
Heim >Backend-Entwicklung >Python-Tutorial >Einfache und benutzerfreundliche parallele Beschleunigungstechniken in Python
Einfache und benutzerfreundliche parallele Beschleunigungstechniken in Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBnach vorne
- 2023-04-12 14:25:151733Durchsuche
1. Einführung

Wenn wir Python täglich zur Ausführung verschiedener Datenberechnungs- und -verarbeitungsaufgaben verwenden und offensichtliche Berechnungsbeschleunigungseffekte erzielen möchten, besteht der einfachste und klarste Weg darin, eine Möglichkeit zu finden, die Aufgaben auf einer einzelnen Ebene auszuführen Standardmäßiger Prozess, erweitert um die Verwendung von Multiprozess- oder Multithread-Ausführung.
Für diejenigen von uns, die sich mit Datenanalyse beschäftigen, ist es besonders wichtig, gleichwertige Beschleunigungsoperationen auf einfachste Weise zu erreichen, um nicht zu viel Zeit mit dem Schreiben von Programmen zu verbringen. Im heutigen Artikel, Herr Fei, werde ich Ihnen beibringen, wie Sie die relevanten Funktionen in joblib, einer sehr einfachen und benutzerfreundlichen Bibliothek, verwenden, um schnell parallele Rechenbeschleunigungseffekte zu erzielen.
2. Joblib für paralleles Rechnen verwenden
Als weit verbreitete Python-Bibliothek eines Drittanbieters (z. B. wird Joblib häufig im Scikit-Learn-Projektframework zur parallelen Beschleunigung vieler Algorithmen für maschinelles Lernen verwendet). Verwenden Sie pip install joblib, um es zu installieren. Nachdem die Installation abgeschlossen ist, lernen wir die gängigen Methoden des parallelen Rechnens in joblib kennen:
2.1 Verwenden Sie Parallel und verzögert für die parallele Beschleunigung.
Um paralleles Rechnen in joblib zu erreichen, müssen Sie nur dessen verwenden Parallel und verzögert Diese Methode ist sehr einfach und bequem zu verwenden. Lassen Sie es uns direkt anhand eines kleinen Beispiels demonstrieren:
Die Idee von joblib zur Implementierung paralleler Berechnungen besteht darin, eine Reihe serieller Rechenunteraufgaben zu kombinieren, die durch Schleifen in einem generiert werden Zeitplan für mehrere Prozesse oder Multithreads, und alles, was wir für benutzerdefinierte Computeraufgaben tun müssen, ist, sie in Form von Funktionen zu kapseln, zum Beispiel:
import time def task_demo1(): time.sleep(1) return time.time()
Dann müssen wir nur noch die relevanten Parameter für Parallel() festlegen. Wie das folgende Formular und connect Schleifen Sie den Listenableitungsprozess zum Erstellen von Unteraufgaben, bei dem verzögert () zum Umschließen der benutzerdefinierten Aufgabenfunktion verwendet wird und dann connect () zum Übergeben der für die Aufgabenfunktion erforderlichen Parameter verwendet wird um die Anzahl der Arbeiter festzulegen, die gleichzeitig parallele Aufgaben ausführen sollen. In diesem Beispiel können Sie sehen, dass sich der Fortschrittsbalken in Gruppen von 4 erhöht, und Sie können sehen, dass der endgültige Zeitaufwand auch den parallelen Beschleunigungseffekt erzielt:
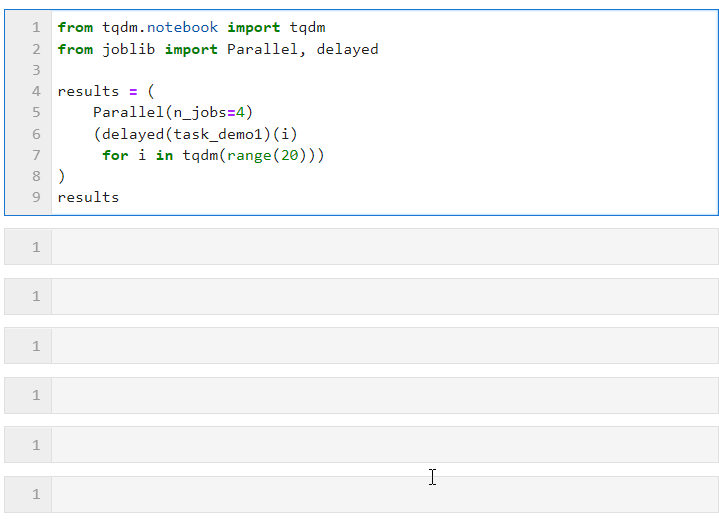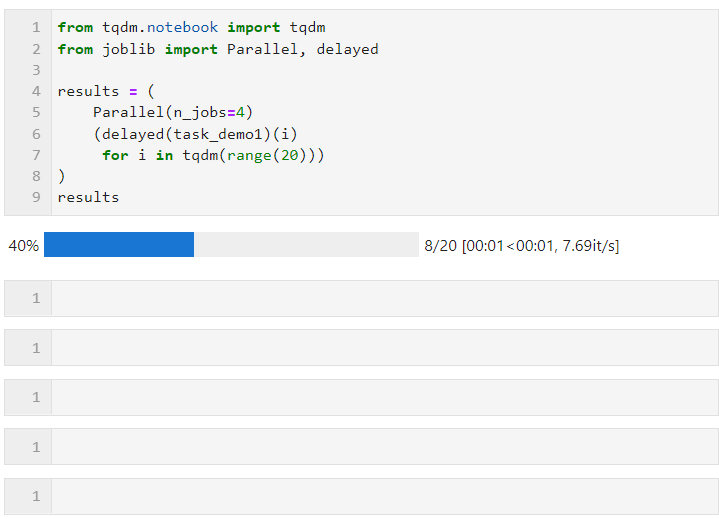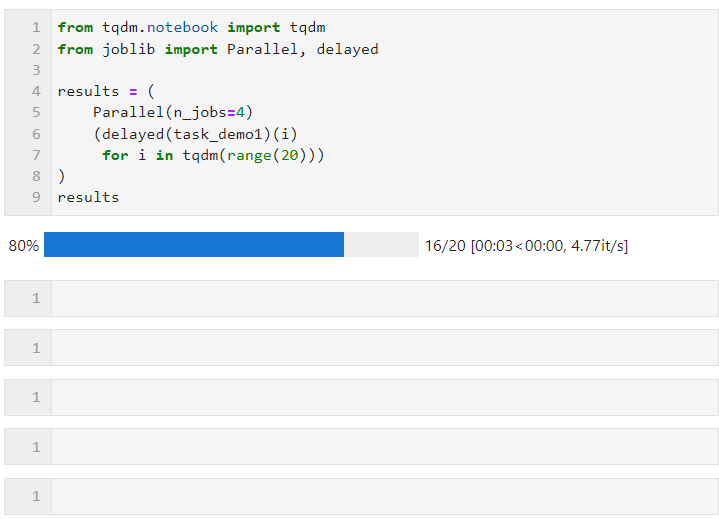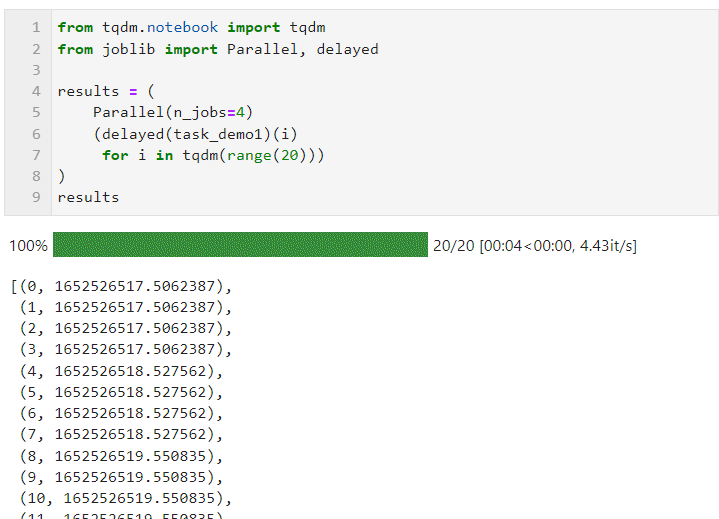
Die spezifische Situation kann parallel sein (je nach Rechenaufgabe und Anzahl der CPU-Kerne). Die Kernparameter sind:
- Backend: wird zum Einstellen des Parallelmodus verwendet -Process-Modus verfügt über zwei Optionen: „loky“ (stabiler) und „Multiprocessing“, und der Multithreading-Modus verfügt über „Threading“. Der Standardwert ist „loky“.
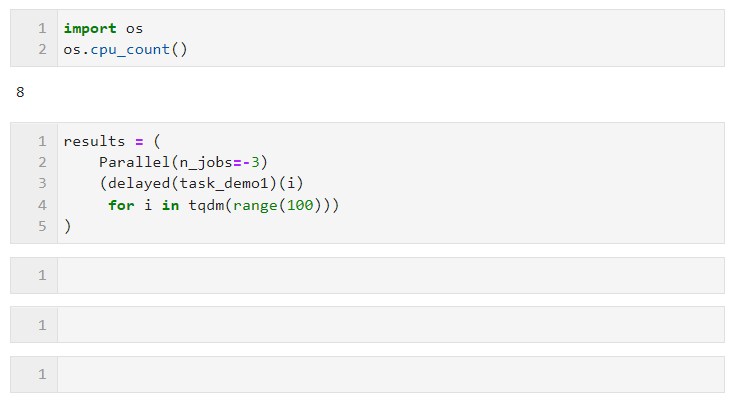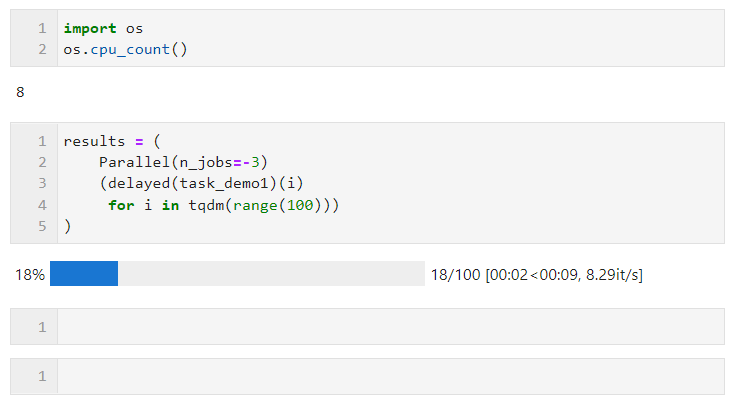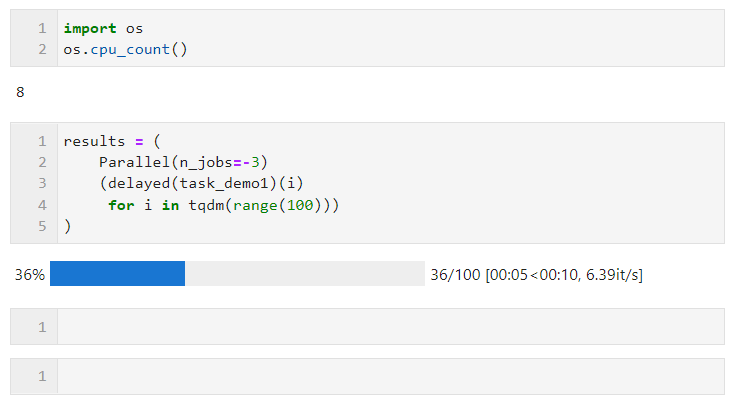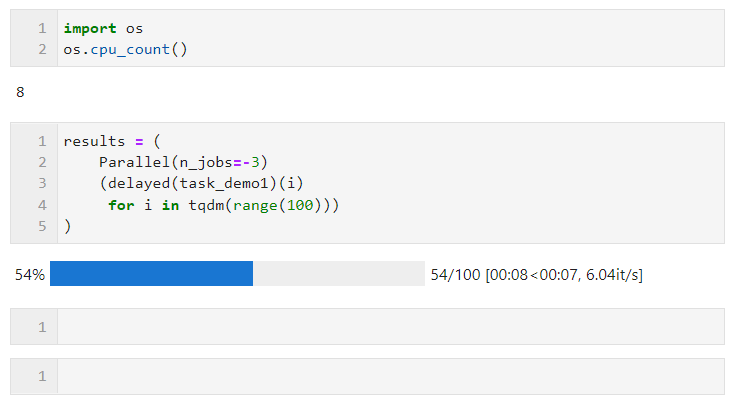
- n_jobs: Wird verwendet, um die Anzahl der Arbeiter festzulegen, die parallele Aufgaben gleichzeitig ausführen sollen. Wenn der Parallelmodus mehrere Prozesse umfasst, können n_jobs auf die Anzahl der logischen Kerne der CPU der Maschine eingestellt werden Die Zahl entspricht dem Einschalten aller Kerne. Sie können sie auch auf -1 setzen, um alle logischen Kerne schnell zu aktivieren. Wenn Sie nicht möchten, dass alle CPU-Ressourcen durch parallele Aufgaben belegt werden, können Sie eine kleinere negative Zahl festlegen Behalten Sie die entsprechenden inaktiven Kerne bei. Stellen Sie ihn beispielsweise auf -2 ein, um alle Kerne zu aktivieren. -1 Kern Setzen Sie ihn auf -3, um alle Kerne zu aktivieren - 2 Kerne.
Im folgenden Beispiel sind beispielsweise auf meiner Maschine mit 8 logischen Kernen zwei Kerne für die parallele Berechnung reserviert:
Bezüglich der Wahl der parallelen Methode, aufgrund des globalen Interpreters im Multithreading in Python Sperrbeschränkungen: Wenn Ihre Aufgabe rechenintensiv ist, wird empfohlen, die Standard-Mehrprozessmethode zur Beschleunigung zu verwenden. Wenn Ihre Aufgabe E/A-intensiv ist, wie z. B. das Lesen und Schreiben von Dateien, Netzwerkanforderungen usw., ist Multithreading besser Weise und kann n_jobs auf einen großen Wert setzen. Als einfaches Beispiel können Sie sehen, dass wir durch Multi-Thread-Parallelität 1.000 Anfragen in 5 Sekunden abgeschlossen haben, was viel schneller ist als die Single-Threaded-Anfrage in 17 Sekunden für 100 Anfragen (dieses Beispiel). Nur als Referenz, bitte besuchen Sie beim Lernen und Ausprobieren nicht zu häufig die Websites anderer Personen):
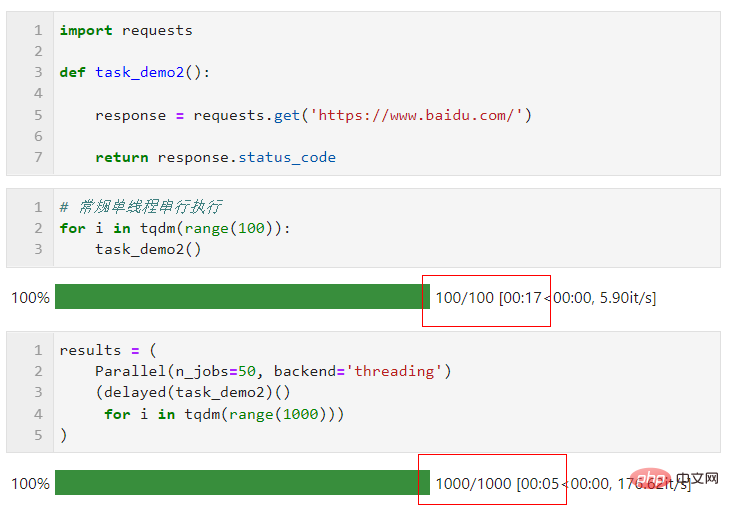
Sie können joblib sinnvoll nutzen, um Ihre tägliche Arbeit entsprechend Ihren tatsächlichen Aufgaben zu beschleunigen.
Das obige ist der detaillierte Inhalt vonEinfache und benutzerfreundliche parallele Beschleunigungstechniken in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!