
Heim >Backend-Entwicklung >Python-Tutorial >Zehn alternative Datenverarbeitungstechniken für Pandas
Zehn alternative Datenverarbeitungstechniken für Pandas

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-15 09:19:022498Durchsuche
Die in diesem Artikel zusammengestellten Techniken unterscheiden sich von den allgemeinen Techniken, die zuvor in 10 Pandas zusammengestellt wurden. Sie werden es vielleicht nicht oft verwenden, aber manchmal, wenn Sie auf einige sehr schwierige Probleme stoßen, können diese Techniken Ihnen helfen, diese schnell zu lösen.

1. Kategorischer Typ
Standardmäßig wird Spalten mit einer begrenzten Anzahl von Optionen der Objekttyp zugewiesen. Aber im Hinblick auf den Speicher ist es keine effiziente Wahl. Wir können diese Spalten indizieren und nur Verweise auf die Objekte und nicht die tatsächlichen Werte verwenden. Pandas bietet einen Dtype namens Categorical, um dieses Problem zu lösen.
Zum Beispiel besteht es aus einem großen Datensatz mit Bildpfaden. Jede Zeile hat drei Spalten: Anker, positiv und negativ.
Wenn Sie Categorical für kategoriale Spalten verwenden, können Sie den Speicherverbrauch erheblich reduzieren.
# raw data +----------+------------------------+ |class |filename| +----------+------------------------+ | Bathroom | Bathroombath_1.jpg| | Bathroom | Bathroombath_100.jpg| | Bathroom | Bathroombath_1003.jpg | | Bathroom | Bathroombath_1004.jpg | | Bathroom | Bathroombath_1005.jpg | +----------+------------------------+ # target +------------------------+------------------------+----------------------------+ | anchor |positive|negative| +------------------------+------------------------+----------------------------+ | Bathroombath_1.jpg| Bathroombath_100.jpg| Dinningdin_540.jpg| | Bathroombath_100.jpg| Bathroombath_1003.jpg | Dinningdin_1593.jpg | | Bathroombath_1003.jpg | Bathroombath_1004.jpg | Bedroombed_329.jpg| | Bathroombath_1004.jpg | Bathroombath_1005.jpg | Livingroomliving_1030.jpg | | Bathroombath_1005.jpg | Bathroombath_1007.jpg | Bedroombed_1240.jpg | +------------------------+------------------------+----------------------------+
Der Wert der Dateinamenspalte wird häufig kopiert. Daher kann die Speichernutzung durch die Verwendung von Categorical erheblich reduziert werden.
Lassen Sie uns den Zieldatensatz lesen und den Unterschied im Speicher sehen:
triplets.info(memory_usage="deep") # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 anchor 525000 non-null category # 1 positive 525000 non-null category # 2 negative 525000 non-null category # dtypes: category(3) # memory usage: 4.6 MB # without categories triplets_raw.info(memory_usage="deep") # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 anchor 525000 non-null object # 1 positive 525000 non-null object # 2 negative 525000 non-null object # dtypes: object(3) # memory usage: 118.1 MB
Der Unterschied ist sehr groß und wächst nichtlinear mit zunehmender Anzahl von Wiederholungen.
2. Zeilen-Spalten-Konvertierung
Manchmal stoßen wir auch auf das Problem der Zeilen-Spalten-Konvertierung. Werfen wir einen Blick auf den Datensatz der Kaggle-Konkurrenz. census_start .csv-Datei:
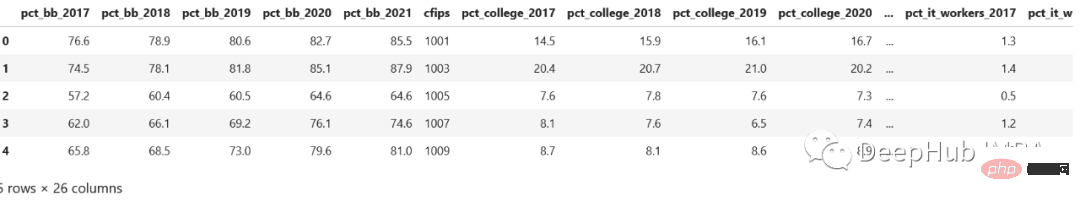
Wie Sie sehen, werden diese nach Jahr gespeichert. Es wäre viel besser, wenn es eine Spalte „year“ und „pct_bb“ gäbe und jede Zeile entsprechende Werte hätte, richtig.
cols = sorted([col for col in original_df.columns
if col.startswith("pct_bb")])
df = original_df[(["cfips"] + cols)]
df = df.melt(id_vars="cfips",
value_vars=cols,
var_name="year",
value_name="feature").sort_values(by=["cfips", "year"])Sehen Sie sich das Ergebnis an, ist es so viel besser:

3. apply() ist sehr langsam
Wir haben es letztes Mal eingeführt, es ist am besten, diese Methode nicht zu verwenden, da sie durchläuft jede Zeile und rufen Sie die angegebene Methode auf. Aber wenn wir keine andere Wahl haben, gibt es dann eine Möglichkeit, die Geschwindigkeit zu erhöhen?
Sie können Pakete wie Swifter oder Pandarallew verwenden, um den Prozess zu parallelisieren.
Swifter
import pandas as pd import swifter def target_function(row): return row * 10 def traditional_way(data): data['out'] = data['in'].apply(target_function) def swifter_way(data): data['out'] = data['in'].swifter.apply(target_function)
Pandaralllel
import pandas as pd from pandarallel import pandarallel def target_function(row): return row * 10 def traditional_way(data): data['out'] = data['in'].apply(target_function) def pandarallel_way(data): pandarallel.initialize() data['out'] = data['in'].parallel_apply(target_function)
Durch Multithreading kann die Berechnungsgeschwindigkeit verbessert werden. Wenn ein Cluster vorhanden ist, ist es natürlich am besten, dask oder pyspark zu verwenden. 4. Nullwert, int, Int64
Standard-Ganzzahldaten Der Typ unterstützt keine Nullwerte und wird daher automatisch in eine Gleitkommazahl konvertiert. Wenn Ihre Daten also Nullwerte in ganzzahligen Feldern erfordern, sollten Sie die Verwendung des Datentyps Int64 in Betracht ziehen, da dieser pandas.NA zur Darstellung von Nullwerten verwendet.
5. CSV, Kompression oder Parkett?
Wählen Sie möglichst Parkett. Parquet behält den Datentyp bei, sodass beim Lesen von Daten keine Dtypes angegeben werden müssen. Parquet-Dateien werden standardmäßig mit Snappy komprimiert, sodass sie nur wenig Speicherplatz beanspruchen. Unten sehen Sie ein paar Vergleiche
|file|size | +------------------------+---------+ | triplets_525k.csv| 38.4 MB | | triplets_525k.csv.gzip |4.3 MB | | triplets_525k.csv.zip|4.5 MB | | triplets_525k.parquet|1.9 MB | +------------------------+---------+
Für das Lesen von Parkett sind zusätzliche Pakete erforderlich, z. B. Pyarrow oder Fastparquet. chatgpt sagte, dass pyarrow schneller als fastparquet ist, aber als ich es an einem kleinen Datensatz getestet habe, war fastparquet schneller als pyarrow, es wird jedoch empfohlen, hier pyarrow zu verwenden, da Pandas 2.0 dies ebenfalls standardmäßig verwendet.
6, value_counts ()
Das Berechnen relativer Häufigkeiten, einschließlich der Ermittlung des Absolutwerts, des Zählens und Dividierens durch die Summe, ist komplex, aber mit value_counts lässt sich diese Aufgabe einfacher erledigen, und die Methode bietet die Möglichkeit, Ein- oder Ausschlüsse vorzunehmen Nullwertoptionen.
df = pd.DataFrame({"a": [1, 2, None], "b": [4., 5.1, 14.02]})
df["a"] = df["a"].astype("Int64")
print(df.info())
print(df["a"].value_counts(normalize=True, dropna=False),
df["a"].value_counts(normalize=True, dropna=True), sep="nn")

7. Modin
Hinweis: Modin befindet sich noch in der Testphase.
pandas ist Single-Threaded, aber Modin kann Ihren Arbeitsablauf beschleunigen, indem es Pandas skaliert, und es funktioniert besonders gut bei größeren Datensätzen, bei denen Pandas sehr langsam oder speicherintensiv werden können, was zu OOM führt.
!pip install modin[all]
import modin.pandas as pd
df = pd.read_csv("my_dataset.csv")Das Folgende ist das Architekturdiagramm der offiziellen Website von Modin, wenn Sie daran interessiert sind, es zu studieren:

Wenn Sie häufig auf komplexe halbstrukturierte Daten stoßen und diese trennen müssen Wenn Sie es einzeln in die Spalte einfügen, können Sie diese Methode verwenden:
import pandas as pd
regex = (r'(?P<title>[A-Za-z's]+),'
r'(?P<author>[A-Za-zs']+),'
r'(?P<isbn>[d-]+),'
r'(?P<year>d{4}),'
r'(?P<publisher>.+)')
addr = pd.Series([
"The Lost City of Amara,Olivia Garcia,978-1-234567-89-0,2023,HarperCollins",
"The Alchemist's Daughter,Maxwell Greene,978-0-987654-32-1,2022,Penguin Random House",
"The Last Voyage of the HMS Endeavour,Jessica Kim,978-5-432109-87-6,2021,Simon & Schuster",
"The Ghosts of Summer House,Isabella Lee,978-3-456789-12-3,2000,Macmillan Publishers",
"The Secret of the Blackthorn Manor,Emma Chen,978-9-876543-21-0,2023,Random House Children's Books"
])
addr.str.extract(regex)

9、读写剪贴板
这个技巧有人一次也用不到,但是有人可能就是需要,比如:在分析中包含PDF文件中的表格时。通常的方法是复制数据,粘贴到Excel中,导出到csv文件中,然后导入Pandas。但是,这里有一个更简单的解决方案:pd.read_clipboard()。我们所需要做的就是复制所需的数据并执行一个方法。
有读就可以写,所以还可以使用to_clipboard()方法导出到剪贴板。
但是要记住,这里的剪贴板是你运行python/jupyter主机的剪切板,并不可能跨主机粘贴,一定不要搞混了。
10、数组列分成多列
假设我们有这样一个数据集,这是一个相当典型的情况:
import pandas as pd
df = pd.DataFrame({"a": [1, 2, 3],
"b": [4, 5, 6],
"category": [["foo", "bar"], ["foo"], ["qux"]]})
# let's increase the number of rows in a dataframe
df = pd.concat([df]*10000, ignore_index=True)

我们想将category分成多列显示,例如下面的

先看看最慢的apply:
def dummies_series_apply(df):
return df.join(df['category'].apply(pd.Series)
.stack()
.str.get_dummies()
.groupby(level=0)
.sum())
.drop("category", axis=1)
%timeit dummies_series_apply(df.copy())
#5.96 s ± 66.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)sklearn的MultiLabelBinarizer
from sklearn.preprocessing import MultiLabelBinarizer
def sklearn_mlb(df):
mlb = MultiLabelBinarizer()
return df.join(pd.DataFrame(mlb.fit_transform(df['category']), columns=mlb.classes_))
.drop("category", axis=1)
%timeit sklearn_mlb(df.copy())
#35.1 ms ± 1.31 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)是不是快了很多,我们还可以使用一般的向量化操作对其求和:
def dummies_vectorized(df):
return pd.get_dummies(df.explode("category"), prefix="cat")
.groupby(["a", "b"])
.sum()
.reset_index()
%timeit dummies_vectorized(df.copy())
#29.3 ms ± 1.22 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)

使用第一个方法(在StackOverflow上的回答中非常常见)会给出一个非常慢的结果。而其他两个优化的方法的时间是非常快速的。
总结
我希望每个人都能从这些技巧中学到一些新的东西。重要的是要记住尽可能使用向量化操作而不是apply()。此外,除了csv之外,还有其他有趣的存储数据集的方法。不要忘记使用分类数据类型,它可以节省大量内存。感谢阅读!
Das obige ist der detaillierte Inhalt vonZehn alternative Datenverarbeitungstechniken für Pandas. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!