fuzzy-Matching für den Index: das heißt, wie %xx oder wie %xx%. Beide Methoden führen zu einem Indexfehler. Der Grund dafür ist, dass die Abfrageergebnisse möglicherweise „Chen Lin, Zhang Lin, Zhou Lin“ usw. lauten. Daher wissen wir nicht, mit welchem Indexwert wir den Vergleich beginnen sollen, und können daher nur über einen vollständigen Tabellenscan abfragen.
Funktionen für Indizes verwenden/Ausdrücke für Indizes berechnen: Da der Index den ursprünglichen Wert des Indexfelds speichert, nicht den von der Funktion berechneten Wert, gibt es natürlich keine Möglichkeit, den Index zu verwenden.
Implizite Typkonvertierung für den Index: entspricht der Verwendung einer neuen Funktion
Die Bedeutung von OR in der WHERE-Klausel besteht darin, dass nur eine der beiden Bedingungen erfüllt ist. Daher ist es bedeutungslos, dass nur eine bedingte Spalte eine ist Indexspalte Ja, solange die bedingte Spalte keine Indexspalte ist, wird ein vollständiger Tabellenscan durchgeführt.
Vorschlag
1. Es gibt ein System, das nicht in Datenbanken und Tabellen unterteilt ist, damit das System dynamisch auf Datenbanken und Tabellen umschalten kann.
Erweiterung stoppen (nicht empfohlen)
Double-Write-Migrationsplan: Entwerfen Sie den erweiterten Tabellenstrukturplan und implementieren Sie dann Dual-Write für die einzelne Datenbank und die Unterdatenbank, nachdem Sie dies eine Woche lang beobachtet haben Gibt es keine Probleme, schließen Sie die einzelne Datenbank. Beobachten Sie den Leseverkehr für eine Weile. Nachdem er stabil geblieben ist, schließen Sie den Schreibverkehr der einzelnen Datenbank und wechseln Sie reibungslos zur Unterdatenbank und Untertabelle.
2. Wie entwerfe ich eine Unterdatenbank- und Untertabellenlösung, die dynamisch erweitert und verkleinert werden kann?
Grundsätze
1. Was sind die Schritte zum Ausführen einer MySQL-Anweisung?
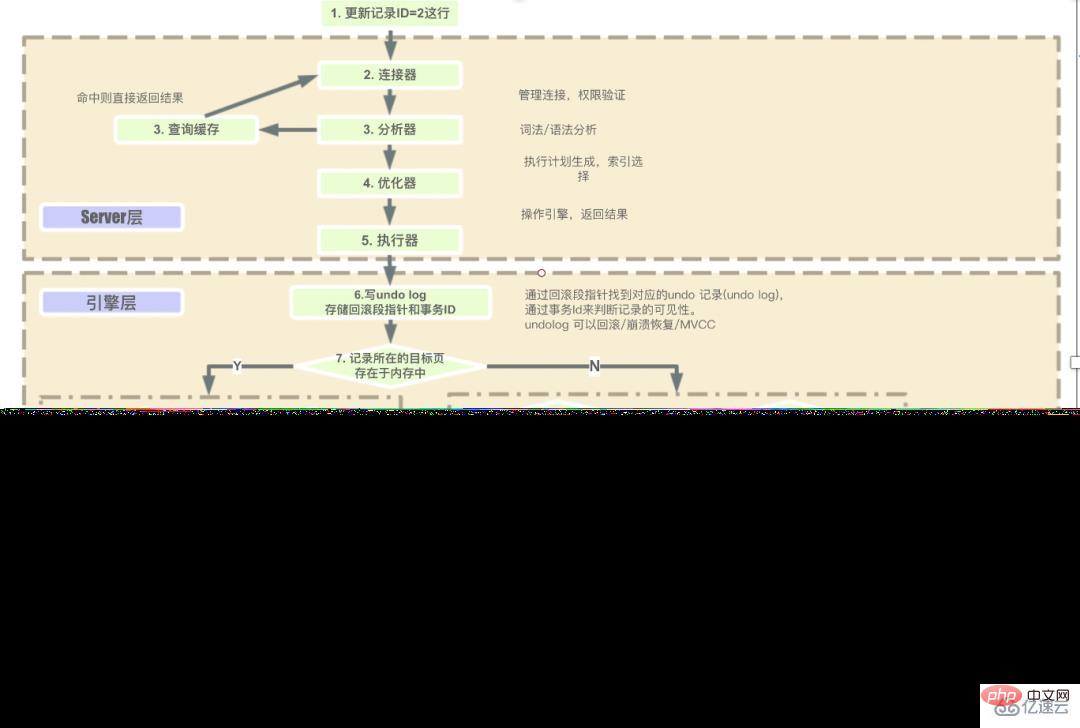
Die Schritte für die Serverebene zum Ausführen von SQL nacheinander sind:
Client-Anfrage –> Connector (Benutzeridentität überprüfen, Berechtigungen erteilen) –> Cache abfragen (direkt zurückgeben, wenn Cache vorhanden ist). , Wenn es nicht vorhanden ist, werden nachfolgende Vorgänge ausgeführt) -> Bevor die von dieser Engine bereitgestellte Schnittstelle verwendet wird, wird zunächst geprüft, ob der Benutzer über Ausführungsberechtigungen verfügt. -> Gehen Sie zur Engine-Ebene, um die Datenrückgabe zu erhalten (wenn der Abfrage-Cache aktiviert ist, werden die Abfrageergebnisse zwischengespeichert).
2. Was ist das interne Prinzip der Ordnung durch Sortieren?
MySQL weist jedem Thread einen Speicher (sort_buffer) zum Sortieren zu. Die Speichergröße ist sort_buffer_size.
Wenn die zu sortierende Datenmenge kleiner als sort_buffer_size ist, wird die Sortierung im Speicher abgeschlossen.
Wenn die Menge der sortierten Daten groß ist und der Speicher nicht so viele Daten speichern kann, werden temporäre Dateien auf der Festplatte zur Unterstützung der Sortierung verwendet, die auch als externe Sortierung bezeichnet wird.
Bei Verwendung der externen Sortierung teilt MySQL diese in mehrere separate temporäre Dateien auf, um die sortierten Daten zu speichern, und führt diese Dateien dann zu einer großen Datei zusammen.
3. MVCC-Implementierungsprinzip?
MVCC (Multiversion Concurrency Control) ist eine Möglichkeit, mehrere Versionen derselben Daten beizubehalten und so eine Parallelitätskontrolle zu erreichen. Suchen Sie beim Abfragen die Daten der entsprechenden Version über die Leseansicht und die Versionskette.
Funktion: Verbessern Sie die Parallelitätsleistung. Für Szenarien mit hoher Parallelität ist MVCC kostengünstiger als Sperren auf Zeilenebene.
Die Implementierung von MVCC basiert auf der Versionskette, die über drei versteckte Felder der Tabelle implementiert wird.
1) DB_TRX_ID: Aktuelle Transaktions-ID, die zeitliche Abfolge der Transaktion wird anhand der Größe der Transaktions-ID beurteilt.
2) DB_ROLL_PRT: Der Rollback-Zeiger zeigt auf die vorherige Version des aktuellen Zeilendatensatzes. Durch diesen Zeiger werden mehrere Versionen der Daten miteinander verbunden, um eine Undo-Log-Versionskette zu bilden.
3) DB_ROLL_ID: Primärschlüssel Wenn die Datentabelle keinen Primärschlüssel hat, generiert InnoDB automatisch einen Primärschlüssel.
4. Was ist ein Änderungspuffer und welche Funktion hat er?
5. Wie stellt MySQL sicher, dass keine Daten verloren gehen?
Solange Redolog und Binlog persistente Festplatten gewährleisten, kann der Binlog-Schreibmechanismus die Datenwiederherstellung nach einem abnormalen MySQL-Neustart sicherstellen.
redolog stellt sicher, dass verlorene Daten nach einer Systemausnahme wiederhergestellt werden können, und binlog archiviert Daten, um sicherzustellen, dass verlorene Daten wiederhergestellt werden können.
Redolog vor der Transaktionsausführung schreiben. Während der Transaktionsausführung wird das Protokoll zunächst in den Binlog-Cache geschrieben. Wenn die Transaktion übermittelt wird, wird der Binlog-Cache in die binlog-Datei geschrieben.
6. Warum bleibt die Größe der Tabellendatei auch nach dem Löschen der Tabelle unverändert?
Nachdem das Datenelement gelöscht wurde, markiert InnoDB Seite A als wiederverwendbar
Was ist mit dem Löschbefehl zum Löschen der gesamten Tabellendaten? Dadurch werden alle Datenseiten als wiederverwendbar markiert. Aber auf der Festplatte wird die Datei nicht kleiner.
Tabellen, die einer großen Anzahl von Hinzufügungen, Löschungen und Änderungen unterzogen wurden, können Lücken aufweisen. Diese Löcher nehmen auch Platz ein. Wenn diese Löcher also entfernt werden können, kann der Zweck der Verkleinerung des Tischraums erreicht werden.
Der Wiederaufbau des Tisches kann diesen Zweck erreichen. Sie können den Befehl alter table A engine=InnoDB verwenden, um die Tabelle neu zu erstellen.
7. Vergleich der drei Binlog-Formate
Das Binlog-Zeilenformat zeichnet die Primärschlüssel-ID der Operationszeile und den tatsächlichen Wert jedes Felds auf, sodass es keine Inkonsistenz in den Primär- und Sicherungsoperationsdaten gibt .
Anweisung: die aufgezeichnete Quell-SQL-Anweisung
gemischt: Die ersten beiden sind gemischt. Warum benötigen Sie eine Datei im gemischten Format, da einige Binlogs im Anweisungsformat zu Inkonsistenzen zwischen primärem und sekundärem Zeilenformat führen können? verwendet wird. Der Nachteil des Zeilenformats besteht jedoch darin, dass es viel Platz beansprucht. MySQL ist einen Kompromiss eingegangen. MySQL selbst ermittelt, ob diese SQL-Anweisung zu Inkonsistenzen zwischen dem primären und sekundären Server führen kann. Wenn möglich, wird das Zeilenformat verwendet, andernfalls wird das Anweisungsformat verwendet. 8. Sperrregeln für MySQL
Prinzip 2: Nur die Objekte, auf die während des Suchvorgangs zugegriffen wird, werden gesperrt
- Optimierung 1: Bei äquivalenten Abfragen im Index degeneriert die Next-Key-Sperre beim Sperren des eindeutigen Index in eine Zeilensperre.
- Optimierung 2: Bei äquivalenten Abfragen im Index degeneriert die Next-Key-Sperre in eine Lückensperre, wenn nach rechts gelaufen wird und der letzte Wert die Äquivalenzbedingung nicht erfüllt.
- Ein Fehler: auf der Ein eindeutiger Indexbereich fragt den Zugriff ab, bis der erste Wert die Bedingung nicht erfüllt.
- 9. Was sind Dirty Reads, Non-Repeatable Reads und Phantom Reads?
„Dirty Reading“: Unter Dirty Reading versteht man das Lesen nicht festgeschriebener Daten aus anderen Transaktionen, was bedeutet, dass die Daten möglicherweise zurückgesetzt werden, was bedeutet, dass sie am Ende möglicherweise nicht in der Datenbank gespeichert werden liegen keine Daten vor. Das Lesen von Daten, die möglicherweise nicht mehr vorhanden sind, wird als Dirty Reading bezeichnet.
„Nicht wiederholbares Lesen“: Nicht wiederholbares Lesen bezieht sich auf die Situation, in der innerhalb einer Transaktion die zu Beginn gelesenen Daten nicht mit demselben Datenstapel übereinstimmen, der zu irgendeinem Zeitpunkt vor dem Ende der Transaktion gelesen wurde.
- „Phantomlesung“: Phantomlesung bedeutet nicht, dass die durch zwei Lesevorgänge erhaltenen Ergebnismengen unterschiedlich sind. Der Schwerpunkt der Phantomlesung liegt darin, dass der Datenstatus des durch eine bestimmte Auswahloperation erhaltenen Ergebnisses nachfolgende Geschäftsvorgänge nicht unterstützen kann. Genauer gesagt: Wählen Sie aus, ob ein bestimmter Datensatz vorhanden ist, und bereiten Sie das Einfügen des Datensatzes vor. Bei der Ausführung wird jedoch festgestellt, dass der Datensatz bereits vorhanden ist und nicht eingefügt werden kann auftritt.
- 10. Welche Art von Sperren hat MySQL? Würden Sperren wie die oben genannten nicht die Effizienz der Parallelität beeinträchtigen?
In Bezug auf Sperrtypen gibt es gemeinsame Sperren und exklusive Sperren.
1) Gemeinsame Sperre: Auch Lesesperre genannt. Wenn der Benutzer Daten lesen möchte, kann den Daten eine gemeinsame Sperre hinzugefügt werden.
- 2) Exklusive Sperre: Wird auch als Schreibsperre bezeichnet. Wenn der Benutzer Daten schreiben möchte, kann den Daten nur eine exklusive Sperre hinzugefügt werden, und diese ist exklusiv mit anderen exklusiven Sperren und gemeinsam genutzten Sperren . .
- Die Granularität der Sperren hängt von der jeweiligen Speicher-Engine ab, die Sperren auf Zeilenebene, Sperren auf Seitenebene und Sperren auf Tabellenebene implementiert.
- Ihr Sperraufwand reicht von groß bis klein, und ihre Parallelitätsfähigkeiten reichen ebenfalls von groß bis klein.
- 1. Was ist das Prinzip der MySQL-Master-Slave-Replikation?
Master-Update-Ereignisse (Aktualisieren, Einfügen, Löschen) werden der Reihe nach in
bin-loggeschrieben. Wenn der Slave mit dem Master verbunden ist, öffnet der Master-Computer den Threadbinlog dumpfür den Slave und der Thread liest das Bin-Log-Protokoll.bin-log中。当Slave连接到Master的后,Master机器会为Slave开启binlog dump线程,该线程会去读取bin-log日志。Slave连接到Master后,Slave库有一个
I/O线程通过请求binlog dump thread读取bin-log日志,然后写入从库的relay log日志中。Slave还有一个
SQL线程2 Was sind die MySQL-Master-Slave-Replikationsmethoden?
-
Asynchrone Replikation:
MySQL-Master-Slave-Synchronisation Der Standardwert ist die asynchrone Replikation. Das heißt, von den oben genannten drei Schritten ist nur der erste Schritt synchron (dh Mater schreibt das Bin-Log-Protokoll), das heißt, die Master-Bibliothek kann nach dem Schreiben des Binlog-Protokolls erfolgreich zum Client zurückkehren, ohne auf das Binlog warten zu müssen Protokoll, das an die Slave-Bibliothek übertragen werden soll. -
Synchronische Replikation:
Bei synchroner Replikation wird, nachdem der Master-Host das Ereignis an den Slave-Host gesendet hat, eine Wartezeit ausgelöst, bis alle Slaves Der Knoten sendet (bei mehreren Slaves) Informationen über die erfolgreiche Datenreplikation an den Master zurück. - 3 Was verursacht die MySQL-Master-Slave-Synchronisationsverzögerung?
- Wenn der Masterknoten eine große Transaktion ausführt, hat dies einen größeren Einfluss auf die Master-Slave-Verzögerung # 🎜🎜# Netzwerkverzögerung, große Protokolle, zu viele Slaves
- Multi-Thread-Schreiben auf dem Master, nur Single-Thread-Synchronisation auf dem Slave-Knoten# 🎜 🎜#
- Probleme mit der Maschinenleistung, unabhängig davon, ob der Slave-Knoten eine „schlechte Maschine“ verwendet Ursache: Der SQL-Thread der Maschine wird langsam ausgeführt
Große Transaktion: Teilen Sie große Transaktionen in kleine Transaktionen auf und aktualisieren Sie Daten in Stapeln
- #🎜🎜 # Reduzieren Sie die Anzahl der Slaves auf nicht mehr als 5 und reduzieren Sie die Größe einer einzelnen Transaktion #🎜🎜 # Wenn ein Problem mit der Festplatte, der RAID-Karte oder der Planungsstrategie vorliegt, kann eine einzelne E/A-Verzögerung sehr hoch sein. Sie können das überprüfen IO-Situation des DB-Datenträgers und weiter gehen.
- 6. Was ist Bin-Log/Redo-Log/Undo-Log?
bin log ist eine Datei auf der MySQL-Datenbankebene. Sie zeichnet alle Vorgänge auf, die die MySQL-Datenbank ändern.
I/O-Thread, um das Bin-Log-Protokoll durch Anfrage zu lesen den Binlog-Dump-Thread und schreiben Sie dann in das relay log-Protokoll der Slave-Bibliothek. Slave verfügt außerdem über einen
SQL-Thread, der überwacht, ob der Inhalt des Relay-Log-Protokolls in Echtzeit aktualisiert wird, und die SQL-Anweisungen darin analysiert die Datei in der Datenbank ausführen. Halbsynchrone Replikation:
Bei halbsynchroner Replikation wird gewartet, nachdem der Master-Host das Ereignis an den Slave-Host gesendet hat ausgelöst werden, bis einer der Slave-Knoten (bei mehreren Slaves) Informationen über die erfolgreiche Datenreplikation an den Master zurücksendet.4 Was verursacht die MySQL-Master-Slave-Synchronisierungsverzögerung?
Das Redo-Log zeichnet die zu aktualisierenden Daten auf. Wenn beispielsweise ein Datenelement erfolgreich übermittelt wird, wird es nicht sofort mit der Festplatte synchronisiert zuerst im Redo-Log aufgezeichnet werden, warten Sie vor dem Leeren auf den richtigen Zeitpunkt, um die Haltbarkeit der Transaktion zu erreichen.
- Das Rückgängig-Protokoll wird für Datenabrufvorgänge verwendet. Es behält den Inhalt bei, bevor der Datensatz geändert wird. Ein Transaktions-Rollback kann durch das Rückgängig-Protokoll erreicht werden, und MVCC kann implementiert werden, indem auf der Grundlage des Rückgängig-Protokolls eine bestimmte Version der Daten zurückverfolgt wird.
Das obige ist der detaillierte Inhalt vonWas sind die grundlegenden Probleme mit MySQL?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!