

 Technologie-PeripheriegeräteKIInterpretation von CRISP-ML(Q): Lebenszyklusprozess des maschinellen Lernens
Technologie-PeripheriegeräteKIInterpretation von CRISP-ML(Q): Lebenszyklusprozess des maschinellen LernensInterpretation von CRISP-ML(Q): Lebenszyklusprozess des maschinellen Lernens

Übersetzer |. Bugatti
Rezensent |. Derzeit gibt es keine Standardpraktiken für die Erstellung und Verwaltung von Anwendungen für maschinelles Lernen (ML). Projekte für maschinelles Lernen sind schlecht organisiert, nicht wiederholbar und scheitern auf lange Sicht tendenziell. Daher benötigen wir einen Prozess, der uns dabei hilft, Qualität, Nachhaltigkeit, Robustheit und Kostenmanagement während des gesamten Lebenszyklus des maschinellen Lernens aufrechtzuerhalten. Abbildung 1: Lebenszyklusprozess der maschinellen Lernentwicklung Lernen von Produktqualität.
CRISP-ML (Q) besteht aus sechs separaten Phasen:
1. Datenvorbereitung 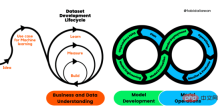
Abbildung 2. Qualitätssicherung in jeder Phase
Qualitätssicherungsmethoden werden in jeder Phase des Frameworks eingeführt. Dieser Ansatz hat Anforderungen und Einschränkungen, wie z. B. Leistungsmetriken, Datenqualitätsanforderungen und Robustheit. Es trägt dazu bei, Risiken zu reduzieren, die den Erfolg von Anwendungen für maschinelles Lernen beeinträchtigen. Dies kann durch kontinuierliche Überwachung und Wartung des gesamten Systems erreicht werden.
Zum Beispiel: In E-Commerce-Unternehmen führen Daten- und Konzeptabweichungen zu einer Modellverschlechterung. Wenn wir keine Systeme zur Überwachung dieser Änderungen einsetzen, wird das Unternehmen Verluste erleiden, d. h. Kunden verlieren.
Geschäfts- und Datenverständnis
Zu Beginn des Entwicklungsprozesses müssen wir den Projektumfang, die Erfolgskriterien und die Machbarkeit der ML-Anwendung bestimmen. Danach begannen wir mit der Datenerfassung und Qualitätsüberprüfung. Der Prozess ist langwierig und herausfordernd.
Umfang:Was wir durch den Einsatz eines maschinellen Lernprozesses erreichen wollen. Geht es darum, Kunden zu binden oder die Betriebskosten durch Automatisierung zu senken? 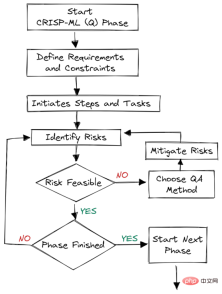
Erfolgskriterien:
Wir müssen klare und messbare geschäftliche, maschinelle Lern- (statistische Indikatoren) und wirtschaftliche (KPI) Erfolgsindikatoren definieren.Machbarkeit:
Wir müssen Datenverfügbarkeit, Eignung für maschinelle Lernanwendungen, rechtliche Einschränkungen, Robustheit, Skalierbarkeit, Interpretierbarkeit und Ressourcenanforderungen sicherstellen.Datenerfassung:
Ermöglichen Sie die Reproduzierbarkeit, indem Sie Daten sammeln, diese versionieren und einen konstanten Fluss realer und generierter Daten sicherstellen.Überprüfung der Datenqualität:
Stellen Sie die Qualität sicher, indem Sie Datenbeschreibungen, Anforderungen und Validierungen pflegen.Um Qualität und Reproduzierbarkeit sicherzustellen, müssen wir die statistischen Eigenschaften der Daten und den Datengenerierungsprozess aufzeichnen.
DatenvorbereitungDer zweite Schritt ist sehr einfach. Wir bereiten die Daten für die Modellierungsphase vor. Dazu gehören Datenauswahl, Datenbereinigung, Feature-Engineering, Datenverbesserung und -normalisierung.
1. Wir beginnen mit der Funktionsauswahl, der Datenauswahl und dem Umgang mit unausgeglichenen Klassen durch Überabtastung oder Unterabtastung.2. Konzentrieren Sie sich dann auf die Reduzierung von Rauschen und den Umgang mit fehlenden Werten. Zur Qualitätssicherung werden wir Dateneinheitstests hinzufügen, um fehlerhafte Werte zu reduzieren.
3. Je nach Modell führen wir Feature Engineering und Datenerweiterung wie One-Hot-Encoding und Clustering durch.4. Daten normalisieren und erweitern. Dadurch wird das Risiko verzerrter Merkmale verringert.
Um die Reproduzierbarkeit sicherzustellen, haben wir Datenmodellierungs-, Transformations- und Feature-Engineering-Pipelines erstellt. ModellentwicklungDie Einschränkungen und Anforderungen der Geschäfts- und Datenverständnisphase bestimmen die Modellierungsphase. Wir müssen die Geschäftsprobleme verstehen und wissen, wie wir Modelle für maschinelles Lernen entwickeln, um sie zu lösen. Wir werden uns auf die Modellauswahl, -optimierung und -schulung konzentrieren, um Modellleistungsmetriken, Robustheit, Skalierbarkeit, Interpretierbarkeit sowie die Optimierung von Speicher- und Rechenressourcen sicherzustellen. 1. Forschung zu Modellarchitektur und ähnlichen Geschäftsproblemen. 2. Definieren Sie Modellleistungsindikatoren. 3. Modellauswahl. 4. Fachwissen durch Einbindung von Experten verstehen. 5. Modeltraining. 6. Modellkomprimierung und -integration. Um Qualität und Reproduzierbarkeit sicherzustellen, speichern und versionieren wir Modellmetadaten, wie z. B. Modellarchitektur, Trainings- und Validierungsdaten, Hyperparameter und Umgebungsbeschreibungen. Abschließend werden wir ML-Experimente verfolgen und ML-Pipelines erstellen, um wiederholbare Trainingsprozesse zu erstellen. ModellbewertungIn dieser Phase testen wir das Modell und stellen sicher, dass es für den Einsatz bereit ist.- Wir testen die Modellleistung anhand des Testdatensatzes.
- Bewerten Sie die Robustheit des Modells, indem Sie zufällige oder gefälschte Daten bereitstellen.
- Verbessern Sie die Interpretierbarkeit des Modells, um regulatorische Anforderungen zu erfüllen.
- Vergleichen Sie die Ergebnisse automatisch oder mit Domänenexperten mit ersten Erfolgskennzahlen.
Jeder Schritt der Beurteilungsphase wird zur Qualitätssicherung protokolliert.
Modellbereitstellung
Die Modellbereitstellung ist die Phase, in der wir Modelle für maschinelles Lernen in bestehende Systeme integrieren. Das Modell kann auf Servern, Browsern, Software und Edge-Geräten bereitgestellt werden. Vorhersagen aus dem Modell sind in BI-Dashboards, APIs, Webanwendungen und Plug-ins verfügbar.
Modellbereitstellungsprozess:
- Definieren Sie Hardware-Inferenz.
- Modellbewertung in der Produktionsumgebung.
- Stellen Sie die Benutzerakzeptanz und Benutzerfreundlichkeit sicher.
- Stellen Sie Backup-Pläne bereit, um Verluste zu minimieren.
- Bereitstellungsstrategie.
Überwachung und Wartung
Modelle in Produktionsumgebungen erfordern eine kontinuierliche Überwachung und Wartung. Wir überwachen die Aktualität des Modells, die Hardwareleistung und die Softwareleistung.
Kontinuierliche Überwachung ist der erste Teil des Prozesses; wenn die Leistung unter einen Schwellenwert fällt, wird automatisch entschieden, das Modell anhand neuer Daten neu zu trainieren. Darüber hinaus beschränkt sich der Wartungsteil nicht nur auf die Umschulung des Modells. Es erfordert Entscheidungsmechanismen, die Erfassung neuer Daten, die Aktualisierung von Software und Hardware sowie die Verbesserung von ML-Prozessen auf der Grundlage von Geschäftsanwendungsfällen.
Kurz gesagt handelt es sich um die kontinuierliche Integration, Schulung und Bereitstellung von ML-Modellen.
Fazit
Das Training und die Validierung von Modellen ist ein kleiner Teil von ML-Anwendungen. Um eine erste Idee in die Realität umzusetzen, sind mehrere Prozesse erforderlich. In diesem Artikel stellen wir CRISP-ML(Q) vor und wie es sich auf Risikobewertung und Qualitätssicherung konzentriert.
Wir definieren zunächst die Geschäftsziele, sammeln und bereinigen Daten, erstellen das Modell, verifizieren das Modell mit Testdatensätzen und stellen es dann in der Produktionsumgebung bereit.
Die Schlüsselkomponenten dieses Frameworks sind die kontinuierliche Überwachung und Wartung. Wir überwachen Daten sowie Software- und Hardware-Metriken, um zu entscheiden, ob das Modell neu trainiert oder das System aktualisiert werden soll.
Wenn Sie neu im Bereich maschineller Lernvorgänge sind und mehr erfahren möchten, lesen Sie den kostenlosen MLOps-Kurs, der von DataTalks.Club geprüft wurde. In allen sechs Phasen sammeln Sie praktische Erfahrungen und verstehen die praktische Umsetzung von CRISP-ML.
Originaltitel: Making Sense of CRISP-ML(Q): The Machine Learning Lifecycle Process, Autor: Abid Ali Awan
Das obige ist der detaillierte Inhalt vonInterpretation von CRISP-ML(Q): Lebenszyklusprozess des maschinellen Lernens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Eine Eingabeaufforderung kann die Schutzmaßnahmen von den großen LLM umgehenApr 25, 2025 am 11:16 AM
Eine Eingabeaufforderung kann die Schutzmaßnahmen von den großen LLM umgehenApr 25, 2025 am 11:16 AMDie bahnbrechende Forschung von HiddenLayer zeigt eine kritische Anfälligkeit in führenden großsprachigen Modellen (LLMs). Ihre Ergebnisse zeigen eine universelle Bypass -Technik, die als "Policy Puppetry" bezeichnet wird und fast alle wichtigen LLMs umgehen können
 5 Fehler, die die meisten Unternehmen dieses Jahr mit Nachhaltigkeit machen werdenApr 25, 2025 am 11:15 AM
5 Fehler, die die meisten Unternehmen dieses Jahr mit Nachhaltigkeit machen werdenApr 25, 2025 am 11:15 AMDer Vorstoß nach Umweltverantwortung und Abfallreduzierung verändert grundlegend die Art und Weise, wie Unternehmen arbeiten. Diese Transformation wirkt sich auf die Produktentwicklung, die Herstellungsprozesse, die Kundenbeziehungen, die Partnerauswahl und die Einführung von Neuen aus
 H20 -Chip -Verbot stürzt China -KI -Firmen, aber sie haben lange auf den Aufprall gefreutApr 25, 2025 am 11:12 AM
H20 -Chip -Verbot stürzt China -KI -Firmen, aber sie haben lange auf den Aufprall gefreutApr 25, 2025 am 11:12 AMDie jüngsten Einschränkungen für fortschrittliche KI -Hardware unterstreichen den eskalierenden geopolitischen Wettbewerb um die Dominanz von AI und zeigen Chinas Vertrauen in ausländische Halbleitertechnologie. Im Jahr 2024 importierte China einen massiven Halbleiter im Wert von 385 Milliarden US -Dollar
 Wenn Openai Chrome kauft, kann AI die Browserkriege regierenApr 25, 2025 am 11:11 AM
Wenn Openai Chrome kauft, kann AI die Browserkriege regierenApr 25, 2025 am 11:11 AMDie potenzielle gezwungene Veräußerung von Chrome von Google hat intensive Debatten in der Tech -Branche in Führung gestellt. Die Aussicht, den führenden Browser mit einem globalen Marktanteil von 65% zu erwerben, wirft erhebliche Fragen zur Zukunft von TH auf
 Wie KI die wachsenden Schmerzen der Einzelhandelsmedien lösen kannApr 25, 2025 am 11:10 AM
Wie KI die wachsenden Schmerzen der Einzelhandelsmedien lösen kannApr 25, 2025 am 11:10 AMDas Wachstum der Einzelhandelsmedien verlangsamt sich, obwohl das Gesamtwachstum des Werbeversorgungswachstums übertrifft. Diese Reifungsphase stellt Herausforderungen dar, einschließlich der Fragmentierung von Ökosystemen, steigenden Kosten, Messproblemen und Integrationskomplexitäten. Künstlicher Intelligen
 'KI sind wir und es ist mehr als wir'Apr 25, 2025 am 11:09 AM
'KI sind wir und es ist mehr als wir'Apr 25, 2025 am 11:09 AMEin altes Radio knistert mit statischer Aufnahme in einer Sammlung flackernder und inerter Bildschirme. Dieser prekäre Elektronikstapel, der leicht destabilisiert ist, bildet den Kern von "The E-Waste Land", einer von sechs Installationen in der immersiven Ausstellung, & Quat
 Google Cloud wird in der nächsten 2025 ernsthafter mit der InfrastrukturApr 25, 2025 am 11:08 AM
Google Cloud wird in der nächsten 2025 ernsthafter mit der InfrastrukturApr 25, 2025 am 11:08 AMGoogle Clouds nächstes 2025: Ein Fokus auf Infrastruktur, Konnektivität und KI Die nächste Konferenz von Google Cloud für 2025 zeigte zahlreiche Fortschritte, die hier zu viele, um sie vollständig ausführlich zu machen. Eine eingehende Analyse spezifischer Ankündigungen finden Sie unter Artikel von My
 Sprechen Baby AI Meme, Arcanas AI -Filmpipeline von 5,5 Millionen US -Dollar, enthüllten IRs geheime UnterstützerApr 25, 2025 am 11:07 AM
Sprechen Baby AI Meme, Arcanas AI -Filmpipeline von 5,5 Millionen US -Dollar, enthüllten IRs geheime UnterstützerApr 25, 2025 am 11:07 AMDiese Woche in AI und XR: Eine Welle der Kreativität von KI-angetriebenen Kreativität führt durch Medien und Unterhaltung, von der Musikgeneration bis zur Filmproduktion. Lassen Sie uns in die Schlagzeilen eintauchen. Wachsende Auswirkungen von AI-generierten Inhalten: Technologieberater Shelly Palme


Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

EditPlus chinesische Crack-Version
Geringe Größe, Syntaxhervorhebung, unterstützt keine Code-Eingabeaufforderungsfunktion

Dreamweaver Mac
Visuelle Webentwicklungstools

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

MantisBT
Mantis ist ein einfach zu implementierendes webbasiertes Tool zur Fehlerverfolgung, das die Fehlerverfolgung von Produkten unterstützen soll. Es erfordert PHP, MySQL und einen Webserver. Schauen Sie sich unsere Demo- und Hosting-Services an.

Dreamweaver CS6
Visuelle Webentwicklungstools

