
 Backend-EntwicklungPython-TutorialVollständige Codedemonstration der Dokumentenanalyse mit Python und OCR (Code im Anhang)
Backend-EntwicklungPython-TutorialVollständige Codedemonstration der Dokumentenanalyse mit Python und OCR (Code im Anhang)Vollständige Codedemonstration der Dokumentenanalyse mit Python und OCR (Code im Anhang)


Beim Parsen von Dokumenten werden Daten in Dokumenten untersucht und nützliche Informationen extrahiert. Durch die Automatisierung kann eine Menge manueller Arbeit reduziert werden. Eine beliebte Parsing-Strategie besteht darin, Dokumente in Bilder umzuwandeln und Computer Vision zur Erkennung zu verwenden. Unter Dokumentbildanalyse versteht man die Technologie zur Gewinnung von Informationen aus den Pixeldaten des Bildes eines Dokuments. In manchen Fällen gibt es keine klare Antwort auf die erwarteten Ergebnisse (Text, Bilder, Diagramme, Zahlen, Tabellen, Formeln). ..).

OCR (Optical Character Recognition, optische Zeichenerkennung) ist der Prozess der Erkennung und Extraktion von Text in Bildern durch Computer Vision. Es wurde während des Ersten Weltkriegs erfunden, als der israelische Wissenschaftler Emanuel Goldberg eine Maschine entwickelte, die Zeichen lesen und in Telegraphencodes umwandeln konnte. Mittlerweile hat das Gebiet ein sehr anspruchsvolles Niveau erreicht und vereint Bildverarbeitung, Textlokalisierung, Zeichensegmentierung und Zeichenerkennung. Im Grunde eine Objekterkennungstechnik für Text.
In diesem Artikel werde ich zeigen, wie man OCR zum Parsen von Dokumenten verwendet. Ich zeige einige nützliche Python-Codes, die problemlos in anderen ähnlichen Situationen verwendet werden können (einfach kopieren, einfügen, ausführen), und stelle einen vollständigen Quellcode-Download bereit.
Hier nehmen wir als Beispiel den Jahresabschluss im PDF-Format eines börsennotierten Unternehmens (Link unten).
https://s2.q4cdn.com/470004039/files/doc_financials/2021/q4/_10-K-2021-(As-Filed).pdf

Text in diesem PDF erkennen und extrahieren, Grafiken und Tabellen
Umgebungseinstellungen
Das Ärgerliche an der Dokumentenanalyse ist, dass es so viele Tools für verschiedene Datentypen (Text, Grafiken, Tabellen) gibt und keines davon perfekt funktioniert. Hier sind einige der beliebtesten Methoden und Pakete:
- Verarbeiten Sie Dokumente als Text: Verwenden Sie PyPDF2 zum Extrahieren von Text, verwenden Sie Camelot oder TabulaPy zum Extrahieren von Tabellen und verwenden Sie PyMuPDF zum Extrahieren von Grafiken.
- Dokumente in Bilder konvertieren (OCR): Verwenden Sie pdf2image zur Konvertierung, PyTesseract und viele andere Bibliotheken zum Extrahieren von Daten oder verwenden Sie einfach LayoutParser.
Vielleicht fragen Sie sich: „Warum nicht die PDF-Datei direkt verarbeiten, sondern die Seiten in Bilder konvertieren?“ Der Hauptnachteil dieser Strategie ist das Kodierungsproblem: Dokumente können in mehreren Kodierungen vorliegen (z. B. UTF-8, ASCII, Unicode), sodass die Konvertierung in Text zu Datenverlust führen kann. Um dieses Problem zu vermeiden, verwende ich OCR und konvertiere die Seite mit pdf2image in ein Bild. Beachten Sie, dass die PDF-Rendering-Bibliothek Poppler erforderlich ist.
# with pip pip install python-poppler # with conda conda install -c conda-forge poppler
Sie können die Datei einfach lesen:
# READ AS IMAGE
import pdf2imagedoc = pdf2image.convert_from_path("doc_apple.pdf")
len(doc) #<-- check num pages
doc[0] #<-- visualize a pageGenau wie in unserem Screenshot können Sie den folgenden Code verwenden, wenn Sie das Seitenbild lokal speichern möchten:
# Save imgs import osfolder = "doc" if folder not in os.listdir(): os.makedirs(folder)p = 1 for page in doc: image_name = "page_"+str(p)+".jpg" page.save(os.path.join(folder, image_name), "JPEG") p = p+1
Abschließend müssen wir die CV-Engine einrichten, die wir verwenden werden verwenden. LayoutParser scheint das erste Allzweckpaket für OCR zu sein, das auf Deep Learning basiert. Zur Erfüllung dieser Aufgabe werden zwei bekannte Modelle verwendet:
Erkennung: Facebooks fortschrittlichste Objekterkennungsbibliothek (hier wird die zweite Version Detectron2 verwendet).
pip install layoutparser torchvision && pip install "git+https://github.com/facebookresearch/detectron2.git@v0.5#egg=detectron2"
Tesseract: Das bekannteste OCR-System, 1985 von Hewlett-Packard entwickelt und derzeit von Google entwickelt.
pip install "layoutparser[ocr]"
Jetzt können Sie das OCR-Programm zur Informationserkennung und -extraktion starten.
import layoutparser as lp import cv2 import numpy as np import io import pandas as pd import matplotlib.pyplot as plt
Erkennung
(Ziel-)Erkennung ist der Prozess, Informationselemente in einem Bild zu finden und sie dann mit einem rechteckigen Rahmen zu umgeben. Beim Parsen von Dokumenten handelt es sich bei den Informationen um Titel, Texte, Grafiken, Tabellen ...
Schauen wir uns eine komplexe Seite an, die einige Dinge enthält:
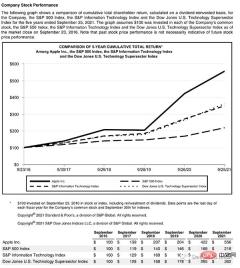
Diese Seite beginnt mit einem Titel und hat einen Textblock. dann ein Diagramm und eine Tabelle, daher benötigen wir ein trainiertes Modell, um diese Objekte zu erkennen. Glücklicherweise ist Detectron dazu in der Lage, wir müssen hier nur ein Modell auswählen und seinen Pfad im Code angeben.
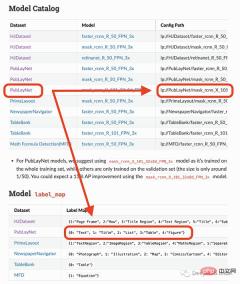
Das Modell, das ich verwenden werde, kann nur 4 Objekte erkennen (Text, Titel, Liste, Tabelle, Grafik). Wenn Sie daher andere Dinge (wie Gleichungen) identifizieren müssen, müssen Sie andere Modelle verwenden.
## load pre-trained model
model = lp.Detectron2LayoutModel(
"lp://PubLayNet/mask_rcnn_X_101_32x8d_FPN_3x/config",
extra_config=["MODEL.ROI_HEADS.SCORE_THRESH_TEST", 0.8],
label_map={0:"Text", 1:"Title", 2:"List", 3:"Table", 4:"Figure"})
## turn img into array
i = 21
img = np.asarray(doc[i])
## predict
detected = model.detect(img)
## plot
lp.draw_box(img, detected, box_width=5, box_alpha=0.2,
show_element_type=True)
结果包含每个检测到的布局的细节,例如边界框的坐标。根据页面上显示的顺序对输出进行排序是很有用的:
## sort
new_detected = detected.sort(key=lambda x: x.coordinates[1])
## assign ids
detected = lp.Layout([block.set(id=idx) for idx,block in
enumerate(new_detected)])## check
for block in detected:
print("---", str(block.id)+":", block.type, "---")
print(block, end='nn')
完成OCR的下一步是正确提取检测到内容中的有用信息。
提取
我们已经对图像完成了分割,然后就需要使用另外一个模型处理分段的图像,并将提取的输出保存到字典中。
由于有不同类型的输出(文本,标题,图形,表格),所以这里准备了一个函数用来显示结果。
'''
{'0-Title': '...',
'1-Text': '...',
'2-Figure': array([[ [0,0,0], ...]]),
'3-Table': pd.DataFrame,
}
'''
def parse_doc(dic):
for k,v in dic.items():
if "Title" in k:
print('x1b[1;31m'+ v +'x1b[0m')
elif "Figure" in k:
plt.figure(figsize=(10,5))
plt.imshow(v)
plt.show()
else:
print(v)
print(" ")首先看看文字:
# load model
model = lp.TesseractAgent(languages='eng')
dic_predicted = {}
for block in [block for block in detected if block.type in ["Title","Text"]]:
## segmentation
segmented = block.pad(left=15, right=15, top=5,
bottom=5).crop_image(img)
## extraction
extracted = model.detect(segmented)
## save
dic_predicted[str(block.id)+"-"+block.type] =
extracted.replace('n',' ').strip()
# check
parse_doc(dic_predicted)
再看看图形报表
for block in [block for block in detected if block.type == "Figure"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## save dic_predicted[str(block.id)+"-"+block.type] = segmented # check parse_doc(dic_predicted)
上面两个看着很不错,那是因为这两种类型相对简单,但是表格就要复杂得多。尤其是我们上看看到的的这个,因为它的行和列都是进行了合并后产生的。
for block in [block for block in detected if block.type == "Table"]: ## segmentation segmented = block.pad(left=15, right=15, top=5, bottom=5).crop_image(img) ## extraction extracted = model.detect(segmented) ## save dic_predicted[str(block.id)+"-"+block.type] = pd.read_csv( io.StringIO(extracted) ) # check parse_doc(dic_predicted)

正如我们的预料提取的表格不是很好。好在Python有专门处理表格的包,我们可以直接处理而不将其转换为图像。这里使用TabulaPy 包:
import tabula
tables = tabula.read_pdf("doc_apple.pdf", pages=i+1)
tables[0]
结果要好一些,但是名称仍然错了,但是效果要比直接OCR好的多。
总结
本文是一个简单教程,演示了如何使用OCR进行文档解析。使用Layoutpars软件包进行了整个检测和提取过程。并展示了如何处理PDF文档中的文本,数字和表格。
Das obige ist der detaillierte Inhalt vonVollständige Codedemonstration der Dokumentenanalyse mit Python und OCR (Code im Anhang). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Python: Automatisierung, Skript- und AufgabenverwaltungApr 16, 2025 am 12:14 AM
Python: Automatisierung, Skript- und AufgabenverwaltungApr 16, 2025 am 12:14 AMPython zeichnet sich in Automatisierung, Skript und Aufgabenverwaltung aus. 1) Automatisierung: Die Sicherungssicherung wird durch Standardbibliotheken wie OS und Shutil realisiert. 2) Skriptschreiben: Verwenden Sie die PSUTIL -Bibliothek, um die Systemressourcen zu überwachen. 3) Aufgabenverwaltung: Verwenden Sie die Zeitplanbibliothek, um Aufgaben zu planen. Die Benutzerfreundlichkeit von Python und die Unterstützung der reichhaltigen Bibliothek machen es zum bevorzugten Werkzeug in diesen Bereichen.
 Python und Zeit: Machen Sie das Beste aus Ihrer StudienzeitApr 14, 2025 am 12:02 AM
Python und Zeit: Machen Sie das Beste aus Ihrer StudienzeitApr 14, 2025 am 12:02 AMUm die Effizienz des Lernens von Python in einer begrenzten Zeit zu maximieren, können Sie Pythons DateTime-, Zeit- und Zeitplanmodule verwenden. 1. Das DateTime -Modul wird verwendet, um die Lernzeit aufzuzeichnen und zu planen. 2. Das Zeitmodul hilft, die Studie zu setzen und Zeit zu ruhen. 3. Das Zeitplanmodul arrangiert automatisch wöchentliche Lernaufgaben.
 Python: Spiele, GUIs und mehrApr 13, 2025 am 12:14 AM
Python: Spiele, GUIs und mehrApr 13, 2025 am 12:14 AMPython zeichnet sich in Gaming und GUI -Entwicklung aus. 1) Spielentwicklung verwendet Pygame, die Zeichnungen, Audio- und andere Funktionen bereitstellt, die für die Erstellung von 2D -Spielen geeignet sind. 2) Die GUI -Entwicklung kann Tkinter oder Pyqt auswählen. Tkinter ist einfach und einfach zu bedienen. PYQT hat reichhaltige Funktionen und ist für die berufliche Entwicklung geeignet.
 Python vs. C: Anwendungen und Anwendungsfälle verglichenApr 12, 2025 am 12:01 AM
Python vs. C: Anwendungen und Anwendungsfälle verglichenApr 12, 2025 am 12:01 AMPython eignet sich für Datenwissenschafts-, Webentwicklungs- und Automatisierungsaufgaben, während C für Systemprogrammierung, Spieleentwicklung und eingebettete Systeme geeignet ist. Python ist bekannt für seine Einfachheit und sein starkes Ökosystem, während C für seine hohen Leistung und die zugrunde liegenden Kontrollfunktionen bekannt ist.
 Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer AnsatzApr 11, 2025 am 12:04 AMSie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AM
Python: Erforschen der primären AnwendungenApr 10, 2025 am 09:41 AMPython wird in den Bereichen Webentwicklung, Datenwissenschaft, maschinelles Lernen, Automatisierung und Skripten häufig verwendet. 1) In der Webentwicklung vereinfachen Django und Flask Frameworks den Entwicklungsprozess. 2) In den Bereichen Datenwissenschaft und maschinelles Lernen bieten Numpy-, Pandas-, Scikit-Learn- und TensorFlow-Bibliotheken eine starke Unterstützung. 3) In Bezug auf Automatisierung und Skript ist Python für Aufgaben wie automatisiertes Test und Systemmanagement geeignet.
 Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PM
Wie viel Python können Sie in 2 Stunden lernen?Apr 09, 2025 pm 04:33 PMSie können die Grundlagen von Python innerhalb von zwei Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master -Steuerungsstrukturen wie wenn Aussagen und Schleifen, 3. Verstehen Sie die Definition und Verwendung von Funktionen. Diese werden Ihnen helfen, einfache Python -Programme zu schreiben.
 Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AM
Wie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer-Anfänger-Programmierbasis in Projekt- und problemorientierten Methoden?Apr 02, 2025 am 07:18 AMWie lehre ich innerhalb von 10 Stunden die Grundlagen für Computer -Anfänger für Programmierungen? Wenn Sie nur 10 Stunden Zeit haben, um Computer -Anfänger zu unterrichten, was Sie mit Programmierkenntnissen unterrichten möchten, was würden Sie dann beibringen ...


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

mPDF
mPDF ist eine PHP-Bibliothek, die PDF-Dateien aus UTF-8-codiertem HTML generieren kann. Der ursprüngliche Autor, Ian Back, hat mPDF geschrieben, um PDF-Dateien „on the fly“ von seiner Website auszugeben und verschiedene Sprachen zu verarbeiten. Es ist langsamer und erzeugt bei der Verwendung von Unicode-Schriftarten größere Dateien als Originalskripte wie HTML2FPDF, unterstützt aber CSS-Stile usw. und verfügt über viele Verbesserungen. Unterstützt fast alle Sprachen, einschließlich RTL (Arabisch und Hebräisch) und CJK (Chinesisch, Japanisch und Koreanisch). Unterstützt verschachtelte Elemente auf Blockebene (wie P, DIV),

SAP NetWeaver Server-Adapter für Eclipse
Integrieren Sie Eclipse mit dem SAP NetWeaver-Anwendungsserver.

WebStorm-Mac-Version
Nützliche JavaScript-Entwicklungstools

MinGW – Minimalistisches GNU für Windows
Dieses Projekt wird derzeit auf osdn.net/projects/mingw migriert. Sie können uns dort weiterhin folgen. MinGW: Eine native Windows-Portierung der GNU Compiler Collection (GCC), frei verteilbare Importbibliotheken und Header-Dateien zum Erstellen nativer Windows-Anwendungen, einschließlich Erweiterungen der MSVC-Laufzeit zur Unterstützung der C99-Funktionalität. Die gesamte MinGW-Software kann auf 64-Bit-Windows-Plattformen ausgeführt werden.

VSCode Windows 64-Bit-Download
Ein kostenloser und leistungsstarker IDE-Editor von Microsoft

