
Heim >Backend-Entwicklung >Python-Tutorial >Eine Zeile Python-Code, um Parallelität zu erreichen
Eine Zeile Python-Code, um Parallelität zu erreichen

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-12 19:04:291010Durchsuche

Python ist etwas berüchtigt für die Programmparallelisierung. Abgesehen von technischen Problemen wie der Thread-Implementierung und der GIL bin ich der Meinung, dass eine falsche Unterrichtsanleitung das Hauptproblem ist. Gängige klassische Python-Multithreading- und Multiprozess-Tutorials sind in der Regel „schwer“. Und es kratzt oft an der Oberfläche, ohne sich mit den nützlichsten Inhalten der täglichen Arbeit zu befassen.
Traditionelle Beispiele
Einfache Suche nach „Python-Multithreading-Tutorial“, es ist nicht schwer zu finden, dass fast alle Tutorials Beispiele für Klassen und Warteschlangen enthalten:
import os
import PIL
from multiprocessing import Pool
from PIL import Image
SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs'
def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f)
def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path)
if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY))
images = get_image_paths(folder)
pool = Pool()
pool.map(creat_thumbnail, images)
pool.close()
pool.join()
Ha, schau mal Es sieht ein bisschen wie Java aus, nicht wahr?
Ich sage nicht, dass die Verwendung des Producer/Consumer-Modells für Multithread-/Multiprozessaufgaben falsch ist (tatsächlich hat dieses Modell seine Berechtigung). Bei der Bewältigung täglicher Skriptaufgaben können wir jedoch ein effizienteres Modell verwenden.
Das Problem ist...
Erstens benötigen Sie eine Boilerplate-Klasse; Kanal zur Unterstützung der Arbeit (wenn Sie eine bidirektionale Kommunikation durchführen oder Ergebnisse speichern müssen, müssen Sie eine weitere Warteschlange einführen).
Je mehr Worker, desto mehr Probleme
Dieser Idee folgend benötigen Sie nun einen Thread-Pool von Worker-Threads. Das Folgende ist ein Beispiel aus einem klassischen IBM-Tutorial – Beschleunigung durch Multithreading beim Abrufen von Webseiten.#Example2.py
'''
A more realistic thread pool example
'''
import time
import threading
import Queue
import urllib2
class Consumer(threading.Thread):
def __init__(self, queue):
threading.Thread.__init__(self)
self._queue = queue
def run(self):
while True:
content = self._queue.get()
if isinstance(content, str) and content == 'quit':
break
response = urllib2.urlopen(content)
print 'Bye byes!'
def Producer():
urls = [
'http://www.python.org', 'http://www.yahoo.com'
'http://www.scala.org', 'http://www.google.com'
# etc..
]
queue = Queue.Queue()
worker_threads = build_worker_pool(queue, 4)
start_time = time.time()
# Add the urls to process
for url in urls:
queue.put(url)
# Add the poison pillv
for worker in worker_threads:
queue.put('quit')
for worker in worker_threads:
worker.join()
print 'Done! Time taken: {}'.format(time.time() - start_time)
def build_worker_pool(queue, size):
workers = []
for _ in range(size):
worker = Consumer(queue)
worker.start()
workers.append(worker)
return workers
if __name__ == '__main__':
Producer()
Bisher haben wir uns das klassische Multithreading-Tutorial angesehen, das etwas leer ist, nicht wahr? Dieser abgedroschene und fehleranfällige Stil, mit halbem Aufwand das doppelte Ergebnis zu erzielen, ist offensichtlich nicht alltagstauglich. Glücklicherweise haben wir einen besseren Weg.
Warum probieren Sie nicht Map aus?
map Diese kleine und exquisite Funktion ist der Schlüssel zur einfachen Parallelisierung von Python-Programmen. Map stammt aus funktionalen Programmiersprachen wie Lisp. Es kann eine Zuordnung zwischen zwei Funktionen durch eine Sequenz erreichen. urls = ['http://www.yahoo.com', 'http://www.reddit.com']
results = map(urllib2.urlopen, urls)
results = []
for url in urls:
results.append(urllib2.urlopen(url))
Warum ist das wichtig? Dies liegt daran, dass Kartenoperationen mit den richtigen Bibliotheken problemlos parallelisiert werden können.
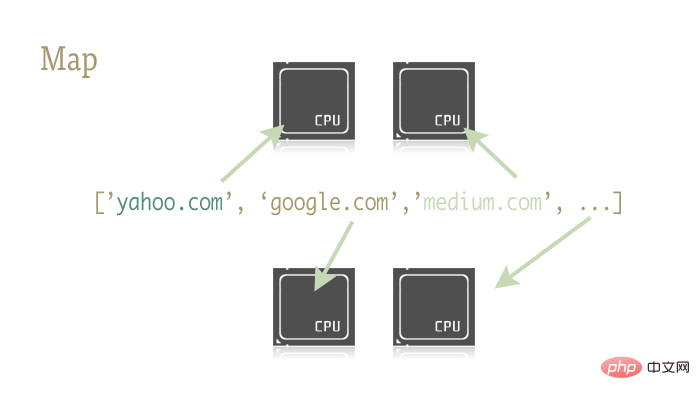
Noch ein paar Sätze hier: multiprocessing.dummy? Thread-Klon der mltiprocessing-Bibliothek? Ist das eine Garnele? Selbst in der offiziellen Dokumentation der Multiprocessing-Bibliothek gibt es nur eine relevante Beschreibung zu dieser Unterbibliothek. Und diese in die Erwachsenensprache übersetzte Beschreibung bedeutet im Grunde: „So etwas gibt es, glauben Sie mir, diese Bibliothek wird ernsthaft unterschätzt!“
dummy ist ein vollständiger Klon des Multiprocessing-Moduls. Der einzige Unterschied besteht darin, dass Multiprocessing auf Prozessen funktioniert, während das Dummy-Modul auf Threads funktioniert (und daher alle üblichen Multithreading-Einschränkungen von Python enthält).
Es ist also extrem einfach, diese beiden Bibliotheken zu ersetzen. Sie können verschiedene Bibliotheken für IO-intensive Aufgaben und CPU-intensive Aufgaben auswählen.
Probieren Sie es selbst aus
Verwenden Sie die folgenden zwei Codezeilen, um auf die Bibliothek zu verweisen, die die parallelisierte Kartenfunktion enthält:from multiprocessing import Pool
from multiprocessing.dummy import Pool as ThreadPool
pool = ThreadPool()
Pool-Objekt hat einige Parameter, und ich muss mich hier nur auf seinen ersten Parameter konzentrieren: Prozesse. Dieser Parameter wird verwendet, um die Anzahl der Threads im Thread-Pool festzulegen. Der Standardwert ist die Anzahl der Kerne der CPU der aktuellen Maschine.
Generell gilt: Bei CPU-intensiven Aufgaben gilt: Je mehr Kerne aufgerufen werden, desto schneller. Bei netzwerkintensiven Aufgaben können die Dinge jedoch etwas unvorhersehbar sein, und es ist ratsam, zu experimentieren, um die Größe des Thread-Pools zu bestimmen.
pool = ThreadPool(4) # Sets the pool size to 4
线程数过多时,切换线程所消耗的时间甚至会超过实际工作时间。对于不同的工作,通过尝试来找到线程池大小的最优值是个不错的主意。
创建好 Pool 对象后,并行化的程序便呼之欲出了。我们来看看改写后的 example2.py
import urllib2
from multiprocessing.dummy import Pool as ThreadPool
urls = [
'http://www.python.org',
'http://www.python.org/about/',
'http://www.onlamp.com/pub/a/python/2003/04/17/metaclasses.html',
'http://www.python.org/doc/',
'http://www.python.org/download/',
'http://www.python.org/getit/',
'http://www.python.org/community/',
'https://wiki.python.org/moin/',
'http://planet.python.org/',
'https://wiki.python.org/moin/LocalUserGroups',
'http://www.python.org/psf/',
'http://docs.python.org/devguide/',
'http://www.python.org/community/awards/'
# etc..
]
# Make the Pool of workers
pool = ThreadPool(4)
# Open the urls in their own threads
# and return the results
results = pool.map(urllib2.urlopen, urls)
#close the pool and wait for the work to finish
pool.close()
pool.join()
实际起作用的代码只有 4 行,其中只有一行是关键的。map 函数轻而易举的取代了前文中超过 40 行的例子。为了更有趣一些,我统计了不同方法、不同线程池大小的耗时情况。
# results = [] # for url in urls: # result = urllib2.urlopen(url) # results.append(result) # # ------- VERSUS ------- # # # ------- 4 Pool ------- # # pool = ThreadPool(4) # results = pool.map(urllib2.urlopen, urls) # # ------- 8 Pool ------- # # pool = ThreadPool(8) # results = pool.map(urllib2.urlopen, urls) # # ------- 13 Pool ------- # # pool = ThreadPool(13) # results = pool.map(urllib2.urlopen, urls)
结果:
# Single thread: 14.4 Seconds # 4 Pool: 3.1 Seconds # 8 Pool: 1.4 Seconds # 13 Pool: 1.3 Seconds
很棒的结果不是吗?这一结果也说明了为什么要通过实验来确定线程池的大小。在我的机器上当线程池大小大于 9 带来的收益就十分有限了。
另一个真实的例子
生成上千张图片的缩略图
这是一个 CPU 密集型的任务,并且十分适合进行并行化。
基础单进程版本
import os
import PIL
from multiprocessing import Pool
from PIL import Image
SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs'
def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f)
def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path)
if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY))
images = get_image_paths(folder)
for image in images:
create_thumbnail(Image)
上边这段代码的主要工作就是将遍历传入的文件夹中的图片文件,一一生成缩略图,并将这些缩略图保存到特定文件夹中。
这我的机器上,用这一程序处理 6000 张图片需要花费 27.9 秒。
如果我们使用 map 函数来代替 for 循环:
import os
import PIL
from multiprocessing import Pool
from PIL import Image
SIZE = (75,75)
SAVE_DIRECTORY = 'thumbs'
def get_image_paths(folder):
return (os.path.join(folder, f)
for f in os.listdir(folder)
if 'jpeg' in f)
def create_thumbnail(filename):
im = Image.open(filename)
im.thumbnail(SIZE, Image.ANTIALIAS)
base, fname = os.path.split(filename)
save_path = os.path.join(base, SAVE_DIRECTORY, fname)
im.save(save_path)
if __name__ == '__main__':
folder = os.path.abspath(
'11_18_2013_R000_IQM_Big_Sur_Mon__e10d1958e7b766c3e840')
os.mkdir(os.path.join(folder, SAVE_DIRECTORY))
images = get_image_paths(folder)
pool = Pool()
pool.map(creat_thumbnail, images)
pool.close()
pool.join()
5.6 秒!
虽然只改动了几行代码,我们却明显提高了程序的执行速度。在生产环境中,我们可以为 CPU 密集型任务和 IO 密集型任务分别选择多进程和多线程库来进一步提高执行速度——这也是解决死锁问题的良方。此外,由于 map 函数并不支持手动线程管理,反而使得相关的 debug 工作也变得异常简单。
到这里,我们就实现了(基本)通过一行 Python 实现并行化。
译者:caspar
译文:https://www.php.cn/link/687fe34a901a03abed262a62e22f90dbm/a/1190000000414339
原文:https://medium.com/building-things-on-the-internet/40e9b2b36148
Das obige ist der detaillierte Inhalt vonEine Zeile Python-Code, um Parallelität zu erreichen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!