
Heim >Backend-Entwicklung >Python-Tutorial >Python-Leistungsoptimierung aus Compiler-Perspektive
Python-Leistungsoptimierung aus Compiler-Perspektive

- 王林nach vorne
- 2023-04-15 11:46:051084Durchsuche
„Das Leben ist kurz, du brauchst Python“!
Ältere Programmierer lieben die Eleganz von Python. In einer Produktionsumgebung können jedoch beliebte Hochleistungsbibliotheken wie Python gefährlich sein TensorFlow oder PyTorch verwendet hauptsächlich Python als Schnittstellensprache für die Interaktion mit optimierten C/C++-Bibliotheken.
Es gibt viele Möglichkeiten, die Leistung von Python-Programmen zu optimieren, indem sie in eine niedrigere, statisch analysierbare Sprache wie C oder C++ kompiliert werden in nativen Maschinencode mit geringem Laufzeitaufwand, sodass die Leistung mit C/C++ vergleichbar ist.
Codon kann als ein solcher Compiler betrachtet werden, der eine vorzeitige Kompilierung, eine spezielle bidirektionale Typprüfung und eine neue bidirektionale Zwischendarstellung verwendet, um Optionalität in der Syntax der Sprache und Compileroptimierungen und eine domänenspezifische Erweiterung zu ermöglichen. Es ermöglicht professionellen Programmierern, leistungsstarken Code auf intuitive, hochwertige und vertraute Weise zu schreiben.
Im Gegensatz zu anderen leistungsorientierten Python-Implementierungen (wie PyPy oder Numba) wird Codon von Grund auf als eigenständiges System erstellt und vorab in eine statische ausführbare Datei kompiliert, ohne dass eine vorhandene Datei erforderlich ist Python-Laufzeit (z. B. CPython). Daher kann Codon grundsätzlich eine bessere Leistung erzielen und Python-Laufzeitprobleme wie globale Interpretersperren überwinden. In der Praxis kompiliert Codon Python-Skripte (wie ein C-Compiler) in nativen Code und läuft dabei 10 bis 100 Mal schneller als die interpretierte Ausführung.
1. Einführung in Codon
Codon basiert auf der Seq-Sprache, Seq Es handelt sich um eine Bioinformatik-DSL. Seq wurde ursprünglich als DSL im Pyramidenstil mit vielen Vorteilen konzipiert, wie z. B. einfacher Einführung, hervorragender Leistung und leistungsstarken Ausdrucksmöglichkeiten. Aufgrund strenger Typregeln unterstützt Seq jedoch nicht viele gängige Python-Sprachkonstrukte und bietet auch keinen Mechanismus zur einfachen Implementierung neuer Compileroptimierungen. Durch die Anwendung bidirektionaler IR und verbesserter Typprüfer bietet Codon eine allgemeine Lösung für diese Probleme basierend auf Seq.
Codon deckt die meisten Funktionen von Python ab und bietet ein Framework zum Erreichen domänenspezifischer Optimierungen. Darüber hinaus wird ein flexibles Typsystem bereitgestellt, um verschiedene Sprachfunktionen besser handhaben zu können. Das Typsystem ähnelt RPython und PyPy sowie dem statischen Typsystem. Diese Ideen wurden auch im Kontext anderer dynamischer Sprachen wie PRuby angewendet. Der von der bidirektionalen IR verwendete Ansatz weist Ähnlichkeiten mit Forward-Pluggable-Type-Systemen wie dem Inspektionsframework von Java auf.
Obwohl Codons Intermediate Expression nicht der erste anpassbare IR ist, unterstützt er nicht die Anpassung aller Inhalte, sondern entscheidet sich für eine einfache, klar definierte Anpassung, die in Kombination mit Bidirektionalität komplexere Funktionen erreichen kann. In Bezug auf die Struktur ist CIR von LLVM und Rusts IR inspiriert. Diese IRs profitieren von einem stark vereinfachten Knotensatz und einer stark vereinfachten Knotenstruktur, was wiederum die Implementierung von IR-Kanälen vereinfacht. Strukturell restrukturieren diese Implementierungen jedoch den Quellcode grundlegend und eliminieren semantische Informationen, die zur Durchführung der Transformation umgestaltet werden müssen. Um diesen Mangel zu beheben, übernimmt Taichi eine hierarchische Struktur, die den Kontrollfluss und die semantischen Informationen auf Kosten einer erhöhten Komplexität aufrechterhält. Im Gegensatz zu Codon sind diese IRs jedoch weitgehend unabhängig vom Front-End ihrer Sprache, was die Aufrechterhaltung der Typkorrektheit und die Generierung neuen Codes etwas unpraktisch oder sogar unmöglich macht. Daher nutzt CIR die vereinfachte Hierarchie dieser Methoden und behält die Kontrollflussknoten des Quellcodes und eine vollständig reduzierte Teilmenge interner Knoten bei. Wichtig ist, dass diese Struktur durch Bidirektionalität verbessert wird, wodurch neue IRs einfacher generiert und manipuliert werden können.
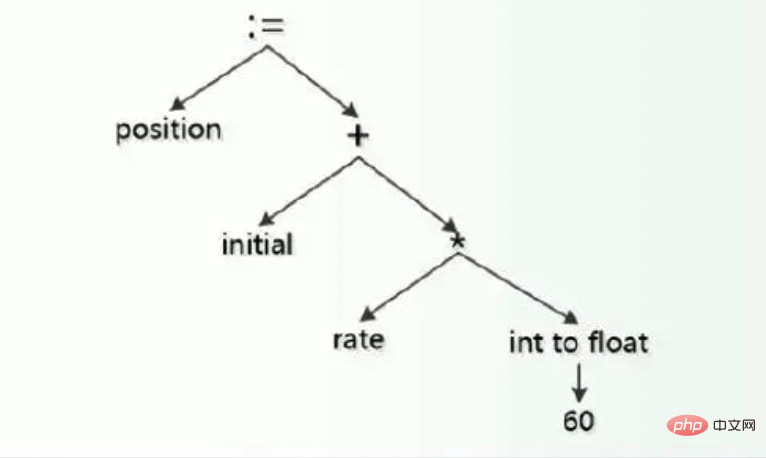
2. Typprüfung und Inferenz
Codon nutzt statische Typprüfung und kompiliert in LLVM IR ähnelt ohne Verwendung von Laufzeittypinformationen früheren Arbeiten zur End-to-End-Typprüfung im Kontext dynamischer Sprachen wie Python. Zu diesem Zweck wird Codon mit einem statischen Zwei-Wege-Typsystem namens LTS-DI ausgeliefert, das Rückschlüsse im HindleyMilner-Stil nutzt, um Typen im Programm abzuleiten, ohne dass der Benutzer die Typen manuell mit Anmerkungen versehen muss (dieser Ansatz wird zwar unterstützt, wird aber nicht unterstützt). wird in Python unterstützt. Unter Entwicklern nicht üblich).
Aufgrund der Natur der Python-Syntax und der gängigen pythonischen Redewendungen passt LTS-DI die Standard-HM-ähnliche Argumentation an, um prominente Python-Konstrukte wie Verständnis, Iteratoren, Generatoren, komplexe Funktionsoperationen, variable Parameter und Statik zu unterstützen Typprüfung usw. Um diese und viele andere Strukturen zu bewältigen, verlässt sich LTS-DI auf:
- Monomorphismus (instanziieren Sie eine separate Version einer Funktion für jede Kombination von Eingabeparametern)
- Lokalisierung (behandeln Sie jede Funktion als isolierte Typprüfeinheit)
- Verzögerte Instanziierung (Funktionsinstanziierung wird verzögert, bis alle Funktionsparameter bekannt sind) .
Viele Python-Konstrukte erfordern auch Ausdrücke zur Kompilierungszeit (ähnlich den komprimierten PR-Ausdrücken von C++), die vom Codon unterstützt werden. Während diese Ansätze in der Praxis keine Seltenheit sind (z. B. C++-Vorlagen verwenden Singletons) und die verzögerte Instanziierung bereits im HMF-Typsystem verwendet wird, ist uns ihre kombinierte Verwendung im Kontext typgeprüfter Python-Programme nicht bekannt. Bitte beachten Sie abschließend, dass das Typsystem von Codon in seiner aktuellen Implementierung vollständig statisch ist und keine Laufzeittypinferenz durchführt. Daher werden einige Python-Funktionen wie Laufzeitpolymorphismus oder Laufzeitreflexion nicht unterstützt. Im Kontext des wissenschaftlichen Rechnens hat sich herausgestellt, dass das Entfernen dieser Funktionen einen vernünftigen Kompromiss zwischen Nutzen und Leistung darstellt.
3. Zwischenausdrücke
Viele Sprachen lassen sich relativ einfach kompilieren: Der Quellcode wird in einen abstrakten Syntaxbaum (AST) geparst, optimiert und in Maschinencode umgewandelt, oft mit Hilfe eines Frameworks wie LLVM . Obwohl dieser Ansatz relativ einfach zu implementieren ist, enthält der AST häufig viel mehr Knotentypen, als zur Darstellung eines bestimmten Programms erforderlich sind. Diese Komplexität kann die Implementierung von Optimierung, Transformation und Analyse schwierig oder sogar unpraktisch machen. Ein anderer Ansatz besteht darin, die AST in eine Zwischendarstellung (IR) umzuwandeln, bevor der Optimierungsdurchlauf durchgeführt wird. Die Zwischendarstellung enthält normalerweise einen vereinfachten Satz von Knoten mit wohldefinierter Semantik, wodurch sie für die Konvertierung und Optimierung geeigneter sind.
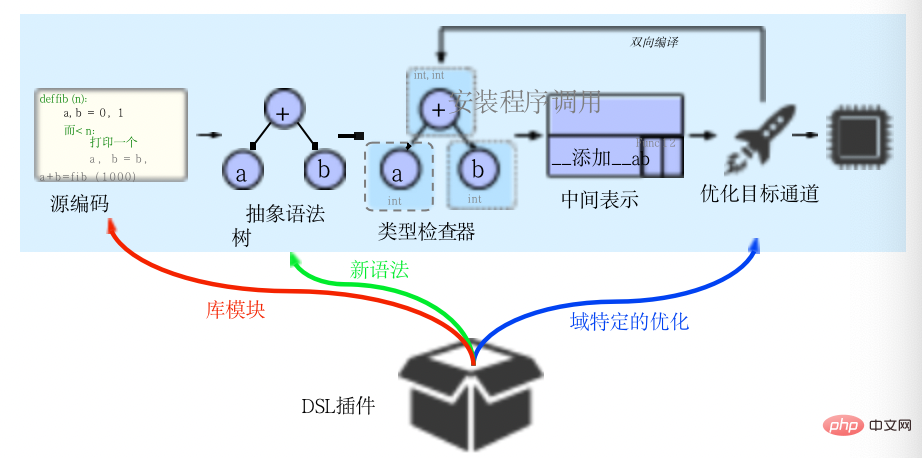
Codon implementiert diesen Ansatz in seiner IR, die zwischen der Typprüfungs- und der Optimierungsphase liegt, wie im Bild oben gezeigt. Die Codon-Zwischendarstellung (CIR) ist viel einfacher als die AST, mit einer einfacheren Struktur und weniger Knotentypen. Trotz ihrer Einfachheit behalten die Zwischendarstellungen von Codon einen Großteil der semantischen Informationen des Quellcodes bei und erleichtern die „progressive Reduktion“, wodurch eine Optimierung auf mehreren Abstraktionsebenen ermöglicht wird.
3.1 Quellcode-Mapping
CIR ist teilweise von LLVMs IR inspiriert. In LLVM wird eine Struktur verwendet, die der Form der Single Static Allocation (SSA) ähnelt und an einem Ort zugewiesene Werte und Variablen unterscheidet, die konzeptionell Speicherorten ähneln. Die Kompilierung verläuft zunächst linear, wobei der Quellcode vorhanden ist wird in einen abstrakten Syntaxbaum analysiert, an dem eine Typprüfung durchgeführt wird, um Zwischenausdrücke zu generieren. Im Gegensatz zu anderen Kompilierungsframeworks ist Codon jedoch bidirektional und die IR-Optimierung kann zur Typprüfungsphase zurückkehren, um neue Knoten zu generieren, die nicht im ursprünglichen Programm enthalten waren. Das Framework ist „domänenerweiterbar“ und ein „DSL-Plug-in“ besteht aus Bibliotheksmodulen, Syntax und domänenspezifischen Optimierungen.
Um eine Abbildung der Quellcodestruktur zu erreichen, kann ein Wert in einen beliebig großen Baum verschachtelt werden. Durch diese Struktur lässt sich ein CIR beispielsweise leicht auf einen Kontrollflussgraphen reduzieren. Im Gegensatz zu LLVM verwendete CIR jedoch ursprünglich explizite Knoten, sogenannte Streams, um den Kontrollfluss darzustellen, was eine enge strukturelle Übereinstimmung mit dem Quellcode ermöglichte. Die explizite Darstellung der Kontrollflusshierarchie ähnelt dem Ansatz von Taichi. Wichtig ist, dass dadurch Optimierungen und Transformationen, die auf präzisen Konzepten des Kontrollflusses basieren, einfacher zu implementieren sind. Ein einfaches Beispiel sind Streams, die explizite Schleifen in CIR beibehalten und es dem Codon ermöglichen, häufige Muster von Schleifen leicht zu identifizieren, anstatt wie bei LLVM IR ein Labyrinth von Zweigen zu entschlüsseln.
3.2 Operatoren
CIR stellt Operatoren wie „+“ nicht explizit dar, sondern wandelt sie in entsprechende Funktionsaufrufe um. Dies ermöglicht eine nahtlose Operatorüberladung beliebiger Typen mit derselben Semantik wie bei Python. Der +-Operator wird beispielsweise in einen Add-Aufruf aufgelöst.
Eine natürliche Frage, die sich aus diesem Ansatz ergibt, ist, wie Operatoren für primitive Typen wie Ints und Floats implementiert werden. Codon löst dieses Problem, indem es Inline-LLVM-IR über @llvm-Funktionsanmerkungen ermöglicht, wodurch alle primitiven Operatoren in Codon-Quellcode geschrieben werden können. Informationen zu Operatoreigenschaften wie Kommutativität und Assoziativität können als Anmerkungen in IR übergeben werden.
3.3 Bidirektionale IR
Die traditionelle Kompilierungspipeline ist in ihrem Datenfluss linear: Quellcode wird in AST geparst, normalerweise in IR umgewandelt, optimiert und schließlich in Maschinencode umgewandelt. Codon führte das Konzept der bidirektionalen IR ein, bei dem der IR-Kanal zur Typprüfungsphase zurückkehren kann und neue IR-Knoten und spezialisierte Knoten generiert, die im Quellprogramm nicht vorhanden sind. Zu seinen Vorteilen gehören:
- Die komplexesten Umwandlungen können direkt im Codon durchgeführt werden. Beispielsweise umfasst die Prefetch-Optimierung einen allgemeinen dynamischen Programmplaner, dessen reine Implementierung in Codon IR unrealistisch ist.
- Neue Instanziierungen benutzerdefinierter Datentypen können bei Bedarf generiert werden. Beispielsweise können Optimierungen, die die Verwendung von Codon-Wörterbüchern erfordern, als Dict-Typen für die entsprechenden Schlüssel- und Werttypen instanziiert werden. Das Instanziieren eines Typs oder einer Funktion ist ein sehr einfacher Vorgang, der aufgrund der kaskadierenden Implementierung und Spezialisierung einen vollständigen erneuten Aufruf des Typprüfers erfordert.
Ähnlich kann der IR-Kanal selbst generisch sein und das Expressionstypsystem von Codon verwenden, um mit verschiedenen Typen zu arbeiten. IR-Typen haben keine zugehörigen Generika (im Gegensatz zu AST-Typen). Allerdings trägt jeder CIR-Typ einen Verweis auf den AST-Typ, der zu seiner Generierung verwendet wurde, sowie auf alle generischen AST-Typparameter. Diese zugeordneten AST-Typen werden beim erneuten Aufrufen des Typprüfers verwendet und ermöglichen die Abfrage von CIR-Typen auf ihre zugrunde liegenden Generika. Beachten Sie, dass CIR-Typen High-Level-Abstraktionen entsprechen; LLVM-IR-Typen sind niedriger und lassen sich nicht direkt auf Codon-Typen abbilden.
Tatsächlich ist die Fähigkeit, neue Typen während der CIR-Bereitstellung zu instanziieren, für viele CIR-Vorgänge von entscheidender Bedeutung. Um beispielsweise ein Tupel (x,y) aus den gegebenen CIR-Werten x und y zu erstellen, muss ein neuer Tupeltyp tuple[X,Y] instanziiert werden (wobei der Großbuchstabenbezeichner der Ausdruckstyp ist), was wiederum die Instanziierung eines neuen Tupels erfordert Tupeloperatoren für Gleichheits- und Ungleichheitsprüfung, Iteration, Hashing und mehr. Durch den Rückruf des Typprüfers wird dies jedoch zu einem nahtlosen Prozess.

Das obige Bild ist ein Beispiel für eine einfache Zuordnung von Fibonacci-Funktion zu CIR-Quellcode. Die Funktion fib wird einem CIR BodiedFunc mit einem einzelnen Ganzzahlargument zugeordnet. Der Körper enthält einen If-Kontrollfluss, der eine Konstante zurückgibt oder die Funktion rekursiv aufruft, um das Ergebnis zu erhalten. Beachten Sie, dass Operatoren wie + in Funktionsaufrufe übersetzt werden (z. B. add), IR jedoch in seiner Struktur dem rohen Quellcode zugeordnet wird, was einen einfachen Mustervergleich und eine einfache Konvertierung ermöglicht. Überladen Sie in diesem Fall einfach den Call-Handler, prüfen Sie, ob die Funktion die Bedingungen für die Ersetzung erfüllt, und führen Sie die Aktion aus, wenn sie zutrifft. Benutzer können auch ihr eigenes Durchlaufschema definieren und die IR-Struktur nach Belieben ändern.
3.4 Kanäle und Transformationen
CIR bietet eine umfassende Analyse- und Transformationsinfrastruktur: Benutzer schreiben Pässe mithilfe verschiedener in CIR integrierter Anwendungsklassen und registrieren sie beim Passwort-Manager, wo komplexere Kanäle die Bidirektionalität von CIR nutzen und den Typ erneut aufrufen können Checker, um neue CIR-Typen, -Funktionen und -Methoden zu erhalten. Beispiele dafür sind in der folgenden Abbildung dargestellt.
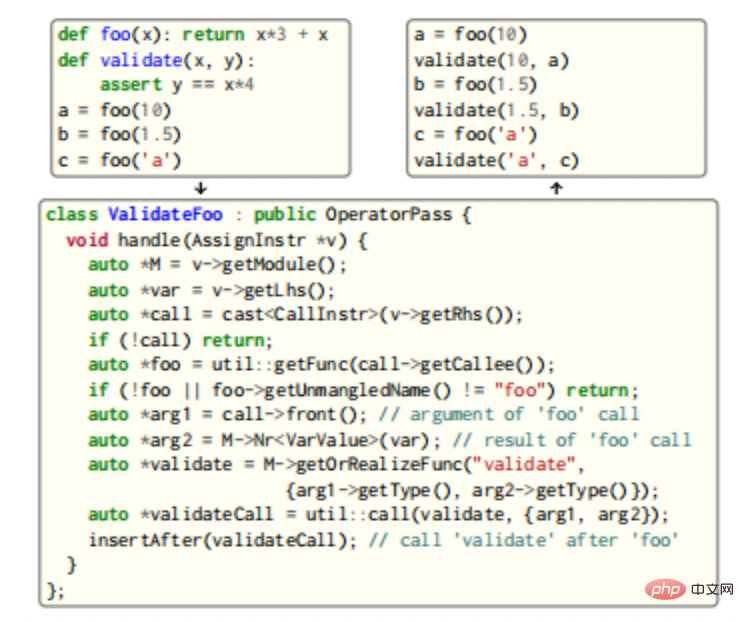
In diesem Beispiel werden Aufrufe der Funktion foo gesucht und nach jedem Aufruf wird ein Aufruf eingefügt, der die Parameter von foo und seine Ausgabe validiert. Da beide Funktionen generisch sind, wird der Typprüfer erneut aufgerufen, um drei neue, eindeutige Validierungsinstanziierungen zu generieren. Das Instanziieren neuer Typen und Funktionen erfordert die Handhabung möglicher Spezialisierungen und die Implementierung zusätzlicher Knoten (z. B. muss im Beispiel die ==-Operatormethode __eq__ implementiert werden, um die Validierung zu implementieren) sowie das Zwischenspeichern der Implementierung für die spätere Verwendung.
3.5 Codegenerierung und -ausführung
Codon verwendet LLVM, um nativen Code zu generieren. Die Umwandlung von Codon IR in LLVM IR ist normalerweise ein einfacher Prozess. Die meisten Codon-Typen können auch intuitiv in LLVM-IR-Typen konvertiert werden: int wird zu i64, float wird zu double, bool wird zu int8 usw. – diese Konvertierungen ermöglichen auch C/C++-Interoperabilität. Tupeltypen werden in Strukturtypen konvertiert, die die entsprechenden Elementtypen enthalten, die als Wert übergeben werden (beachten Sie, dass Tupel in Python unveränderlich sind). Diese Art der Handhabung von Tupeln ermöglicht in den meisten Fällen eine vollständige Optimierung von LLVM. Referenztypen wie Listen, Dict usw. werden als dynamisch zugewiesene Objekte implementiert und als Referenz übergeben. Diese folgen den variablen semantischen Typen und können bei Bedarf auf optionale Typen aktualisiert werden, um keine Werte zu verarbeiten ein Tupel aus dem i1-Typ von LLVM und dem zugrunde liegenden Typ, wobei ersterer angibt, ob der optionale Typ einen Wert enthält. Optionen für Referenztypen sind speziell dafür konzipiert, einen Nullzeiger zu verwenden, um fehlende Werte anzuzeigen.
Generatoren sind ein beliebtes Sprachkonstrukt in Python; tatsächlich iteriert jede for-Schleife über einen Generator. Wichtig ist, dass Generatoren in Codon keinen zusätzlichen Overhead verursachen und wann immer möglich mit entsprechendem Standard-C-Code kompiliert werden. Zu diesem Zweck nutzt Codon LLVM-Coroutinen zur Implementierung von Generatoren.
Codon verwendet beim Ausführen von Code eine kleine Laufzeitbibliothek. Insbesondere wird der Boehm-Garbage Collector zur Verwaltung des zugewiesenen Speichers verwendet. Codon bietet zwei Kompilierungsmodi: Debug und Release. Der Debug-Modus umfasst vollständige Debug-Informationen, sodass das Programm mit Tools wie GDB und LLDB debuggt werden kann, sowie vollständige Traceback-Informationen, einschließlich Dateiname und Zeilennummer. Der Release-Modus führt mehr Optimierungen durch (einschließlich -O3-Optimierungen von GCC/Clang) und lässt einige Sicherheits- und Debugging-Informationen aus. Daher können Benutzer den Debug-Modus für schnelle Programmier- und Debugging-Zyklen und den Release-Modus für eine leistungsstarke Bereitstellung verwenden.
3.6 Skalierbarkeit
Aufgrund der Flexibilität und bidirektionalen IR des Frameworks und der allgemeinen Ausdruckskraft der Python-Syntax implementieren Codon-Anwendungen typischerweise die meisten Funktionen domänenspezifischer Komponenten im Quellcode selbst. Ein modularer Ansatz kann als dynamische Bibliotheken und Codon-Quelldateien gepackt werden. Dieses Plugin kann vom Codon-Compiler zur Kompilierungszeit geladen werden.
Einige Frameworks, wie z. B. MLIR, ermöglichen eine individuelle Anpassung. Condon IR hingegen schränkt einige Knotentypen ein und setzt für mehr Flexibilität auf Bidirektionalität. CIR ermöglicht es Benutzern insbesondere, von „benutzerdefinierten“ Typen, Streams, Konstanten und Anweisungen abzuleiten, die über deklarative Schnittstellen mit dem Rest des Frameworks interagieren. Benutzerdefinierte Knoten stammen beispielsweise aus der entsprechenden benutzerdefinierten Basisklasse (benutzerdefinierter Typ, benutzerdefinierter Stream usw.) und stellen einen „Builder“ zur Verfügung, um die entsprechende LLVM-IR zu erstellen. Die Implementierung benutzerdefinierter Typen und Knoten umfasst die Definition eines Generators (z. B. Gebäudetyp) über eine virtuelle Methode. Die benutzerdefinierte Typklasse selbst definiert eine Methode getBuilder, um eine Instanz dieses Generators zu erhalten. Dieser standardisierte Aufbau von Knoten funktioniert nahtlos mit bestehenden Kanälen und Analysen.
4 Anwendungen
4.1 Benchmark-Leistung
Viele Standard-Python-Programme funktionieren bereits sofort, sodass mehrere gängige Muster im Python-Code problemlos optimiert werden können, z two ) oder zusammenhängende Zeichenfolgenzusätze (können in einer einzigen Verbindung zusammengefasst werden, um den Zuordnungsaufwand zu reduzieren).

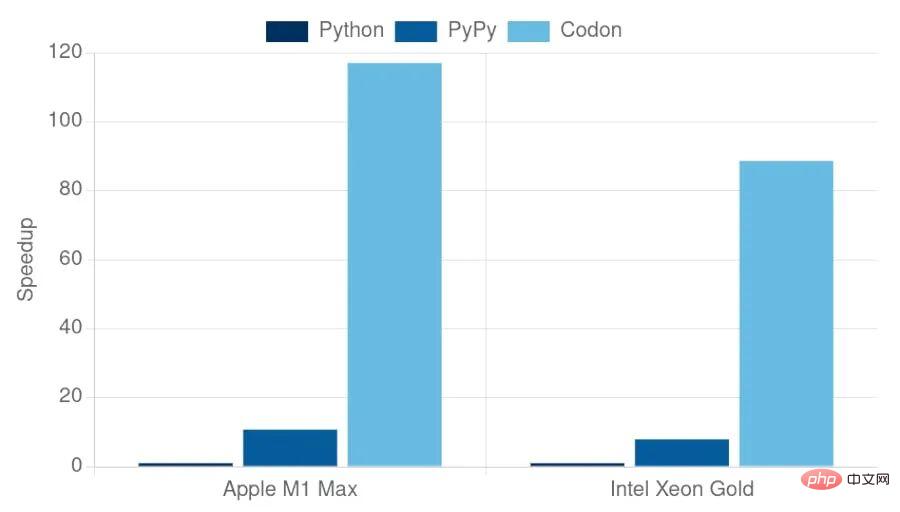
Die obige Grafik zeigt die Laufzeitleistung von Codon zusammen mit der Leistung von CPython (v3.10) und PyPy (v7.3) bei Benchmarks, beschränkt auf eine Reihe von „Kern“-Benchmarks, nicht abhängig von Externe Bibliotheken. Im Vergleich zu CPython und PyPy ist Codon immer schneller, manchmal um eine Größenordnung. Obwohl Benchmarks ein guter Indikator für die Leistung sind, sind sie nicht ohne Nachteile und geben oft nicht die ganze Wahrheit wieder. Mit Codon können Benutzer einfachen Python-Code für eine Vielzahl von Domänen schreiben und gleichzeitig eine hohe Leistung für reale Anwendungen und Datensätze liefern.
4.2 OpenMP: Task- und Schleifenparallelität
Da Codon unabhängig von der vorhandenen Python-Laufzeit erstellt wird, ist es nicht von der CPython-Global-Interpreter-Sperre betroffen und kann daher die Vorteile von Multithreading voll ausnutzen. Um die parallele Programmierung zu unterstützen, ermöglicht eine Erweiterung von Codon Endbenutzern die Verwendung von OpenMP.
Für OpenMP wird der Hauptteil der parallelen Schleife als neue Funktion beschrieben, die dann von mehreren Threads von der OpenMP-Laufzeit aufgerufen wird. Beispielsweise würde der Schleifenkörper in der folgenden Abbildung als Funktion f dargestellt, die als Parameter die Variablen a, b, c und die Schleifenvariable i verwendet.
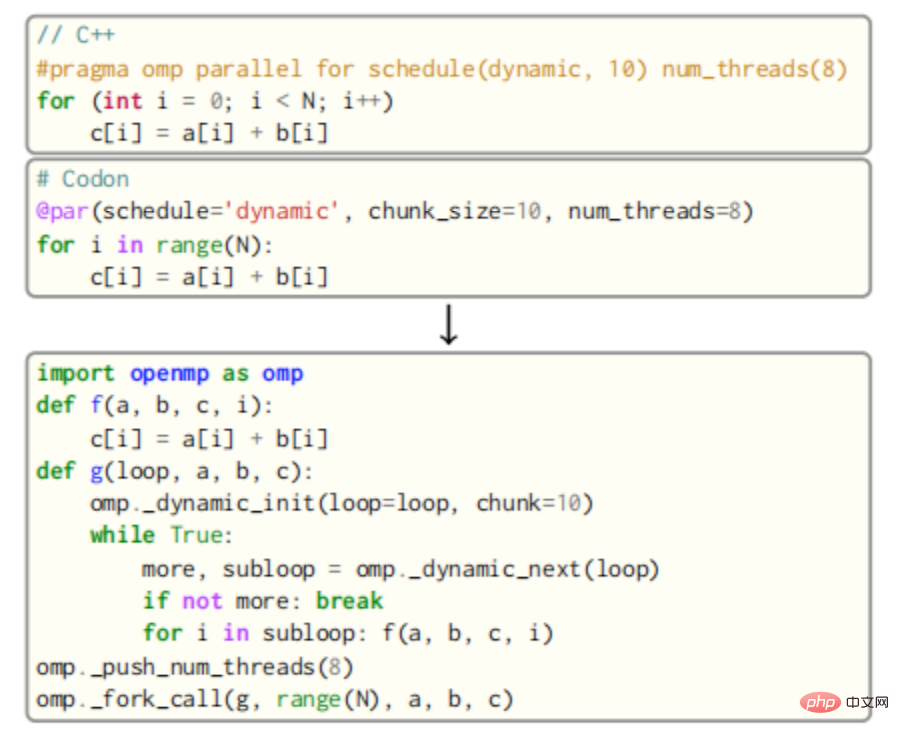
Der Aufruf von f wird dann in eine neue Funktion g eingefügt, die die dynamische Round-Robin-Planungsroutine von OpenMP mit einer Blockgröße von 10 aufruft. Schließlich rufen alle Threads in der Warteschlange g über die Funktion fork_call von OpenMP auf. Das Ergebnis wird im korrekten Codeausschnitt im Bild oben angezeigt, wobei besonderes Augenmerk auf den Umgang mit privaten Variablen sowie gemeinsam genutzten Variablen gelegt wird. Die Reduzierung von Variablen erfordert außerdem eine zusätzliche Codegenerierung für atomare Operationen (oder die Verwendung von Sperren) und eine zusätzliche Ebene von OpenMP-API-Aufrufen.
Codons bidirektionale Kompilierung ist eine Schlüsselkomponente des OpenMP-Passes. Die „Vorlagen“ für verschiedene Schleifen sind im Codon-Quellcode implementiert. Nach der Codeanalyse werden diese „Vorlagen“ weitergegeben und durch das Ausfüllen von Schleifenkörpern, Blockgrößen und Zeitplänen, das Umschreiben von Ausdrücken, die von gemeinsam genutzten Variablen abhängen, usw. spezialisiert. Dieses Design vereinfacht die Implementierung des Passes erheblich und erhöht die Vielseitigkeit.
Im Gegensatz zu Clang oder GCC kann der OpenMP-Kanal von Codon ableiten, welche Variablen gemeinsam genutzt werden und welche privat sind, sowie jeglichen minimierten Code, der stattfindet. Benutzerdefinierte Reduzierungen können einfach durch Bereitstellung einer geeigneten atomaren magischen Methode (z. B. .aborom_add) für den Reduzierungstyp vorgenommen werden. Codon iteriert durch den Generator (das Standardverhalten von Python-Schleifen) zu einer „imperativen Schleife“, d. h. einer Schleife im C-Stil mit Start-, Stopp- und Schrittwerten. Wenn das @par-Tag vorhanden ist, wird die erzwungene Schleife in eine OpenMP-Parallelschleife umgewandelt. Nicht erzwungene parallele Schleifen werden parallelisiert, indem für jede Schleifeniteration eine neue OpenMP-Aufgabe erzeugt und nach der Schleife ein Synchronisationspunkt platziert wird. Dieses Schema ermöglicht die Parallelisierung aller Python-For-Schleifen.
OpenMP-Transformationen werden als Satz von CIRs implementiert, die mit for-Schleifen übereinstimmen, die mit dem @par-Attribut markiert sind, und diese Schleifen werden in die entsprechenden OpenMP-Konstrukte im CIR umgewandelt. Fast alle OpenMP-Strukturen sind als Funktionen höherer Ordnung von Condon selbst implementiert.
4.3 CoLa: Ein DSL für blockbasierte Komprimierung
CoLa ist ein Codon-basiertes DSL, das auf blockbasierte Datenkomprimierung abzielt, die den Kern vieler heute verwendeter gängiger Bild- und Videokomprimierungsalgorithmen darstellt. Diese Arten der Komprimierung basieren stark auf der Aufteilung eines Pixelbereichs in eine Reihe immer kleinerer Blöcke, wodurch eine mehrdimensionale Datenhierarchie entsteht, in der jeder Block seine Position relativ zu anderen Blöcken kennen muss. Beispielsweise unterteilt die H.264-Videokomprimierung den Eingaberahmen in eine Reihe von 16x16-Pixel-Blöcken, jedes Pixel in 8x8-Pixel-Blöcke, und teilt diese Pixel dann in 4x4-Pixel-Blöcke auf. Die Verfolgung der Position zwischen diesen einzelnen Pixelfeldern erfordert eine große Menge an Informationsdaten, wodurch die zugrunde liegenden Algorithmen in bestehenden Implementierungen schnell verdeckt werden.
CoLa führt die Abstraktion Hierarchical Multidimensional Array (HMDA) ein, die den Ausdruck und die Verwendung hierarchischer Daten vereinfacht. HMDA stellt ein mehrdimensionales Array mit einer Positionsangabe dar, das den Ursprung eines beliebigen HMDA relativ zu einem globalen Koordinatensystem verfolgt. HMDA kann auch ihre Größe und Schrittlänge verfolgen. Mit diesen drei Datenelementen kann jeder HMDA an jedem Punkt im Programm seine Position relativ zu jedem anderen HMDA bestimmen. CoLa abstrahiert HMDA in Codon als eine Bibliothek, die sich auf zwei neue Datentypen konzentriert: Blöcke und Ansichten. Der Block erstellt und besitzt ein zugrunde liegendes mehrdimensionales Array, und die Ansicht zeigt auf einen bestimmten Bereich des Blocks. CoLa stellt zwei Haupthierarchien zur Verfügung: Konstruktionsvorgänge, Positionskopie und Partitionierung, die jeweils Blöcke und Ansichten erstellen. CoLa unterstützt die Standardindizierung mithilfe von Ganzzahl- und Slice-Indizes, führt aber auch zwei einzigartige Indizierungsschemata ein, die nachahmen, wie Komprimierungsstandards den Datenzugriff beschreiben. „Out-of-bounds“-Indizes ermöglichen Benutzern den Zugriff auf Daten rund um eine Ansicht, während „verwaltete“ Indizes es Benutzern ermöglichen, einen HMDA mithilfe eines anderen HMDA zu indizieren.
Während die Kombination aus Codons Physik und CoLas Abstraktionen Benutzern die Vorteile von Hochsprache und kompressionsspezifischen Abstraktionen bietet, führt die HMDA-Abstraktion aufgrund der zusätzlich erforderlichen Indizierungsvorgänge zu einem erheblichen Laufzeitaufwand. Bei der Komprimierung erfolgen viele HMDA-Zugriffe auf der innersten Berechnungsebene, sodass sich jede zusätzliche Berechnung zusätzlich zum Zugriff auf das ursprüngliche Array als nachteilig für die Laufzeit erweist. CoLa nutzt das Codon-Framework zur Implementierung von Hierarchien und reduziert so die Anzahl der erstellten Zwischenansichten und Ausbreitungsversuche, um auf die Position eines bestimmten HMDA zu schließen. Dadurch wird die Gesamtgröße der Hierarchie reduziert und die eigentlichen Indexberechnungen vereinfacht. Ohne diese Optimierungen ist CoLa im Durchschnitt 48,8×, 6,7× und 20,5× langsamer als der Referenz-C-Code für JPEG und H.264. Nach der Optimierung wurde die Leistung erheblich verbessert, mit durchschnittlichen Laufzeiten von jeweils 1,06×, 0,67× und 0,91× im Vergleich zum gleichen Referenzcode.
CoLa ist als Codon-Plugin implementiert und verfügt daher über eine Bibliothek von Komprimierungsprimitiven sowie eine Reihe von CIR- und LLVM-Kanälen, die Erstellungs- und Zugriffsroutinen optimieren. CoLa vereinfacht außerdem gängige Indizierungs- und Reduktionsvorgänge mithilfe der benutzerdefinierten Datenstrukturzugriffssyntax und der von Codon bereitgestellten Operatoren.
5. Zusammenfassung
Im Wesentlichen ist Codon ein domänenkonfigurierbares Framework zum Entwerfen und schnellen Implementieren von DSL. Durch die Anwendung eines speziellen Typprüfungsalgorithmus und eines neuen bidirektionalen IR-Algorithmus kann dynamischer Code in verschiedenen Bereichen einfach optimiert werden. Im Vergleich zur direkten Verwendung von Python kann Codon mit der Leistung von C/C++ mithalten, ohne auf hohe Einfachheit zu verzichten.
Derzeit verfügt Codon über mehrere Python-Funktionen, die nicht unterstützt werden, darunter hauptsächlich Laufzeitpolymorphismus, Laufzeitreflexion und Typoperationen (z. B. dynamische Änderung der Methodentabelle, dynamisches Hinzufügen von Klassenmitgliedern, Metaklassen und Klassendekoratoren). Es gibt auch Lücken in Standardabdeckung der Python-Bibliothek. Obwohl Codon kompiliertes Python als restriktive Lösung existieren kann, ist es sehr beachtenswert.
【Referenzmaterialien und zugehörige Lektüre】
- https://www.php.cn/link/a7453a5f026fb6831d68bdc9cb0edcae
- https:/ /www.php.cn/link/c49e446a46fa27a6e18ffb6119461c3f
- PyPy's Tracing JIT Compiler, https://doi.org/10.1145/1565824.1565827#🎜 🎜# A Typ -basiertes mehrstufiges Programmier-Framework für die Codegenerierung in C++, https://doi.org/10.1109/CGO51591. 2021.9370333
-
- https://www.php.cn/link/9fd5e502c1640f62738c8a908d3eb0f7 LLVM: a Zusammenstellungsrahmen für ein lebenslanges Programm Analysetransformation,https://doi.org/10.1109/CGO.2004.1281665
- AnyDSL: A Partial Evaluation Framework for Programming High-Performance Libraries,https://doi.org/10.1145/3276489#🎜 🎜#
- Eine Python-basierte Programmiersprache für leistungsstarke Computational Genomics , https: //doi.org/10.1038/s41587-021-00985-6
- Ein Compiler für hohe Leistung Pythonische Anwendungen und DSLs, https://dl.acm.org/doi/abs/10.1145/3578360.3580275
- https://www.php.cn/link/6c7de1f27f7de61a6daddfffbe05c058
- Taichi: Eine Sprache für Hochleistungsberechnungen auf räumlich spärlichen Datenstrukturen,https://doi.org/10.1145/3355089. 335650
- https://www.php.cn/link/ca5150ff1c65880ded50f92ed067c95e
- 操作系统中的系统抽象#🎜 🎜# 温故知新:从计算机体系结构看操作系统
- 从操作系统看Docker
- # 🎜🎜#感知人工智能操作系统
- 嵌入式Linux的网络连接管理
- Linux 内核裁剪框架初探
- 机器学习系统架构的10个要素
Das obige ist der detaillierte Inhalt vonPython-Leistungsoptimierung aus Compiler-Perspektive. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!