
Heim >Datenbank >MySQL-Tutorial >Wissenserweiterung: eine selbstausgleichende Methode zur Tabellenaufteilung zur Lösung von Datenverzerrungen
Wissenserweiterung: eine selbstausgleichende Methode zur Tabellenaufteilung zur Lösung von Datenverzerrungen

- 藏色散人nach vorne
- 2023-04-02 06:30:021509Durchsuche
Dieser Artikel vermittelt Ihnen relevantes Wissen über Datentabellen. Er vermittelt Ihnen hauptsächlich eine selbstausgleichende Methode zur Lösung von Datenverzerrungen. Ich hoffe, dass er für alle hilfreich ist.
1. Hintergrund
Dieser Artikel beschreibt hauptsächlich die Anwendungsdatentabelle des B-seitigen Tokens, um das Problem des zunehmenden Geschäftsdatenvolumens und der bestehenden Datenabweichung zu lösen
1) Geschäftshintergrund von B-Token
Lassen Sie uns kurz den Geschäftshintergrund von B-Token beschreiben. Das B-Token-System wird in Marketingszenarien verwendet, um viele Benutzer an einen Token zu binden und dann den Token an Werbung zu binden, um eine Differenzierung zu erreichen und präzises Marketing Im Allgemeinen entspricht der Lebenszyklus eines Tokens dieser Werbung.
2) Die aktuelle Struktur von B-Side-Tokens
Die Beziehung zwischen Tokens und Token-Benutzern ist eine Eins-zu-Viele-Beziehung. Das frühe Token-System verwendete eine JED-Unterbibliothek und zwei Shards. Es wurde eine Erweiterung durchgeführt In der Mitte wurden 8 Shards erreicht und die Anzahl der gespeicherten Datenzeilen erreichte 120 Millionen Die durchschnittliche Zahl beträgt 15 Millionen, aber da das Unterdatenbankfeld die Token-ID (token_uuid) verwendet, gibt es nur wenige Token-Benutzer, nur ein paar Tausend bis Zehntausend, und einige haben viele Token-Benutzer, die zwischen 1 Million und 1,5 Millionen liegen. Die Gesamtzahl der Token ist nicht groß, nur etwa 20.000, daher sind die Daten in einigen Unterdatenbanken verzerrt, in anderen möglicherweise nur in wenigen Millionen. Dies hat zu einem Rückgang geführt bei der Lese- und Schreibleistung der Datenbank. Und da die Datenstruktur der Token-Benutzerbeziehungstabelle sehr einfach ist, nimmt sie trotz vieler Datenzeilen nicht viel Platz ein. Der insgesamt belegte Speicherplatz der 8 Unterdatenbanken beträgt weniger als 20 GB. Gleichzeitig ist der Lebenszyklus von Token im Wesentlichen derselbe wie der von Werbeaktionen. Nachdem ein Token eine oder mehrere Werbeaktionen durchgeführt hat, läuft er langsam ab und wird verworfen, und in Zukunft werden weiterhin neue Token erstellt. So können diese abgelaufenen Token archiviert werden.
Gleichzeitig gibt es aufgrund der Entwicklung des B-Side-Geschäfts mehr Geschäftsanforderungen. Durch die Kommunikation mit dem Unternehmen habe ich erfahren, dass in Zukunft ein automatisches Auswahlsystem eingeführt wird Wählen Sie die für die Beförderung geeigneten Personen aus. Der Zuwachs beträgt etwa 30 Millionen. Bei einer Laufzeit von einem Jahr wird sich das durchschnittliche Datenvolumen einer einzelnen Tabelle auf 60 Millionen erhöhen. Die aktuelle Designarchitektur ist überhaupt nicht in der Lage, die Geschäftsanforderungen zu erfüllen. 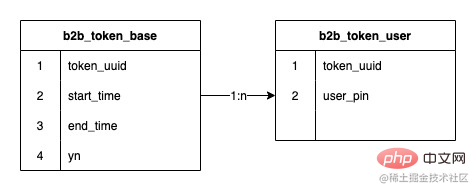
a. Datenbank-Sharding
Vertikale Tabellenaufteilung bezieht sich auf die Aufteilung der Datenspalten und die anschließende Anwendung von Primärschlüsseln oder anderen Geschäftsfeldern zur Zuordnung, wodurch der von einzelnen Tabellendaten belegte Platz reduziert oder redundanter Speicher reduziert wird, was die Datenstruktur des B-Token-Szenarios betrifft einfach und die Daten nehmen wenig Platz ein, daher wird diese Tabellenaufteilungsmethode nicht verwendet.
Horizontales Tabellen-Sharding bezieht sich auf die Aufteilung von Datenzeilen in mehrere Tabellen mithilfe eines Routing-Algorithmus. Die Daten werden beim Lesen auch auf der Grundlage dieses Routing-Algorithmus gelesen. Diese Tabellen-Sharding-Strategie wird im Allgemeinen verwendet, um mit Datenszenarien umzugehen, bei denen die Struktur vorhanden ist nicht komplex, aber es gibt viele Datenzeilen. Das werden wir verwenden. Bei der Verwendung dieser Methode muss berücksichtigt werden, wie der Routing-Algorithmus gestaltet wird. Diese Methode wird hier auch zum Teilen von Tabellen verwendet.
b. Routing-Algorithmus
- In der Branche gibt es viele Möglichkeiten, Datentabellen-Routing-Algorithmen zu verwenden. Eine besteht darin,
Konsistenz-Hash
zu verwenden, um das entsprechende Tabellen-Sharding-Feld auszuwählen, und der Wert wird nach dem Hashing des Feldwerts festgelegt Verwenden Sie diesen Wert, um durch Modulo- oder bitweise Operation eine feste Sequenznummer zu erhalten, um zu bestimmen, in welcher Tabelle die Daten gespeichert sind. Zunächst müssen wir horizontale Untertabellen verwenden, um das Problem zu lösen übermäßiges Datenvolumen in einer einzelnen Tabelle
Muss die Paging-Abfrage von Benutzern auf Basis von Tokens unterstützen
Da der aktuelle Geschäftsdatenzuwachs 30 Millionen beträgt, ist die Möglichkeit eines weiteren Geschäftswachstums in der Zukunft jedoch nicht ausgeschlossen , die Anzahl der Untertabellen muss eine zukünftige Erweiterung unterstützen
Die Anzahl der Datenzeilen ist zu hoch. Es muss sichergestellt werden, dass bei der Erweiterung keine Datenmigration erforderlich ist oder die Datenmigrationskosten niedrig sind Zukunft
Das Problem der Datenverzerrung muss gelöst werden, um sicherzustellen, dass die Gesamtleistung nicht aufgrund des übermäßigen Datenvolumens in einer einzelnen Tabelle beeinträchtigt wird
Die meisten gängigeren Anwendungen wie Unterdatenbanken verwenden konsistentes Hashing. Durch die sofortige Berechnung des Werts des Unterdatenbankfelds wird beurteilt, zu welcher Unterdatenbank die Daten gehören, und dann wird entschieden, in welcher Unterdatenbank die Daten gespeichert werden in die Daten einlesen oder daraus lesen. Wenn das Unterdatenbankfeld während der Abfrage nicht angegeben wird, müssen Abfrageanforderungen gleichzeitig an alle Unterdatenbanken gesendet werden, und schließlich werden die Ergebnisse zusammengefasst.
Darüber hinaus ist die HashMap-Datenstruktur wie Java-Code tatsächlich eine Tabellenpartitionierungsstrategie eines konsistenten Hash-Algorithmus. Durch Hashing des Schlüssels wird entschieden, welche Seriennummer die Daten im Array gespeichert werden Methode, um die Seriennummer zu erhalten, aber diese Methode bestimmt auch, dass die Erweiterung von HashMap auf der Größe 2 hoch x basiert. Ich werde dieses Prinzip in Zukunft einführen.
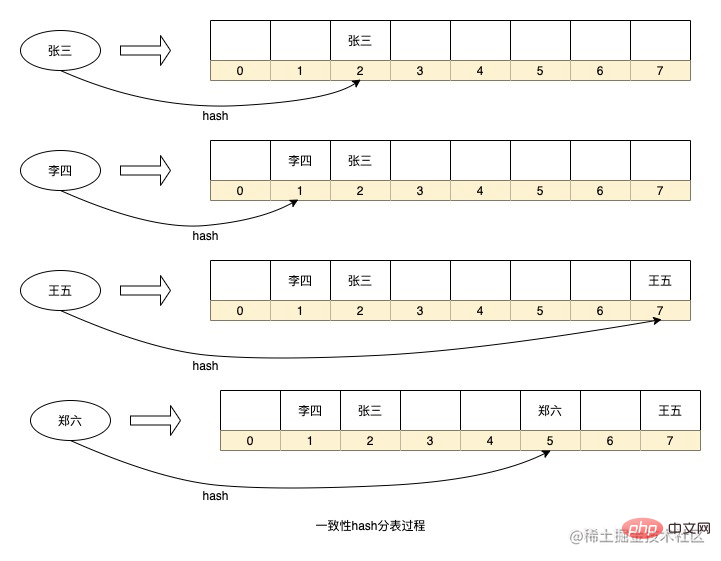
Das Obige ist ein vereinfachter Daten-Hash-Speicherprozess in HashMap. Natürlich habe ich einige Details weggelassen. Beispielsweise ist jeder Knoten in HashMap eine verknüpfte Liste (zu viele Konflikte werden zu einem rot-schwarzen Baum). . Bei der Anwendung in unserem Szenario kann jede Seriennummer als Datentabelle betrachtet werden.
Der Vorteil des oben genannten Routing-Algorithmus besteht darin, dass die Routing-Strategie einfach ist und kein zusätzlicher Speicherplatz für Echtzeitberechnungen hinzugefügt werden muss. Es besteht jedoch auch das Problem, dass Sie die Kapazität erweitern möchten Wenn beispielsweise die Datenbank-Unterdatenbank hinzugefügt wird, muss die HashMap-Erweiterung alle Daten neu berechnen, um die Sequenznummer des Schlüssels im Array neu zu berechnen . Wenn die Datenmenge zu groß ist, dauert dieser Berechnungsvorgang lange. Wenn gleichzeitig zu wenige Datentabellen vorhanden sind oder die für das Sharding ausgewählten Felder eine geringe Diskretion aufweisen, kommt es zu einer Datenverzerrung.
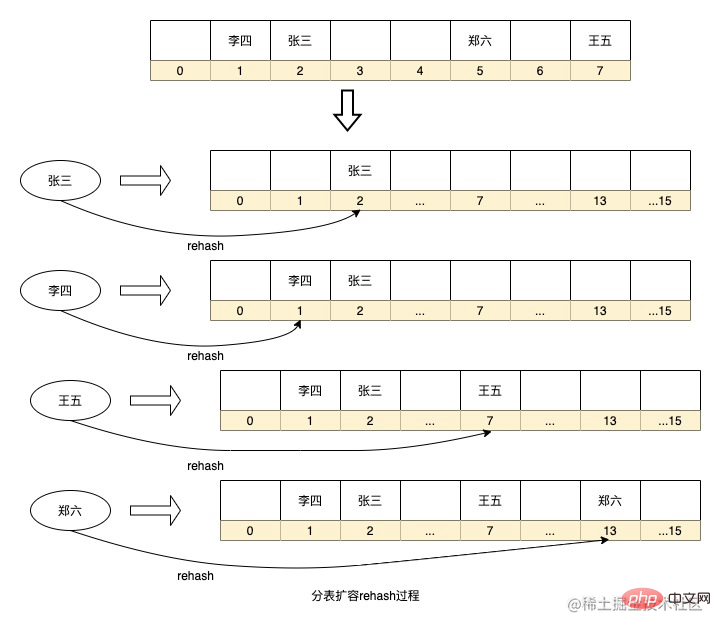
Es gibt auch einen Tabellenaufteilungsalgorithmus, der diesen Rehash-Prozess optimiert. Diese Methode abstrahiert viele virtuelle Knoten zwischen Entitätsknoten und verwendet dann den konsistenten Hash-Algorithmus, um die Daten erneut aufzubereiten Knoten, und jeder Entitätsknoten ist tatsächlich für die Daten der virtuellen Knoten neben dem anderen Entitätsknoten im Gegenuhrzeigersinn des Entitätsknotens verantwortlich. Der Vorteil dieser Methode besteht darin, dass, wenn Sie die Kapazität erweitern und Knoten hinzufügen müssen, der hinzugefügte Knoten an einer beliebigen Stelle im Ring platziert wird und sich nur auf die Daten benachbarter Knoten im Uhrzeigersinn des Knotens auswirkt Die Daten im Knoten müssen migriert werden, um sie einfach auf diesem neuen Knoten zu installieren, was den Aufbereitungsprozess erheblich reduziert. Gleichzeitig können die Daten aufgrund der großen Anzahl virtueller Knoten gleichmäßiger auf dem Ring verteilt werden. Solange die physischen Knoten an der richtigen Stelle platziert sind, kann das Problem der Datenverzerrung weitestgehend gelöst werden.
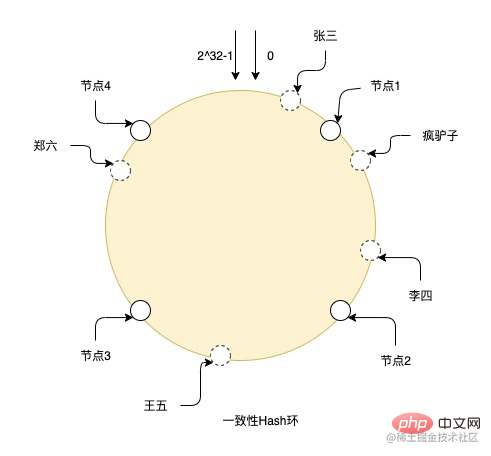
Das Bild zeigt beispielsweise den Hash-Prozess eines konsistenten Hash-Rings. Es gibt Knoten von 0 bis 2^32-1 im gesamten Ring. Die durchgezogenen Linien sind reale Knoten und die anderen sind virtuelle Knoten. Zhang San fällt nach dem Hashing auf den virtuellen Knoten im Ring und sucht dann im Uhrzeigersinn von der Position des virtuellen Knotens aus nach dem realen Knoten. Die endgültigen Daten werden auf dem realen Knoten gespeichert, sodass Crazy Donkey und Li Si gespeichert werden Knoten 2 und Wang Wu befindet sich auf Knoten 3. Zheng Liu befindet sich auf Knoten 4.
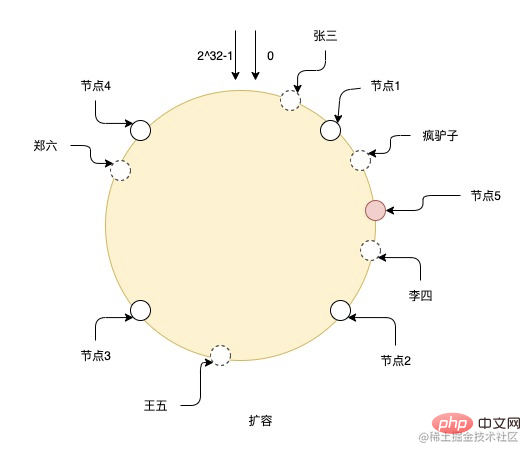
Nach der Erweiterung eines Knotens Nr. 5 müssen die Daten zwischen Knoten 1 und Knoten 5 auf Knoten 5 migriert werden, und die Daten anderer Knoten müssen nicht geändert werden. Wie Sie jedoch in der Abbildung sehen können, kann das Hinzufügen nur dieses einen Knotens leicht zu ungleichmäßigen Daten für die einzelnen Knoten führen. Knoten 2 und Knoten 5 sind beispielsweise für viel weniger Daten verantwortlich als andere Knoten. Daher ist es am besten, sie zu erweitern Damit die Daten weiterhin einheitlich bleiben, ist es am besten, die Kapazität exponentiell zu erweitern.
3) Wenn ich über meinen Plan nachdenke
Zurück zum Geschäftsszenario des B-Tokens: Wir müssen in der Lage sein, die folgenden Anforderungen zu erfüllen:
Auf der Grundlage des oben genannten Einspruchs schauen Sie sich zunächst Frage b an. Wenn Sie Paging-Abfragen von Benutzern basierend auf Token unterstützen möchten, müssen Sie sicherstellen, dass sich alle Benutzer unter dem Token in derselben Tabelle befinden, um Paging-Abfragen einfach zu unterstützen. Andernfalls ist die Verwendung einiger Zusammenfassungs- und Zusammenführungsalgorithmen zu komplex Tabellen verringern die Abfrageleistung. Obwohl die Abfragefunktion auch durch die Verwendung heterogener Daten bereitgestellt werden kann, ist die Datenheterogenität nur für eine kleine Anzahl verwaltungsseitiger Abfrageanforderungen erforderlich. Die Kosten sind etwas hoch, aber die Vorteile liegen nicht auf der Hand, und es ist auch eine Verschwendung von Ressourcen. Daher kann das Untertabellenfeld nur anhand der Token-ID ermittelt werden.
Wie oben erwähnt, ist die Anzahl der Token-IDs nicht groß und die Anzahl der Benutzer unter den Token reicht von 10.000 bis 1 Million. Die einfache Verwendung von konsistentem Hashing und die Verwendung von Token-IDs als Sharding-Strategie führt zu einer schwerwiegenden Datenverzerrung Die Datenmigrationskosten werden bei zukünftigen Erweiterungen sehr hoch sein.
Allerdings führt die Verwendung eines konsistenten Hash-Rings in Zukunft zu der besten Erweiterung um ein Vielfaches von 2. Andernfalls sind einige Knoten für mehr virtuelle Knoten und einige Knoten für weniger virtuelle Knoten verantwortlich, was zu Ungleichmäßigkeiten führt Daten. Bei der Kommunikation mit Datenbankkollegen sollte die Anzahl der Datentabellen unter einer Datenbank jedoch nicht zu groß sein, da sonst die Datenbank stark belastet wird. Die konsistente Hash-Ring-Methode kann die Kapazität um das Zwei- oder Dreifache erhöhen Anzahl der Untertabellen, um eine zu erreichen. Sehr hoher Wert.
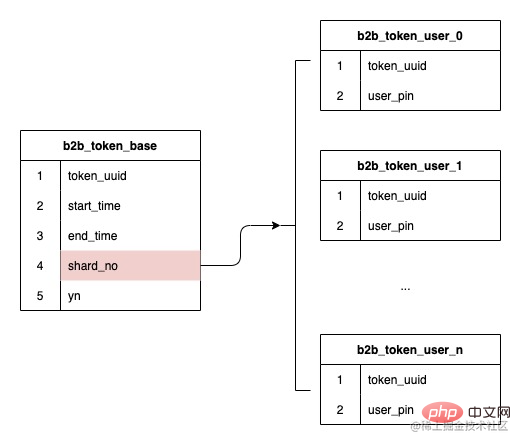
Aufgrund der oben genannten Probleme müssen wir uns nach der Entscheidung, die Token-ID als Untertabelle zu verwenden, darauf konzentrieren, wie wir die dynamische Erweiterung unterstützen und das Problem der Datenschiefe lösen können. 3. Plan-Implementierung , unsere Datenstruktur ist Karten und Benutzer sind Eins-zu-Viele-Relationsdaten, daher wird die beim Erstellen des Tokens gehaschte Untertabellen-Seriennummer gespeichert und das nachfolgende Routing basiert auf der gespeicherten Untertabellen-Seriennummer, wodurch dies sichergestellt werden kann Zukünftige Erweiterungen haben keinen Einfluss auf die Weiterleitung vorhandener Daten, eine Datenmigration ist nicht erforderlich.
b. So lösen Sie Datenversatz
Da die Token-ID als Untertabellenfeld ausgewählt wird und die Datengröße jedes Tokens unterschiedlich ist, stellt der Datenversatz ein großes Problem dar. Deshalb versuchen wir hier, das Konzept des Wasserstands unter einem Meter einzuführen.Wenn der Benutzer das Speichern oder Löschen der Anzahl der zugehörigen Benutzer anfordert, wird die aktuelle Anzahl der Shard-Tabellen basierend auf der Seriennummer der Shard-Tabelle erhöht oder verringert, wenn die Datenmenge in einem bestimmten Shard ansteigt Wenn sich die Tabelle auf einem hohen Niveau befindet, wird die Anzahl der zugehörigen Benutzer gezählt. Die Shard-Tabelle wird aus dem Sharding-Algorithmus entfernt, sodass die Shard-Tabelle keine weiteren neuen Daten generiert.
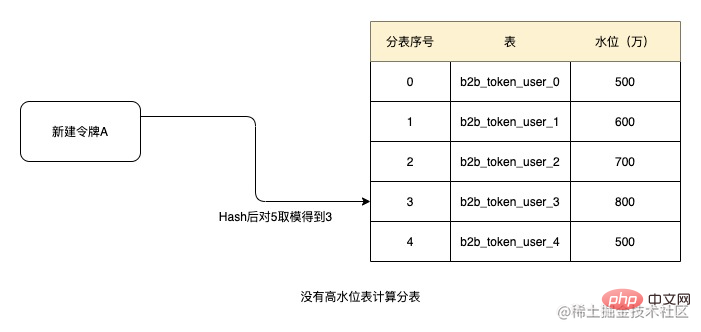
Wenn Sie beispielsweise den Schwellenwert von 10 Millionen als Hochwasserstand festlegen, da keine der oben genannten fünf Tabellen den Hochwasserstand erreicht hat, hashen Sie beim Erstellen des Tokens entsprechend der Token-ID und nehmen Sie dann die Modulo, um 3 zu erhalten und die Tabellen der Reihe nach abzurufen, dann die aktuelle Untertabellennummer des Tokens ist b2b_token_user_3. Nachfolgende relationale Daten werden aus dieser Tabelle abgerufen.
Nach einiger Zeit ist das Datenvolumen der Tabelle b2b_token_user_1 auf 12 Millionen gestiegen und hat den Wasserstand von 10 Millionen überschritten. Zu diesem Zeitpunkt wird die Tabelle beim Erstellen des Tokens entfernt Modulo ist nach Hash 1. Dann ist die aktuell zugewiesene Tabelle b2b_token_user_2. Und wenn der Wasserstand von b2b_token_user_1 nicht gesenkt werden kann, nimmt die Tabelle in Zukunft nicht mehr an Untertabellen teil und die Datenmenge in der Tabelle nimmt nicht zu. Natürlich besteht die Möglichkeit, dass alle Uhren den Hochwasserstand erreicht haben. Aus Sicherheitsgründen wird die Wasserstandsfunktion zu diesem Zeitpunkt deaktiviert und alle Uhren zur Untertabelle hinzugefügt.
Natürlich besteht die Möglichkeit, dass alle Uhren den Hochwasserstand erreicht haben. Aus Sicherheitsgründen wird die Wasserstandsfunktion zu diesem Zeitpunkt deaktiviert und alle Uhren zur Untertabelle hinzugefügt.
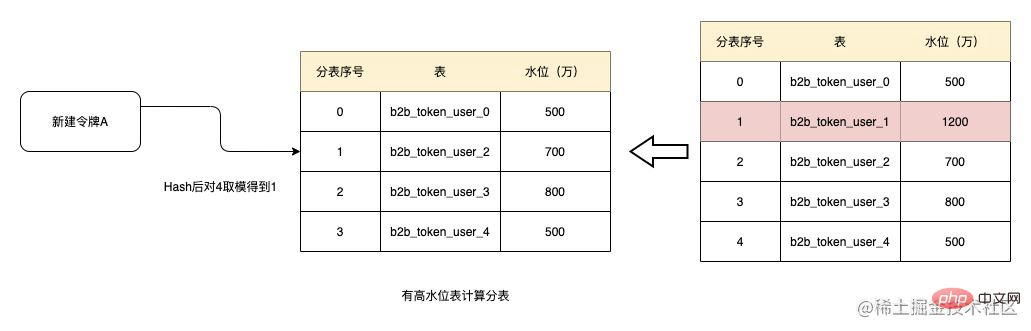
Obwohl die regelmäßige Datenarchivierung den Wasserstand des Tisches senken kann, können die meisten Tische einen hohen Wasserstand erreichen und alle haben einen gültigen Zustand. Zu diesem Zeitpunkt wird das System automatisch erweitert, wenn es feststellt, dass die Kapazität 75 % erreicht. Wir können keine Tabellen automatisch erstellen, aber wenn 75 % der Tabellen den Hochwasserstand erreichen, wird ein Alarm ausgegeben Alarm auslösen und manuell eingreifen. Bei hohem Wasserstand sollte die Tabelle erweitert werden.
3) Mängel
•
Wasserstandsschwellen- und AusdehnungsüberwachungDerzeit wird der Wasserstandsgrenzwert noch manuell eingestellt. Es ist ziemlich emotional, wie hoch er eingestellt werden sollte. Sie können ihn nur nach dem Alarm einstellen und entsprechend anpassen. Tatsächlich kann das System jedoch die Schwankungen der Lese- und Schreibleistung der Schnittstelle automatisch überwachen. Es wurde festgestellt, dass sich die Lese- und Schreibleistung der Schnittstelle nicht wesentlich ändert Erhöhen Sie den Schwellenwert automatisch, um einen intelligenten Schwellenwert zu bilden.
Wenn sich die Lese- und Schreibleistung der Schnittstelle erheblich ändert und festgestellt wird, dass die meisten Tabellen den Schwellenwert erreicht haben, wird ein Alarm ausgegeben, der darauf hinweist, dass eine Kapazitätserweiterung in Betracht gezogen werden sollte.
4. Zusammenfassung
Es gibt nie eine Wunderwaffe, um Probleme zu lösen. Wir müssen die verfügbaren technischen Mittel und Werkzeuge nutzen, um sie an unser aktuelles Geschäft und unsere Szenarien anzupassen. nur geeignet oder nicht.
Das obige ist der detaillierte Inhalt vonWissenserweiterung: eine selbstausgleichende Methode zur Tabellenaufteilung zur Lösung von Datenverzerrungen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
In Verbindung stehende Artikel
Mehr sehen- Was soll ich tun, wenn die Untertabellen unterhalb der Tabelle nicht angezeigt werden?
- Beschreiben Sie im Detail die Untertabellen, Unterdatenbanken, Shards und Partitionen in MySql
- Wann werden Tabellen in MySQL geteilt?
- So implementieren Sie mit PHP die MySQL-Tabellenpartitionierung, um die Abfrageeffizienz zu verbessern